 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlotVTG: Object-Centric Adapter for Generalizable Video Temporal Grounding
Mar 26, 2026Multimodal Large Language Models (MLLMs) have shown strong performance on Video Temporal Grounding (VTG). However, their coarse recognition capabilities are insufficient for fine-grained temporal understanding, making task-specific fine-tuning indispensable. This fine-tuning causes models to memorize dataset-specific shortcuts rather than faithfully grounding in the actual visual content, leading to poor Out-of-Domain (OOD) generalization. Object-centric learning offers a promising remedy by decomposing scenes into entity-level representations, but existing approaches require re-running the entire multi-stage training pipeline from scratch. We propose SlotVTG, a framework that steers MLLMs toward object-centric, input-grounded visual reasoning at minimal cost. SlotVTG introduces a lightweight slot adapter that decomposes visual tokens into abstract slots via slot attention and reconstructs the original sequence, where objectness priors from a self-supervised vision model encourage semantically coherent slot formation. Cross-domain evaluation on standard VTG benchmarks demonstrates that our approach significantly improves OOD robustness while maintaining competitive In-Domain (ID) performance with minimal overhead.
Why Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
Jan 22, 2026We study Compositional Video Understanding (CVU), where models must recognize verbs and objects and compose them to generalize to unseen combinations. We find that existing Zero-Shot Compositional Action Recognition (ZS-CAR) models fail primarily due to an overlooked failure mode: object-driven verb shortcuts. Through systematic analysis, we show that this behavior arises from two intertwined factors: severe sparsity and skewness of compositional supervision, and the asymmetric learning difficulty between verbs and objects. As training progresses, the existing ZS-CAR model increasingly ignores visual evidence and overfits to co-occurrence statistics. Consequently, the existing model does not gain the benefit of compositional recognition in unseen verb-object compositions. To address this, we propose RCORE, a simple and effective framework that enforces temporally grounded verb learning. RCORE introduces (i) a composition-aware augmentation that diversifies verb-object combinations without corrupting motion cues, and (ii) a temporal order regularization loss that penalizes shortcut behaviors by explicitly modeling temporal structure. Across two benchmarks, Sth-com and our newly constructed EK100-com, RCORE significantly improves unseen composition accuracy, reduces reliance on co-occurrence bias, and achieves consistently positive compositional gaps. Our findings reveal object-driven shortcuts as a critical limiting factor in ZS-CAR and demonstrate that addressing them is essential for robust compositional video understanding.
PCEvE: Part Contribution Evaluation Based Model Explanation for Human Figure Drawing Assessment and Beyond
Sep 26, 2024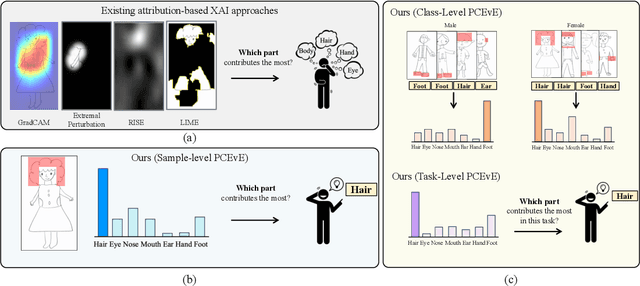
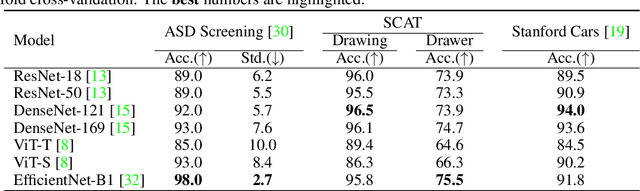
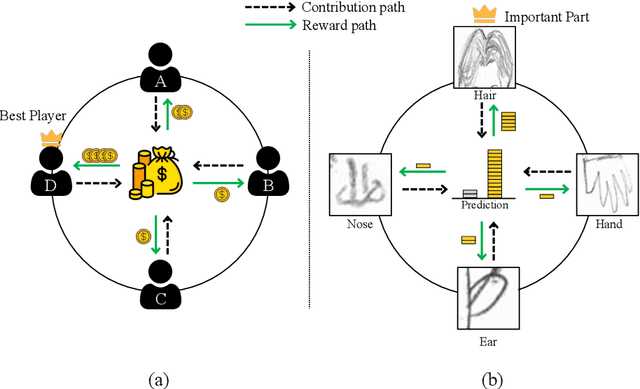
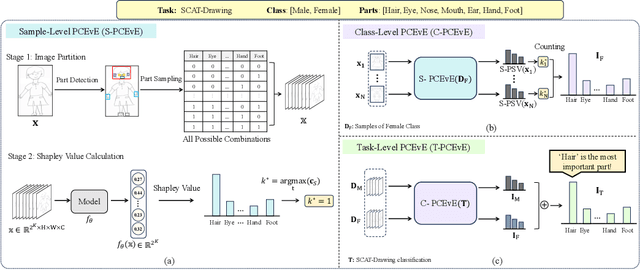
For automatic human figure drawing (HFD) assessment tasks, such as diagnosing autism spectrum disorder (ASD) using HFD images, the clarity and explainability of a model decision are crucial. Existing pixel-level attribution-based explainable AI (XAI) approaches demand considerable effort from users to interpret the semantic information of a region in an image, which can be often time-consuming and impractical. To overcome this challenge, we propose a part contribution evaluation based model explanation (PCEvE) framework. On top of the part detection, we measure the Shapley Value of each individual part to evaluate the contribution to a model decision. Unlike existing attribution-based XAI approaches, the PCEvE provides a straightforward explanation of a model decision, i.e., a part contribution histogram. Furthermore, the PCEvE expands the scope of explanations beyond the conventional sample-level to include class-level and task-level insights, offering a richer, more comprehensive understanding of model behavior. We rigorously validate the PCEvE via extensive experiments on multiple HFD assessment datasets. Also, we sanity-check the proposed method with a set of controlled experiments. Additionally, we demonstrate the versatility and applicability of our method to other domains by applying it to a photo-realistic dataset, the Stanford Cars.
DEVIAS: Learning Disentangled Video Representations of Action and Scene for Holistic Video Understanding
Nov 30, 2023When watching a video, humans can naturally extract human actions from the surrounding scene context, even when action-scene combinations are unusual. However, unlike humans, video action recognition models often learn scene-biased action representations from the spurious correlation in training data, leading to poor performance in out-of-context scenarios. While scene-debiased models achieve improved performance in out-of-context scenarios, they often overlook valuable scene information in the data. Addressing this challenge, we propose Disentangled VIdeo representations of Action and Scene (DEVIAS), which aims to achieve holistic video understanding. Disentangled action and scene representations with our method could provide flexibility to adjust the emphasis on action or scene information depending on downstream task and dataset characteristics. Disentangled action and scene representations could be beneficial for both in-context and out-of-context video understanding. To this end, we employ slot attention to learn disentangled action and scene representations with a single model, along with auxiliary tasks that further guide slot attention. We validate the proposed method on both in-context datasets: UCF-101 and Kinetics-400, and out-of-context datasets: SCUBA and HAT. Our proposed method shows favorable performance across different datasets compared to the baselines, demonstrating its effectiveness in diverse video understanding scenarios.