 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRANDOM MASK: Towards Robust Convolutional Neural Networks
Paper and Code
Jul 27, 2020

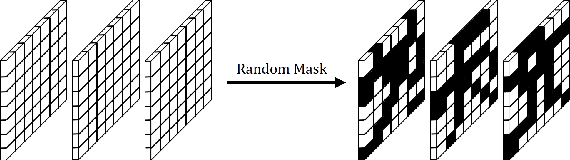

Robustness of neural networks has recently been highlighted by the adversarial examples, i.e., inputs added with well-designed perturbations which are imperceptible to humans but can cause the network to give incorrect outputs. In this paper, we design a new CNN architecture that by itself has good robustness. We introduce a simple but powerful technique, Random Mask, to modify existing CNN structures. We show that CNN with Random Mask achieves state-of-the-art performance against black-box adversarial attacks without applying any adversarial training. We next investigate the adversarial examples which 'fool' a CNN with Random Mask. Surprisingly, we find that these adversarial examples often 'fool' humans as well. This raises fundamental questions on how to define adversarial examples and robustness properly.