 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVOS: Self-Supervised Dense-Pattern Video Object Segmentation
Jun 07, 2024



Video object segmentation approaches primarily rely on large-scale pixel-accurate human-annotated datasets for model development. In Dense Video Object Segmentation (DVOS) scenarios, each video frame encompasses hundreds of small, dense, and partially occluded objects. Accordingly, the labor-intensive manual annotation of even a single frame often takes hours, which hinders the development of DVOS for many applications. Furthermore, in videos with dense patterns, following a large number of objects that move in different directions poses additional challenges. To address these challenges, we proposed a semi-self-supervised spatiotemporal approach for DVOS utilizing a diffusion-based method through multi-task learning. Emulating real videos' optical flow and simulating their motion, we developed a methodology to synthesize computationally annotated videos that can be used for training DVOS models; The model performance was further improved by utilizing weakly labeled (computationally generated but imprecise) data. To demonstrate the utility and efficacy of the proposed approach, we developed DVOS models for wheat head segmentation of handheld and drone-captured videos, capturing wheat crops in fields of different locations across various growth stages, spanning from heading to maturity. Despite using only a few manually annotated video frames, the proposed approach yielded high-performing models, achieving a Dice score of 0.82 when tested on a drone-captured external test set. While we showed the efficacy of the proposed approach for wheat head segmentation, its application can be extended to other crops or DVOS in other domains, such as crowd analysis or microscopic image analysis.
AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers
Sep 23, 2019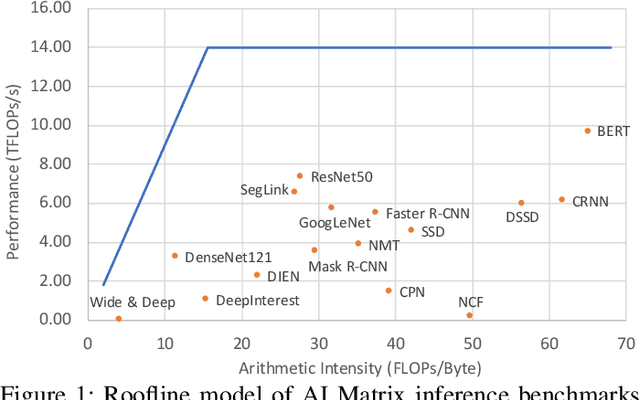
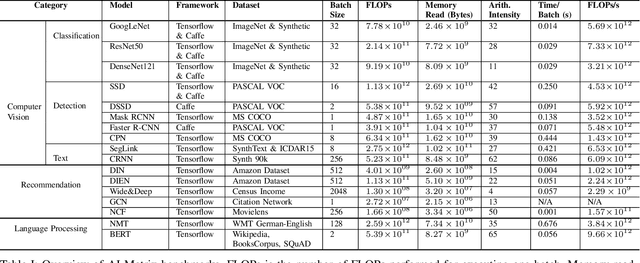
Alibaba has China's largest e-commerce platform. To support its diverse businesses, Alibaba has its own large-scale data centers providing the computing foundation for a wide variety of software applications. Among these applications, deep learning (DL) has been playing an important role in delivering services like image recognition, objection detection, text recognition, recommendation, and language processing. To build more efficient data centers that deliver higher performance for these DL applications, it is important to understand their computational needs and use that information to guide the design of future computing infrastructure. An effective way to achieve this is through benchmarks that can fully represent Alibaba's DL applications.
AI Matrix - Synthetic Benchmarks for DNN
Nov 27, 2018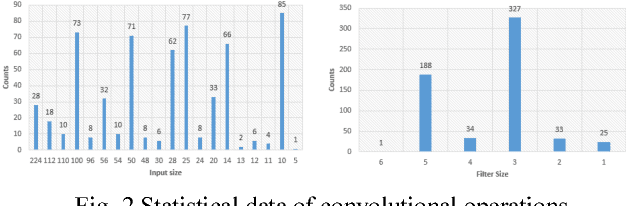
Deep neural network (DNN) architectures, such as convolutional neural networks (CNN), involve heavy computation and require hardware, such as CPU, GPU, and AI accelerators, to provide the massive computing power. With the many varieties of AI hardware prevailing on the market, it is often hard to decide which one is the best to use. Thus, benchmarking AI hardware effectively becomes important and is of great help to select and optimize AI hardware. Unfortunately, there are few AI benchmarks available in both academia and industry. Examples are BenchNN[1], DeepBench[2], and Dawn Bench[3], which are usually a collection of typical real DNN applications. While these benchmarks provide performance comparison across different AI hardware, they suffer from a number of drawbacks. First, they cannot adapt to the emerging changes of DNN algorithms and are fixed once selected. Second, they contain tens to hundreds of applications and take very long time to finish running. Third, they are mainly selected from open sources, which are restricted by copyright and are not representable to proprietary applications. In this work, a synthetic benchmarks framework is firstly proposed to address the above drawbacks of AI benchmarks. Instead of pre-selecting a set of open-sourced benchmarks and running all of them, the synthetic approach generates only a one or few benchmarks that best represent a broad range of applications using profiled workload characteristics data of these applications. Thus, it can adapt to emerging changes of new DNN algorithms by re-profiling new applications and updating itself, greatly reduce benchmark count and running time, and strongly represent DNN applications of interests. The generated benchmarks are called AI Matrix, serving as a performance benchmarks matching the statistical workload characteristics of a combination of applications of interests.