 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRel-UNet: Reliable Tumor Segmentation via Uncertainty Quantification in nnU-Net
Mar 11, 2025



Accurate and reliable tumor segmentation is essential in medical imaging analysis for improving diagnosis, treatment planning, and monitoring. However, existing segmentation models often lack robust mechanisms for quantifying the uncertainty associated with their predictions, which is essential for informed clinical decision-making. This study presents a novel approach for uncertainty quantification in kidney tumor segmentation using deep learning, specifically leveraging multiple local minima during training. Our method generates uncertainty maps without modifying the original model architecture or requiring extensive computational resources. We evaluated our approach on the KiTS23 dataset, where our approach effectively identified ambiguous regions faster and with lower uncertainty scores in contrast to previous approaches. The generated uncertainty maps provide critical insights into model confidence, ultimately enhancing the reliability of the segmentation with the potential to support more accurate medical diagnoses. The computational efficiency and model-agnostic design of the proposed approach allows adaptation without architectural changes, enabling use across various segmentation models.
SynthSet: Generative Diffusion Model for Semantic Segmentation in Precision Agriculture
Nov 05, 2024



This paper introduces a methodology for generating synthetic annotated data to address data scarcity in semantic segmentation tasks within the precision agriculture domain. Utilizing Denoising Diffusion Probabilistic Models (DDPMs) and Generative Adversarial Networks (GANs), we propose a dual diffusion model architecture for synthesizing realistic annotated agricultural data, without any human intervention. We employ super-resolution to enhance the phenotypic characteristics of the synthesized images and their coherence with the corresponding generated masks. We showcase the utility of the proposed method for wheat head segmentation. The high quality of synthesized data underscores the effectiveness of the proposed methodology in generating image-mask pairs. Furthermore, models trained on our generated data exhibit promising performance when tested on an external, diverse dataset of real wheat fields. The results show the efficacy of the proposed methodology for addressing data scarcity for semantic segmentation tasks. Moreover, the proposed approach can be readily adapted for various segmentation tasks in precision agriculture and beyond.
DVOS: Self-Supervised Dense-Pattern Video Object Segmentation
Jun 07, 2024



Video object segmentation approaches primarily rely on large-scale pixel-accurate human-annotated datasets for model development. In Dense Video Object Segmentation (DVOS) scenarios, each video frame encompasses hundreds of small, dense, and partially occluded objects. Accordingly, the labor-intensive manual annotation of even a single frame often takes hours, which hinders the development of DVOS for many applications. Furthermore, in videos with dense patterns, following a large number of objects that move in different directions poses additional challenges. To address these challenges, we proposed a semi-self-supervised spatiotemporal approach for DVOS utilizing a diffusion-based method through multi-task learning. Emulating real videos' optical flow and simulating their motion, we developed a methodology to synthesize computationally annotated videos that can be used for training DVOS models; The model performance was further improved by utilizing weakly labeled (computationally generated but imprecise) data. To demonstrate the utility and efficacy of the proposed approach, we developed DVOS models for wheat head segmentation of handheld and drone-captured videos, capturing wheat crops in fields of different locations across various growth stages, spanning from heading to maturity. Despite using only a few manually annotated video frames, the proposed approach yielded high-performing models, achieving a Dice score of 0.82 when tested on a drone-captured external test set. While we showed the efficacy of the proposed approach for wheat head segmentation, its application can be extended to other crops or DVOS in other domains, such as crowd analysis or microscopic image analysis.
Semi-Self-Supervised Domain Adaptation: Developing Deep Learning Models with Limited Annotated Data for Wheat Head Segmentation
May 12, 2024



Precision agriculture involves the application of advanced technologies to improve agricultural productivity, efficiency, and profitability while minimizing waste and environmental impact. Deep learning approaches enable automated decision-making for many visual tasks. However, in the agricultural domain, variability in growth stages and environmental conditions, such as weather and lighting, presents significant challenges to developing deep learning-based techniques that generalize across different conditions. The resource-intensive nature of creating extensive annotated datasets that capture these variabilities further hinders the widespread adoption of these approaches. To tackle these issues, we introduce a semi-self-supervised domain adaptation technique based on deep convolutional neural networks with a probabilistic diffusion process, requiring minimal manual data annotation. Using only three manually annotated images and a selection of video clips from wheat fields, we generated a large-scale computationally annotated dataset of image-mask pairs and a large dataset of unannotated images extracted from video frames. We developed a two-branch convolutional encoder-decoder model architecture that uses both synthesized image-mask pairs and unannotated images, enabling effective adaptation to real images. The proposed model achieved a Dice score of 80.7\% on an internal test dataset and a Dice score of 64.8\% on an external test set, composed of images from five countries and spanning 18 domains, indicating its potential to develop generalizable solutions that could encourage the wider adoption of advanced technologies in agriculture.
Modified CycleGAN for the synthesization of samples for wheat head segmentation
Feb 23, 2024



Deep learning models have been used for a variety of image processing tasks. However, most of these models are developed through supervised learning approaches, which rely heavily on the availability of large-scale annotated datasets. Developing such datasets is tedious and expensive. In the absence of an annotated dataset, synthetic data can be used for model development; however, due to the substantial differences between simulated and real data, a phenomenon referred to as domain gap, the resulting models often underperform when applied to real data. In this research, we aim to address this challenge by first computationally simulating a large-scale annotated dataset and then using a generative adversarial network (GAN) to fill the gap between simulated and real images. This approach results in a synthetic dataset that can be effectively utilized to train a deep-learning model. Using this approach, we developed a realistic annotated synthetic dataset for wheat head segmentation. This dataset was then used to develop a deep-learning model for semantic segmentation. The resulting model achieved a Dice score of 83.4\% on an internal dataset and Dice scores of 79.6% and 83.6% on two external Global Wheat Head Detection datasets. While we proposed this approach in the context of wheat head segmentation, it can be generalized to other crop types or, more broadly, to images with dense, repeated patterns such as those found in cellular imagery.
RIDGE: Reproducibility, Integrity, Dependability, Generalizability, and Efficiency Assessment of Medical Image Segmentation Models
Jan 16, 2024
Deep learning techniques, despite their potential, often suffer from a lack of reproducibility and generalizability, impeding their clinical adoption. Image segmentation is one of the critical tasks in medical image analysis, in which one or several regions/volumes of interest should be annotated. This paper introduces the RIDGE checklist, a framework for assessing the Reproducibility, Integrity, Dependability, Generalizability, and Efficiency of deep learning-based medical image segmentation models. The checklist serves as a guide for researchers to enhance the quality and transparency of their work, ensuring that segmentation models are not only scientifically sound but also clinically relevant.
Generalizability of Machine Learning Models: Quantitative Evaluation of Three Methodological Pitfalls
Feb 01, 2022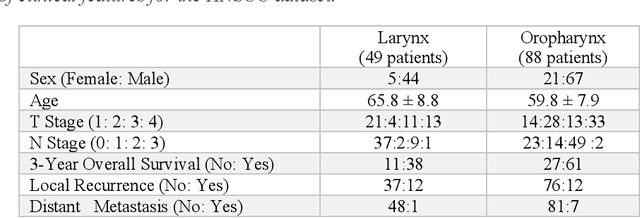
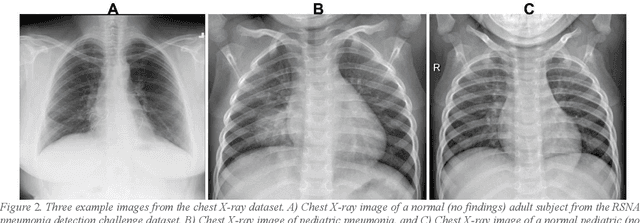
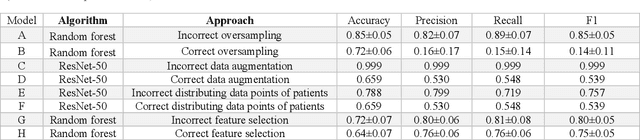
Despite the great potential of machine learning, the lack of generalizability has hindered the widespread adoption of these technologies in routine clinical practice. We investigate three methodological pitfalls: (1) violation of independence assumption, (2) model evaluation with an inappropriate performance indicator, and (3) batch effect and how these pitfalls could affect the generalizability of machine learning models. We implement random forest and deep convolutional neural network models using several medical imaging datasets, including head and neck CT, lung CT, chest X-Ray, and histopathological images, to quantify and illustrate the effect of these pitfalls. We develop these models with and without the pitfall and compare the performance of the resulting models in terms of accuracy, precision, recall, and F1 score. Our results showed that violation of the independence assumption could substantially affect model generalizability. More specifically, (I) applying oversampling before splitting data into train, validation and test sets; (II) performing data augmentation before splitting data; (III) distributing data points for a subject across training, validation, and test sets; and (IV) applying feature selection before splitting data led to superficial boosts in model performance. We also observed that inappropriate performance indicators could lead to erroneous conclusions. Also, batch effect could lead to developing models that lack generalizability. The aforementioned methodological pitfalls lead to machine learning models with over-optimistic performance. These errors, if made, cannot be captured using internal model evaluation, and the inaccurate predictions made by the model may lead to wrong conclusions and interpretations. Therefore, avoiding these pitfalls is a necessary condition for developing generalizable models.
Does Proprietary Software Still Offer Protection of Intellectual Property in the Age of Machine Learning? -- A Case Study using Dual Energy CT Data
Dec 06, 2021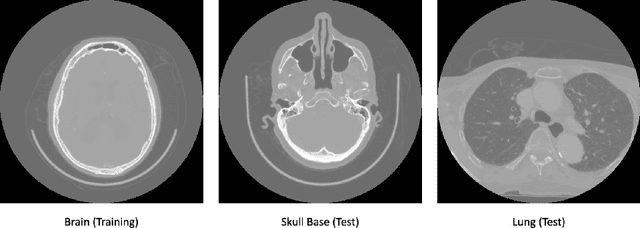
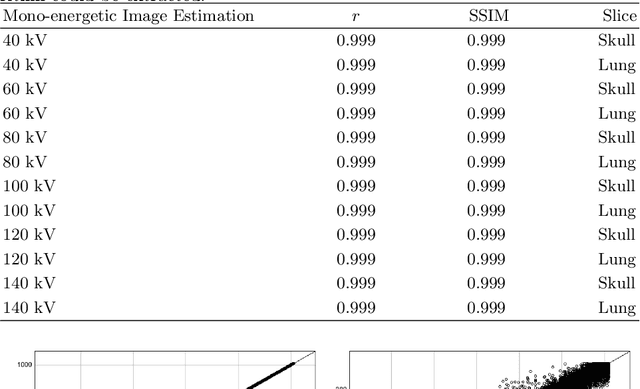
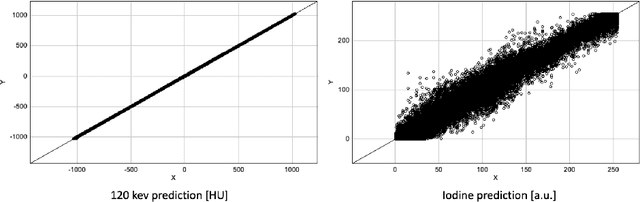
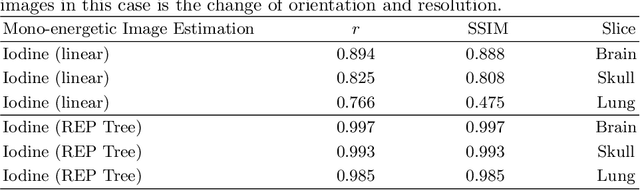
In the domain of medical image processing, medical device manufacturers protect their intellectual property in many cases by shipping only compiled software, i.e. binary code which can be executed but is difficult to be understood by a potential attacker. In this paper, we investigate how well this procedure is able to protect image processing algorithms. In particular, we investigate whether the computation of mono-energetic images and iodine maps from dual energy CT data can be reverse-engineered by machine learning methods. Our results indicate that both can be approximated using only one single slice image as training data at a very high accuracy with structural similarity greater than 0.98 in all investigated cases.
Crop Lodging Prediction from UAV-Acquired Images of Wheat and Canola using a DCNN Augmented with Handcrafted Texture Features
Jun 18, 2019
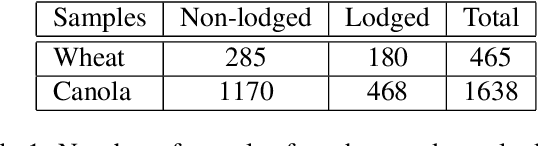
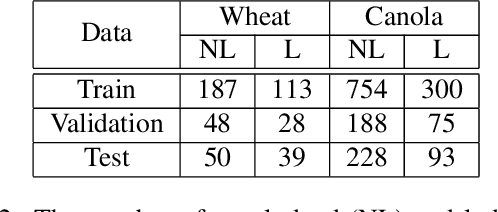

Lodging, the permanent bending over of food crops, leads to poor plant growth and development. Consequently, lodging results in reduced crop quality, lowers crop yield, and makes harvesting difficult. Plant breeders routinely evaluate several thousand breeding lines, and therefore, automatic lodging detection and prediction is of great value aid in selection. In this paper, we propose a deep convolutional neural network (DCNN) architecture for lodging classification using five spectral channel orthomosaic images from canola and wheat breeding trials. Also, using transfer learning, we trained 10 lodging detection models using well-established deep convolutional neural network architectures. Our proposed model outperforms the state-of-the-art lodging detection methods in the literature that use only handcrafted features. In comparison to 10 DCNN lodging detection models, our proposed model achieves comparable results while having a substantially lower number of parameters. This makes the proposed model suitable for applications such as real-time classification using inexpensive hardware for high-throughput phenotyping pipelines. The GitHub repository at https://github.com/FarhadMaleki/LodgedNet contains code and models.