 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling Radiomics Complexity: Strategies for Optimal Simplicity in Predictive Modeling
Jul 05, 2024



Background: The high dimensionality of radiomic feature sets, the variability in radiomic feature types and potentially high computational requirements all underscore the need for an effective method to identify the smallest set of predictive features for a given clinical problem. Purpose: Develop a methodology and tools to identify and explain the smallest set of predictive radiomic features. Materials and Methods: 89,714 radiomic features were extracted from five cancer datasets: low-grade glioma, meningioma, non-small cell lung cancer (NSCLC), and two renal cell carcinoma cohorts (n=2104). Features were categorized by computational complexity into morphological, intensity, texture, linear filters, and nonlinear filters. Models were trained and evaluated on each complexity level using the area under the curve (AUC). The most informative features were identified, and their importance was explained. The optimal complexity level and associated most informative features were identified using systematic statistical significance analyses and a false discovery avoidance procedure, respectively. Their predictive importance was explained using a novel tree-based method. Results: MEDimage, a new open-source tool, was developed to facilitate radiomic studies. Morphological features were optimal for MRI-based meningioma (AUC: 0.65) and low-grade glioma (AUC: 0.68). Intensity features were optimal for CECT-based renal cell carcinoma (AUC: 0.82) and CT-based NSCLC (AUC: 0.76). Texture features were optimal for MRI-based renal cell carcinoma (AUC: 0.72). Tuning the Hounsfield unit range improved results for CECT-based renal cell carcinoma (AUC: 0.86). Conclusion: Our proposed methodology and software can estimate the optimal radiomics complexity level for specific medical outcomes, potentially simplifying the use of radiomics in predictive modeling across various contexts.
Generalizability of Machine Learning Models: Quantitative Evaluation of Three Methodological Pitfalls
Feb 01, 2022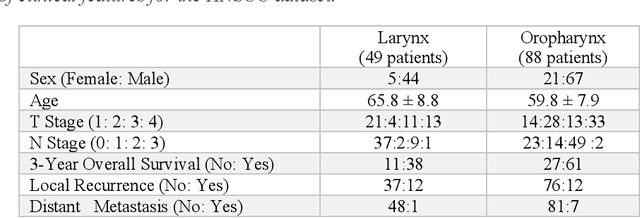
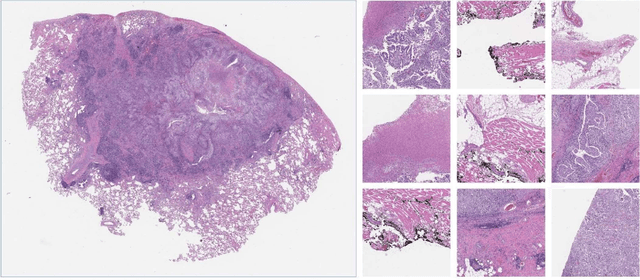
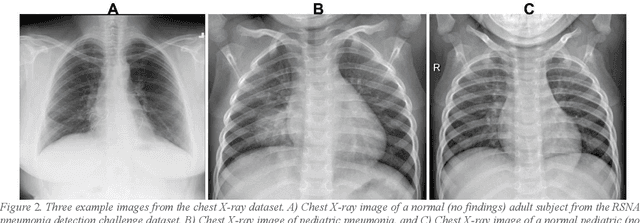
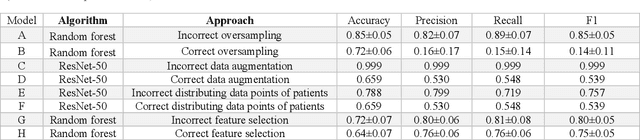
Despite the great potential of machine learning, the lack of generalizability has hindered the widespread adoption of these technologies in routine clinical practice. We investigate three methodological pitfalls: (1) violation of independence assumption, (2) model evaluation with an inappropriate performance indicator, and (3) batch effect and how these pitfalls could affect the generalizability of machine learning models. We implement random forest and deep convolutional neural network models using several medical imaging datasets, including head and neck CT, lung CT, chest X-Ray, and histopathological images, to quantify and illustrate the effect of these pitfalls. We develop these models with and without the pitfall and compare the performance of the resulting models in terms of accuracy, precision, recall, and F1 score. Our results showed that violation of the independence assumption could substantially affect model generalizability. More specifically, (I) applying oversampling before splitting data into train, validation and test sets; (II) performing data augmentation before splitting data; (III) distributing data points for a subject across training, validation, and test sets; and (IV) applying feature selection before splitting data led to superficial boosts in model performance. We also observed that inappropriate performance indicators could lead to erroneous conclusions. Also, batch effect could lead to developing models that lack generalizability. The aforementioned methodological pitfalls lead to machine learning models with over-optimistic performance. These errors, if made, cannot be captured using internal model evaluation, and the inaccurate predictions made by the model may lead to wrong conclusions and interpretations. Therefore, avoiding these pitfalls is a necessary condition for developing generalizable models.