 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Video Prediction With Fast Video Interpolation Model and Prediction Training
Mar 29, 2025Transmission latency significantly affects users' quality of experience in real-time interaction and actuation. As latency is principally inevitable, video prediction can be utilized to mitigate the latency and ultimately enable zero-latency transmission. However, most of the existing video prediction methods are computationally expensive and impractical for real-time applications. In this work, we therefore propose real-time video prediction towards the zero-latency interaction over networks, called IFRVP (Intermediate Feature Refinement Video Prediction). Firstly, we propose three training methods for video prediction that extend frame interpolation models, where we utilize a simple convolution-only frame interpolation network based on IFRNet. Secondly, we introduce ELAN-based residual blocks into the prediction models to improve both inference speed and accuracy. Our evaluations show that our proposed models perform efficiently and achieve the best trade-off between prediction accuracy and computational speed among the existing video prediction methods. A demonstration movie is also provided at http://bit.ly/IFRVPDemo.
Lightweight Stochastic Video Prediction via Hybrid Warping
Dec 04, 2024



Accurate video prediction by deep neural networks, especially for dynamic regions, is a challenging task in computer vision for critical applications such as autonomous driving, remote working, and telemedicine. Due to inherent uncertainties, existing prediction models often struggle with the complexity of motion dynamics and occlusions. In this paper, we propose a novel stochastic long-term video prediction model that focuses on dynamic regions by employing a hybrid warping strategy. By integrating frames generated through forward and backward warpings, our approach effectively compensates for the weaknesses of each technique, improving the prediction accuracy and realism of moving regions in videos while also addressing uncertainty by making stochastic predictions that account for various motions. Furthermore, considering real-time predictions, we introduce a MobileNet-based lightweight architecture into our model. Our model, called SVPHW, achieves state-of-the-art performance on two benchmark datasets.
ABCAS: Adaptive Bound Control of spectral norm as Automatic Stabilizer
Nov 12, 2022

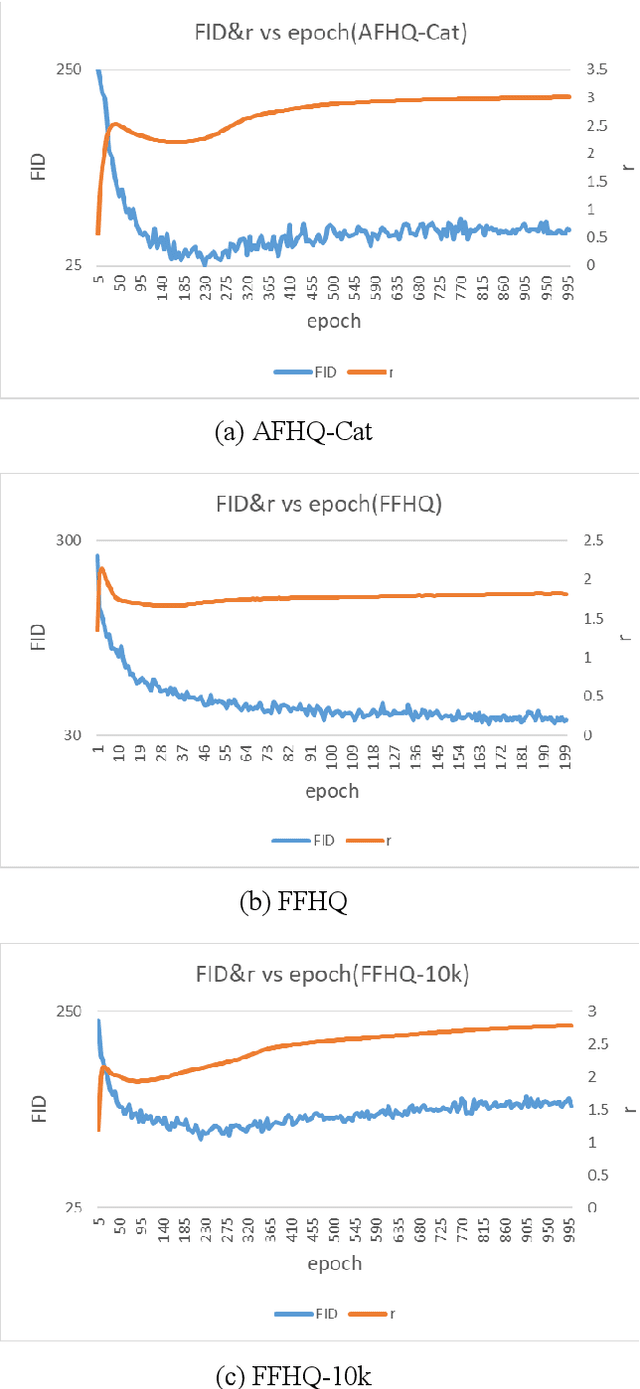

Spectral Normalization is one of the best methods for stabilizing the training of Generative Adversarial Network. Spectral Normalization limits the gradient of discriminator between the distribution between real data and fake data. However, even with this normalization, GAN's training sometimes fails. In this paper, we reveal that more severe restriction is sometimes needed depending on the training dataset, then we propose a novel stabilizer which offers an adaptive normalization method, called ABCAS. Our method decides discriminator's Lipschitz constant adaptively, by checking the distance of distributions of real and fake data. Our method improves the stability of the training of Generative Adversarial Network and achieved better Fr\'echet Inception Distance score of generated images. We also investigated suitable spectral norm for three datasets. We show the result as an ablation study.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
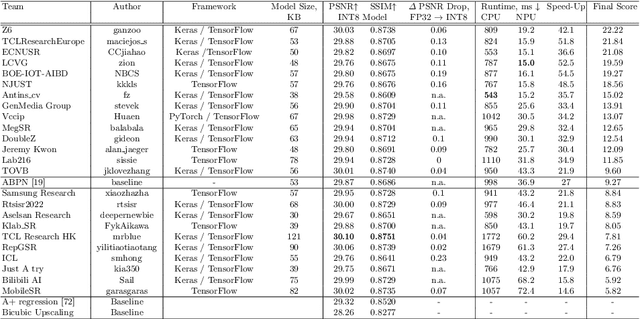
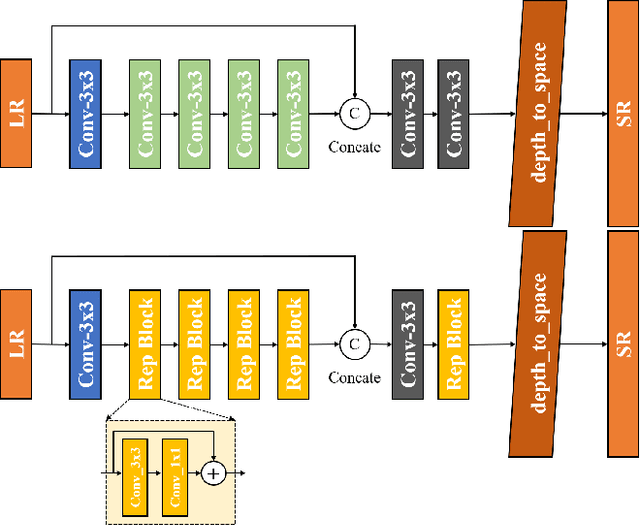
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.