 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Fatigue Cracks Detection in Bridge Girders using Feature Pyramid Networks
Oct 28, 2024



For structural health monitoring, continuous and automatic crack detection has been a challenging problem. This study is conducted to propose a framework of automatic crack segmentation from high-resolution images containing crack information about steel box girders of bridges. Considering the multi-scale feature of cracks, convolutional neural network architecture of Feature Pyramid Networks (FPN) for crack detection is proposed. As for input, 120 raw images are processed via two approaches (shrinking the size of images and splitting images into sub-images). Then, models with the proposed structure of FPN for crack detection are developed. The result shows all developed models can automatically detect the cracks at the raw images. By shrinking the images, the computation efficiency is improved without decreasing accuracy. Because of the separable characteristic of crack, models using the splitting method provide more accurate crack segmentations than models using the resizing method. Therefore, for high-resolution images, the FPN structure coupled with the splitting method is an promising solution for the crack segmentation and detection.
Continual-learning-based framework for structural damage recognition
Aug 28, 2024Multi-damage is common in reinforced concrete structures and leads to the requirement of large number of neural networks, parameters and data storage, if convolutional neural network (CNN) is used for damage recognition. In addition, conventional CNN experiences catastrophic forgetting and training inefficiency as the number of tasks increases during continual learning, leading to large accuracy decrease of previous learned tasks. To address these problems, this study proposes a continuallearning-based damage recognition model (CLDRM) which integrates the learning without forgetting continual learning method into the ResNet-34 architecture for the recognition of damages in RC structures as well as relevant structural components. Three experiments for four recognition tasks were designed to validate the feasibility and effectiveness of the CLDRM framework. In this way, it reduces both the prediction time and data storage by about 75% in four tasks of continuous learning. Three experiments for four recognition tasks were designed to validate the feasibility and effectiveness of the CLDRM framework. By gradual feature fusion, CLDRM outperformed other methods by managed to achieve high accuracy in the damage recognition and classification. As the number of recognition tasks increased, CLDRM also experienced smaller decrease of the previous learned tasks. Results indicate that the CLDRM framework successfully performs damage recognition and classification with reasonable accuracy and effectiveness.
A comparative study of attention mechanism and generative adversarial network in facade damage segmentation
Sep 27, 2022
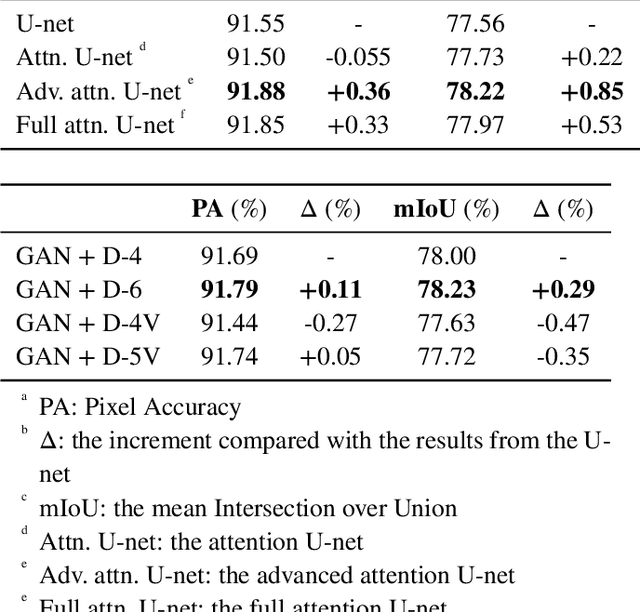

Semantic segmentation profits from deep learning and has shown its possibilities in handling the graphical data from the on-site inspection. As a result, visual damage in the facade images should be detected. Attention mechanism and generative adversarial networks are two of the most popular strategies to improve the quality of semantic segmentation. With specific focuses on these two strategies, this paper adopts U-net, a representative convolutional neural network, as the primary network and presents a comparative study in two steps. First, cell images are utilized to respectively determine the most effective networks among the U-nets with attention mechanism or generative adversarial networks. Subsequently, selected networks from the first test and their combination are applied for facade damage segmentation to investigate the performances of these networks. Besides, the combined effect of the attention mechanism and the generative adversarial network is discovered and discussed.
Crack Semantic Segmentation using the U-Net with Full Attention Strategy
Apr 29, 2021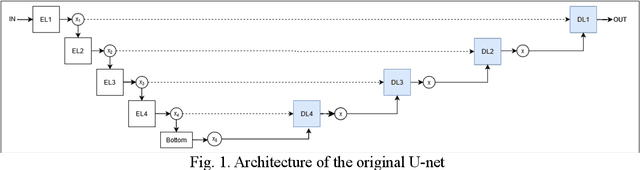
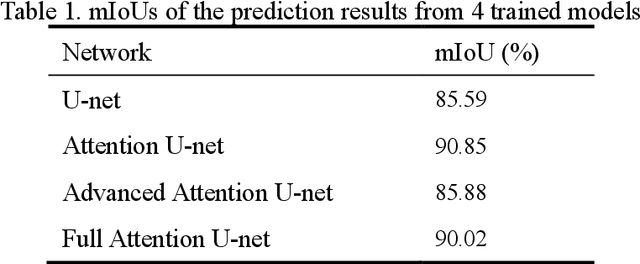


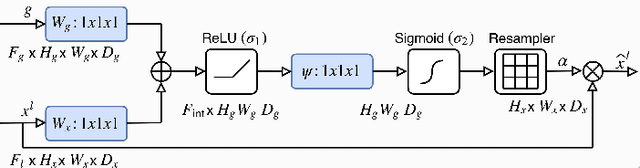
Structures suffer from the emergence of cracks, therefore, crack detection is always an issue with much concern in structural health monitoring. Along with the rapid progress of deep learning technology, image semantic segmentation, an active research field, offers another solution, which is more effective and intelligent, to crack detection Through numerous artificial neural networks have been developed to address the preceding issue, corresponding explorations are never stopped improving the quality of crack detection. This paper presents a novel artificial neural network architecture named Full Attention U-net for image semantic segmentation. The proposed architecture leverages the U-net as the backbone and adopts the Full Attention Strategy, which is a synthesis of the attention mechanism and the outputs from each encoding layer in skip connection. Subject to the hardware in training, the experiments are composed of verification and validation. In verification, 4 networks including U-net, Attention U-net, Advanced Attention U-net, and Full Attention U-net are tested through cell images for a competitive study. With respect to mean intersection-over-unions and clarity of edge identification, the Full Attention U-net performs best in verification, and is hence applied for crack semantic segmentation in validation to demonstrate its effectiveness.