 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreathing Life into Faces: Speech-driven 3D Facial Animation with Natural Head Pose and Detailed Shape
Oct 31, 2023



The creation of lifelike speech-driven 3D facial animation requires a natural and precise synchronization between audio input and facial expressions. However, existing works still fail to render shapes with flexible head poses and natural facial details (e.g., wrinkles). This limitation is mainly due to two aspects: 1) Collecting training set with detailed 3D facial shapes is highly expensive. This scarcity of detailed shape annotations hinders the training of models with expressive facial animation. 2) Compared to mouth movement, the head pose is much less correlated to speech content. Consequently, concurrent modeling of both mouth movement and head pose yields the lack of facial movement controllability. To address these challenges, we introduce VividTalker, a new framework designed to facilitate speech-driven 3D facial animation characterized by flexible head pose and natural facial details. Specifically, we explicitly disentangle facial animation into head pose and mouth movement and encode them separately into discrete latent spaces. Then, these attributes are generated through an autoregressive process leveraging a window-based Transformer architecture. To augment the richness of 3D facial animation, we construct a new 3D dataset with detailed shapes and learn to synthesize facial details in line with speech content. Extensive quantitative and qualitative experiments demonstrate that VividTalker outperforms state-of-the-art methods, resulting in vivid and realistic speech-driven 3D facial animation.
One at A Time: Multi-step Volumetric Probability Distribution Diffusion for Depth Estimation
Jul 07, 2023Recent works have explored the fundamental role of depth estimation in multi-view stereo (MVS) and semantic scene completion (SSC). They generally construct 3D cost volumes to explore geometric correspondence in depth, and estimate such volumes in a single step relying directly on the ground truth approximation. However, such problem cannot be thoroughly handled in one step due to complex empirical distributions, especially in challenging regions like occlusions, reflections, etc. In this paper, we formulate the depth estimation task as a multi-step distribution approximation process, and introduce a new paradigm of modeling the Volumetric Probability Distribution progressively (step-by-step) following a Markov chain with Diffusion models (VPDD). Specifically, to constrain the multi-step generation of volume in VPDD, we construct a meta volume guidance and a confidence-aware contextual guidance as conditional geometry priors to facilitate the distribution approximation. For the sampling process, we further investigate an online filtering strategy to maintain consistency in volume representations for stable training. Experiments demonstrate that our plug-and-play VPDD outperforms the state-of-the-arts for tasks of MVS and SSC, and can also be easily extended to different baselines to get improvement. It is worth mentioning that we are the first camera-based work that surpasses LiDAR-based methods on the SemanticKITTI dataset.
EMoG: Synthesizing Emotive Co-speech 3D Gesture with Diffusion Model
Jun 20, 2023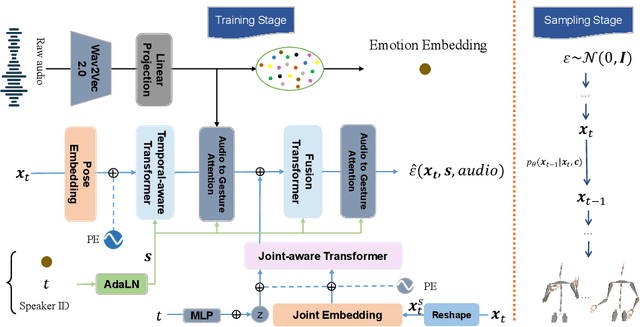
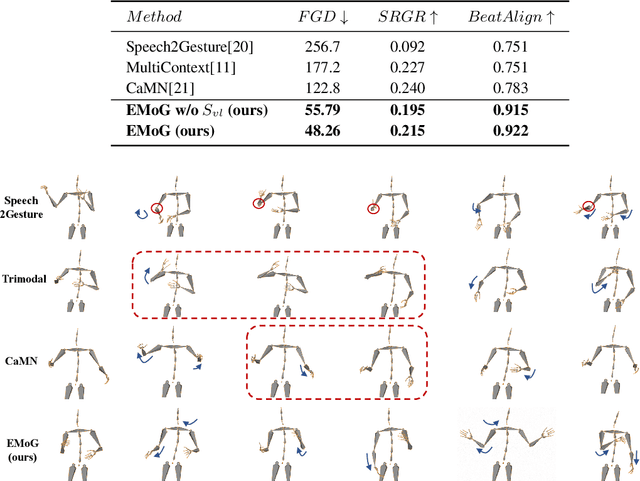
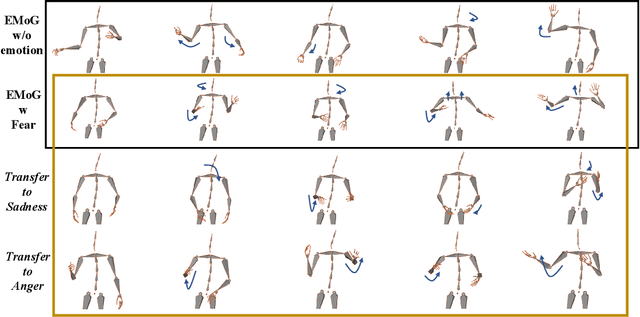
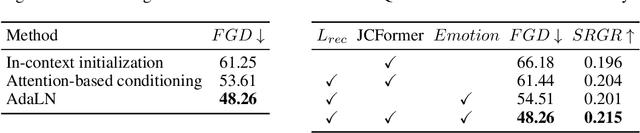
Although previous co-speech gesture generation methods are able to synthesize motions in line with speech content, it is still not enough to handle diverse and complicated motion distribution. The key challenges are: 1) the one-to-many nature between the speech content and gestures; 2) the correlation modeling between the body joints. In this paper, we present a novel framework (EMoG) to tackle the above challenges with denoising diffusion models: 1) To alleviate the one-to-many problem, we incorporate emotion clues to guide the generation process, making the generation much easier; 2) To model joint correlation, we propose to decompose the difficult gesture generation into two sub-problems: joint correlation modeling and temporal dynamics modeling. Then, the two sub-problems are explicitly tackled with our proposed Joint Correlation-aware transFormer (JCFormer). Through extensive evaluations, we demonstrate that our proposed method surpasses previous state-of-the-art approaches, offering substantial superiority in gesture synthesis.