 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Semantic Segmentation with Decoupled One-Pass Network
Paper and Code
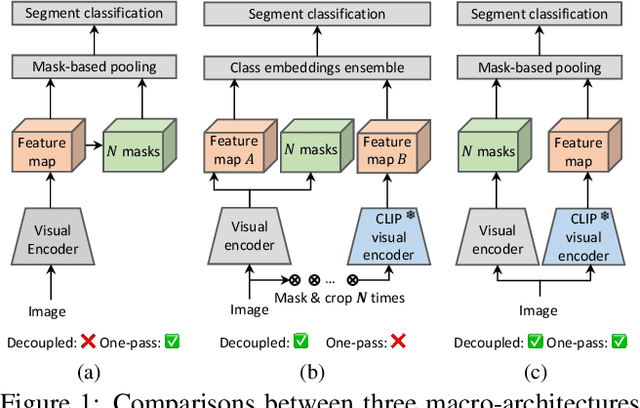
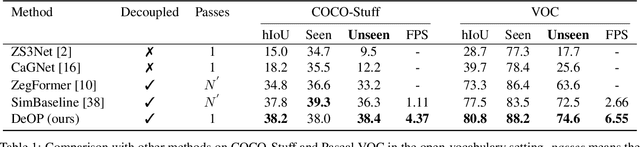


Recently, the zero-shot semantic segmentation problem has attracted increasing attention, and the best performing methods are based on two-stream networks: one stream for proposal mask generation and the other for segment classification using a pre-trained visual-language model. However, existing two-stream methods require passing a great number of (up to a hundred) image crops into the visuallanguage model, which is highly inefficient. To address the problem, we propose a network that only needs a single pass through the visual-language model for each input image. Specifically, we first propose a novel network adaptation approach, termed patch severance, to restrict the harmful interference between the patch embeddings in the pre-trained visual encoder. We then propose classification anchor learning to encourage the network to spatially focus on more discriminative features for classification. Extensive experiments demonstrate that the proposed method achieves outstanding performance, surpassing state-of-theart methods while being 4 to 7 times faster at inference. We release our code at https://github.com/CongHan0808/DeOP.git.