 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report
Jan 28, 2026We present Foundation-Sec-8B-Reasoning, the first open-source native reasoning model for cybersecurity. Built upon our previously released Foundation-Sec-8B base model (derived from Llama-3.1-8B-Base), the model is trained through a two-stage process combining supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). Our training leverages proprietary reasoning data spanning cybersecurity analysis, instruction-following, and mathematical reasoning. Evaluation across 10 cybersecurity benchmarks and 10 general-purpose benchmarks demonstrates performance competitive with significantly larger models on cybersecurity tasks while maintaining strong general capabilities. The model shows effective generalization on multi-hop reasoning tasks and strong safety performance when deployed with appropriate system prompts and guardrails. This work demonstrates that domain-specialized reasoning models can achieve strong performance on specialized tasks while maintaining broad general capabilities. We release the model publicly at https://huggingface.co/fdtn-ai/Foundation-Sec-8B-Reasoning.
In-Context Linear Regression Demystified: Training Dynamics and Mechanistic Interpretability of Multi-Head Softmax Attention
Mar 17, 2025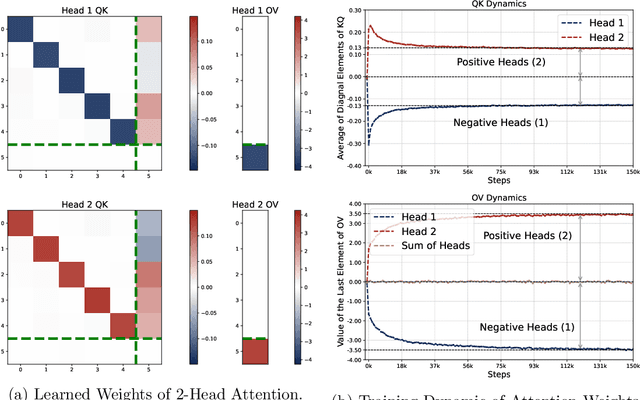

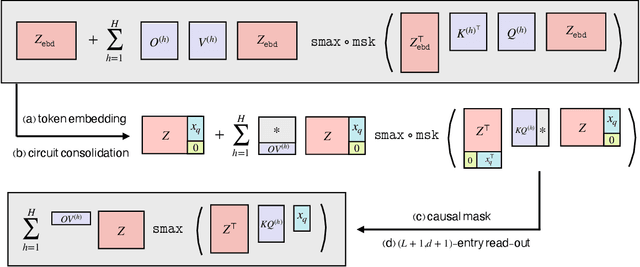

We study how multi-head softmax attention models are trained to perform in-context learning on linear data. Through extensive empirical experiments and rigorous theoretical analysis, we demystify the emergence of elegant attention patterns: a diagonal and homogeneous pattern in the key-query (KQ) weights, and a last-entry-only and zero-sum pattern in the output-value (OV) weights. Remarkably, these patterns consistently appear from gradient-based training starting from random initialization. Our analysis reveals that such emergent structures enable multi-head attention to approximately implement a debiased gradient descent predictor -- one that outperforms single-head attention and nearly achieves Bayesian optimality up to proportional factor. Furthermore, compared to linear transformers, the softmax attention readily generalizes to sequences longer than those seen during training. We also extend our study to scenarios with non-isotropic covariates and multi-task linear regression. In the former, multi-head attention learns to implement a form of pre-conditioned gradient descent. In the latter, we uncover an intriguing regime where the interplay between head number and task number triggers a superposition phenomenon that efficiently resolves multi-task in-context learning. Our results reveal that in-context learning ability emerges from the trained transformer as an aggregated effect of its architecture and the underlying data distribution, paving the way for deeper understanding and broader applications of in-context learning.
SAT: Data-light Uncertainty Set Merging via Synthetics, Aggregation, and Test Inversion
Oct 16, 2024



The integration of uncertainty sets has diverse applications but also presents challenges, particularly when only initial sets and their control levels are available, along with potential dependencies. Examples include merging confidence sets from different distributed sites with communication constraints, as well as combining conformal prediction sets generated by different learning algorithms or data splits. In this article, we introduce an efficient and flexible Synthetic, Aggregation, and Test inversion (SAT) approach to merge various potentially dependent uncertainty sets into a single set. The proposed method constructs a novel class of synthetic test statistics, aggregates them, and then derives merged sets through test inversion. Our approach leverages the duality between set estimation and hypothesis testing, ensuring reliable coverage in dependent scenarios. The procedure is data-light, meaning it relies solely on initial sets and control levels without requiring raw data, and it adapts to any user-specified initial uncertainty sets, accommodating potentially varying coverage levels. Theoretical analyses and numerical experiments confirm that SAT provides finite-sample coverage guarantees and achieves small set sizes.
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
May 30, 2024In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $\epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Sample-efficient Learning of Infinite-horizon Average-reward MDPs with General Function Approximation
Apr 19, 2024We study infinite-horizon average-reward Markov decision processes (AMDPs) in the context of general function approximation. Specifically, we propose a novel algorithmic framework named Local-fitted Optimization with OPtimism (LOOP), which incorporates both model-based and value-based incarnations. In particular, LOOP features a novel construction of confidence sets and a low-switching policy updating scheme, which are tailored to the average-reward and function approximation setting. Moreover, for AMDPs, we propose a novel complexity measure -- average-reward generalized eluder coefficient (AGEC) -- which captures the challenge of exploration in AMDPs with general function approximation. Such a complexity measure encompasses almost all previously known tractable AMDP models, such as linear AMDPs and linear mixture AMDPs, and also includes newly identified cases such as kernel AMDPs and AMDPs with Bellman eluder dimensions. Using AGEC, we prove that LOOP achieves a sublinear $\tilde{\mathcal{O}}(\mathrm{poly}(d, \mathrm{sp}(V^*)) \sqrt{T\beta} )$ regret, where $d$ and $\beta$ correspond to AGEC and log-covering number of the hypothesis class respectively, $\mathrm{sp}(V^*)$ is the span of the optimal state bias function, $T$ denotes the number of steps, and $\tilde{\mathcal{O}} (\cdot) $ omits logarithmic factors. When specialized to concrete AMDP models, our regret bounds are comparable to those established by the existing algorithms designed specifically for these special cases. To the best of our knowledge, this paper presents the first comprehensive theoretical framework capable of handling nearly all AMDPs.