 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Linear Regression Demystified: Training Dynamics and Mechanistic Interpretability of Multi-Head Softmax Attention
Paper and Code
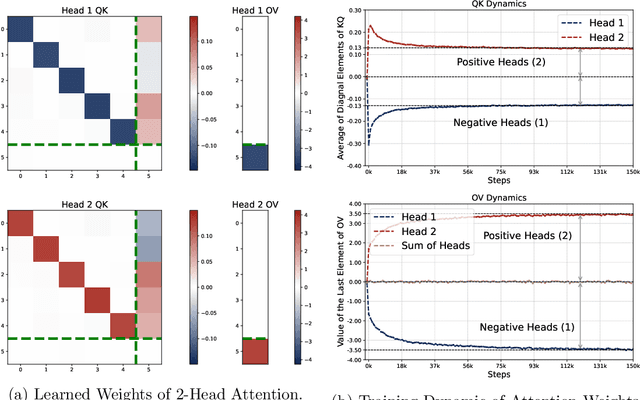

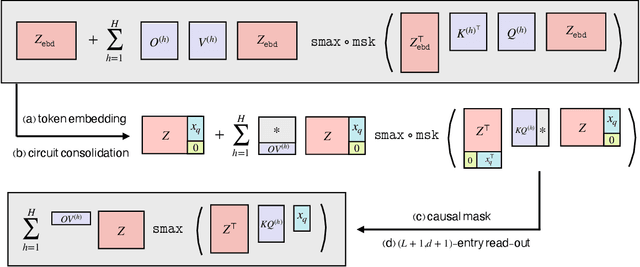

We study how multi-head softmax attention models are trained to perform in-context learning on linear data. Through extensive empirical experiments and rigorous theoretical analysis, we demystify the emergence of elegant attention patterns: a diagonal and homogeneous pattern in the key-query (KQ) weights, and a last-entry-only and zero-sum pattern in the output-value (OV) weights. Remarkably, these patterns consistently appear from gradient-based training starting from random initialization. Our analysis reveals that such emergent structures enable multi-head attention to approximately implement a debiased gradient descent predictor -- one that outperforms single-head attention and nearly achieves Bayesian optimality up to proportional factor. Furthermore, compared to linear transformers, the softmax attention readily generalizes to sequences longer than those seen during training. We also extend our study to scenarios with non-isotropic covariates and multi-task linear regression. In the former, multi-head attention learns to implement a form of pre-conditioned gradient descent. In the latter, we uncover an intriguing regime where the interplay between head number and task number triggers a superposition phenomenon that efficiently resolves multi-task in-context learning. Our results reveal that in-context learning ability emerges from the trained transformer as an aggregated effect of its architecture and the underlying data distribution, paving the way for deeper understanding and broader applications of in-context learning.