 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy
Paper and Code
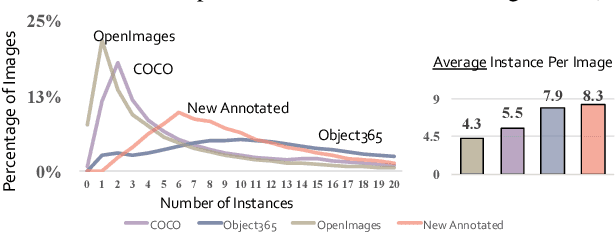

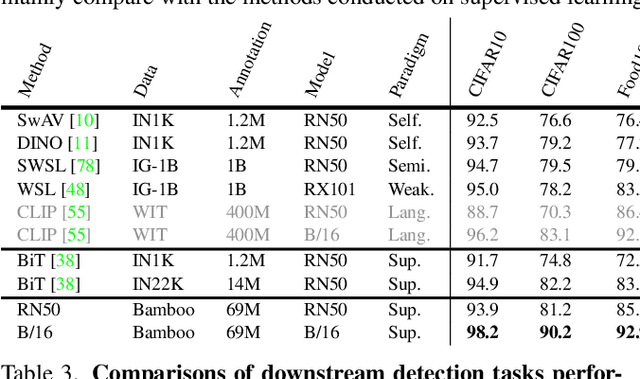
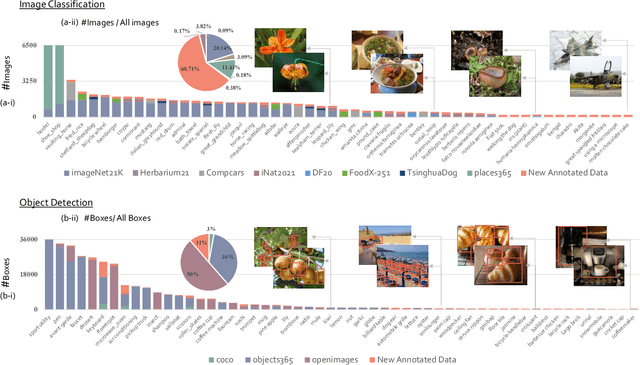
Large-scale datasets play a vital role in computer vision. Existing datasets are either collected according to heuristic label systems or annotated blindly without differentiation to samples, making them inefficient and unscalable. How to systematically collect, annotate and build a mega-scale dataset remains an open question. In this work, we advocate building a high-quality vision dataset actively and continually on a comprehensive label system. Specifically, we contribute Bamboo Dataset, a mega-scale and information-dense dataset for both classification and detection. Bamboo aims to populate the comprehensive categories with 69M image classification annotations and 170,586 object bounding box annotations. Compared to ImageNet22K and Objects365, models pre-trained on Bamboo achieve superior performance among various downstream tasks (6.2% gains on classification and 2.1% gains on detection). In addition, we provide valuable observations regarding large-scale pre-training from over 1,000 experiments. Due to its scalable nature on both label system and annotation pipeline, Bamboo will continue to grow and benefit from the collective efforts of the community, which we hope would pave the way for more general vision models.