 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2SGrad: Refined Gradients for Optimizing Deep Face Models
Paper and Code
May 07, 2019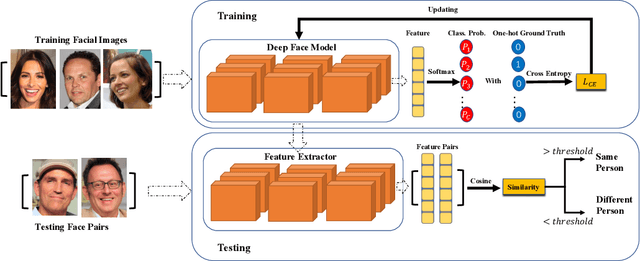
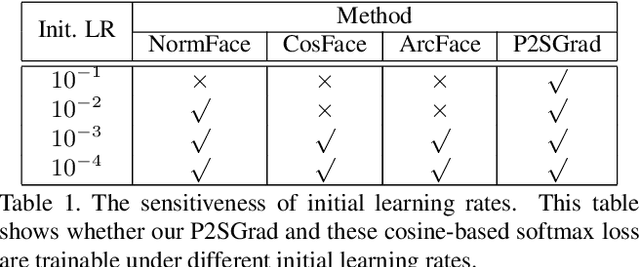
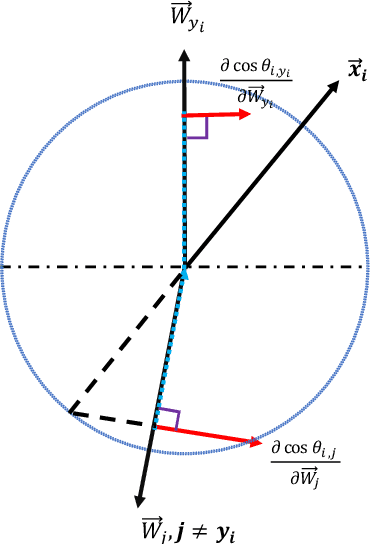
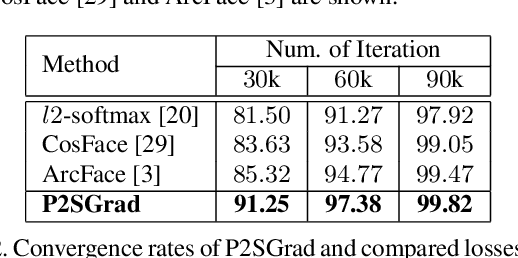
Cosine-based softmax losses significantly improve the performance of deep face recognition networks. However, these losses always include sensitive hyper-parameters which can make training process unstable, and it is very tricky to set suitable hyper parameters for a specific dataset. This paper addresses this challenge by directly designing the gradients for adaptively training deep neural networks. We first investigate and unify previous cosine softmax losses by analyzing their gradients. This unified view inspires us to propose a novel gradient called P2SGrad (Probability-to-Similarity Gradient), which leverages a cosine similarity instead of classification probability to directly update the testing metrics for updating neural network parameters. P2SGrad is adaptive and hyper-parameter free, which makes the training process more efficient and faster. We evaluate our P2SGrad on three face recognition benchmarks, LFW, MegaFace, and IJB-C. The results show that P2SGrad is stable in training, robust to noise, and achieves state-of-the-art performance on all the three benchmarks.