 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Convolution Designs into Visual Transformers
Apr 20, 2021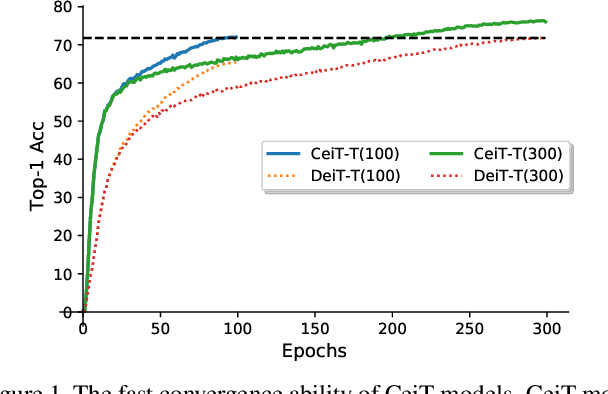

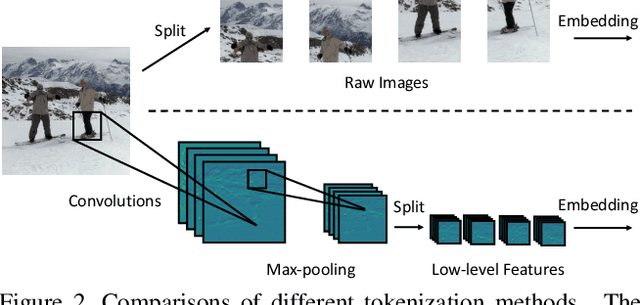

Motivated by the success of Transformers in natural language processing (NLP) tasks, there emerge some attempts (e.g., ViT and DeiT) to apply Transformers to the vision domain. However, pure Transformer architectures often require a large amount of training data or extra supervision to obtain comparable performance with convolutional neural networks (CNNs). To overcome these limitations, we analyze the potential drawbacks when directly borrowing Transformer architectures from NLP. Then we propose a new \textbf{Convolution-enhanced image Transformer (CeiT)} which combines the advantages of CNNs in extracting low-level features, strengthening locality, and the advantages of Transformers in establishing long-range dependencies. Three modifications are made to the original Transformer: \textbf{1)} instead of the straightforward tokenization from raw input images, we design an \textbf{Image-to-Tokens (I2T)} module that extracts patches from generated low-level features; \textbf{2)} the feed-froward network in each encoder block is replaced with a \textbf{Locally-enhanced Feed-Forward (LeFF)} layer that promotes the correlation among neighboring tokens in the spatial dimension; \textbf{3)} a \textbf{Layer-wise Class token Attention (LCA)} is attached at the top of the Transformer that utilizes the multi-level representations. Experimental results on ImageNet and seven downstream tasks show the effectiveness and generalization ability of CeiT compared with previous Transformers and state-of-the-art CNNs, without requiring a large amount of training data and extra CNN teachers. Besides, CeiT models also demonstrate better convergence with $3\times$ fewer training iterations, which can reduce the training cost significantly\footnote{Code and models will be released upon acceptance.}.
Differentiable Network Adaption with Elastic Search Space
Mar 30, 2021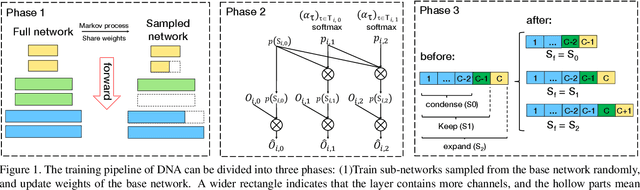
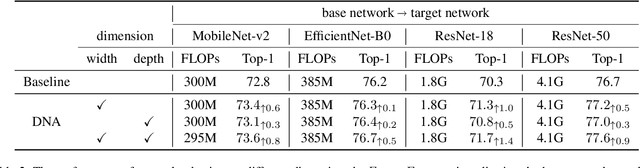
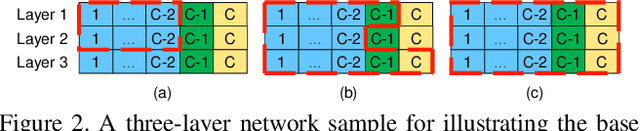
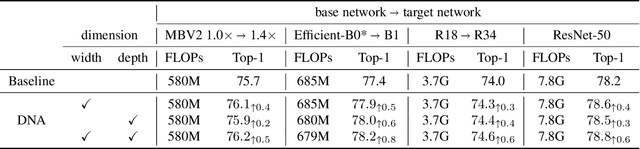
In this paper we propose a novel network adaption method called Differentiable Network Adaption (DNA), which can adapt an existing network to a specific computation budget by adjusting the width and depth in a differentiable manner. The gradient-based optimization allows DNA to achieve an automatic optimization of width and depth rather than previous heuristic methods that heavily rely on human priors. Moreover, we propose a new elastic search space that can flexibly condense or expand during the optimization process, allowing the network optimization of width and depth in a bi-direction manner. By DNA, we successfully achieve network architecture optimization by condensing and expanding in both width and depth dimensions. Extensive experiments on ImageNet demonstrate that DNA can adapt the existing network to meet different targeted computation requirements with better performance than previous methods. What's more, DNA can further improve the performance of high-accuracy networks obtained by state-of-the-art neural architecture search methods such as EfficientNet and MobileNet-v3.
DMCP: Differentiable Markov Channel Pruning for Neural Networks
May 08, 2020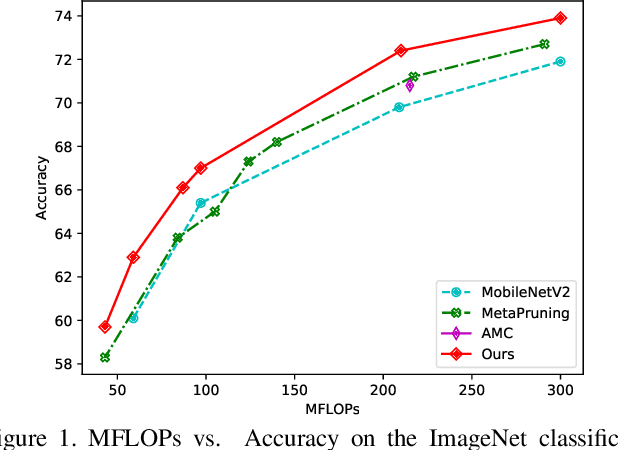
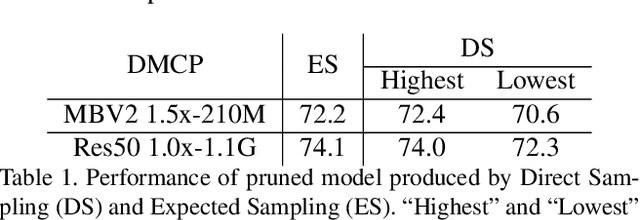
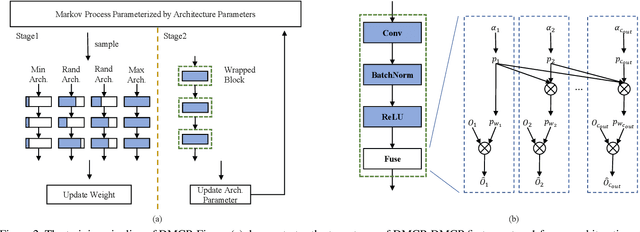
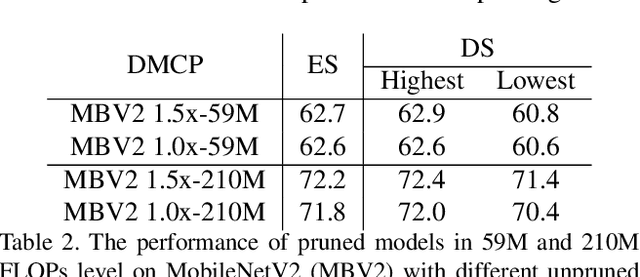
Recent works imply that the channel pruning can be regarded as searching optimal sub-structure from unpruned networks. However, existing works based on this observation require training and evaluating a large number of structures, which limits their application. In this paper, we propose a novel differentiable method for channel pruning, named Differentiable Markov Channel Pruning (DMCP), to efficiently search the optimal sub-structure. Our method is differentiable and can be directly optimized by gradient descent with respect to standard task loss and budget regularization (e.g. FLOPs constraint). In DMCP, we model the channel pruning as a Markov process, in which each state represents for retaining the corresponding channel during pruning, and transitions between states denote the pruning process. In the end, our method is able to implicitly select the proper number of channels in each layer by the Markov process with optimized transitions. To validate the effectiveness of our method, we perform extensive experiments on Imagenet with ResNet and MobilenetV2. Results show our method can achieve consistent improvement than state-of-the-art pruning methods in various FLOPs settings. The code is available at https://github.com/zx55/dmcp