 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Convolution Designs into Visual Transformers
Paper and Code
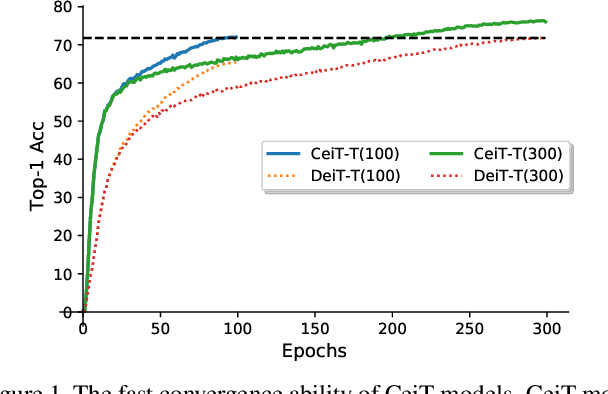

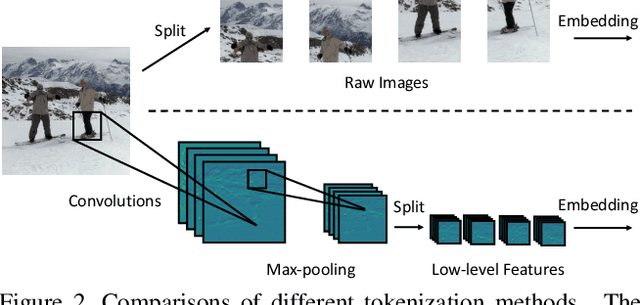

Motivated by the success of Transformers in natural language processing (NLP) tasks, there emerge some attempts (e.g., ViT and DeiT) to apply Transformers to the vision domain. However, pure Transformer architectures often require a large amount of training data or extra supervision to obtain comparable performance with convolutional neural networks (CNNs). To overcome these limitations, we analyze the potential drawbacks when directly borrowing Transformer architectures from NLP. Then we propose a new \textbf{Convolution-enhanced image Transformer (CeiT)} which combines the advantages of CNNs in extracting low-level features, strengthening locality, and the advantages of Transformers in establishing long-range dependencies. Three modifications are made to the original Transformer: \textbf{1)} instead of the straightforward tokenization from raw input images, we design an \textbf{Image-to-Tokens (I2T)} module that extracts patches from generated low-level features; \textbf{2)} the feed-froward network in each encoder block is replaced with a \textbf{Locally-enhanced Feed-Forward (LeFF)} layer that promotes the correlation among neighboring tokens in the spatial dimension; \textbf{3)} a \textbf{Layer-wise Class token Attention (LCA)} is attached at the top of the Transformer that utilizes the multi-level representations. Experimental results on ImageNet and seven downstream tasks show the effectiveness and generalization ability of CeiT compared with previous Transformers and state-of-the-art CNNs, without requiring a large amount of training data and extra CNN teachers. Besides, CeiT models also demonstrate better convergence with $3\times$ fewer training iterations, which can reduce the training cost significantly\footnote{Code and models will be released upon acceptance.}.