 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmojiDiff: Advanced Facial Expression Control with High Identity Preservation in Portrait Generation
Dec 02, 2024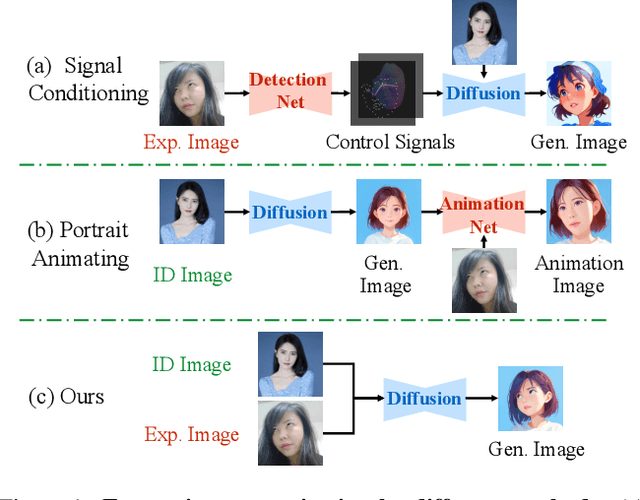
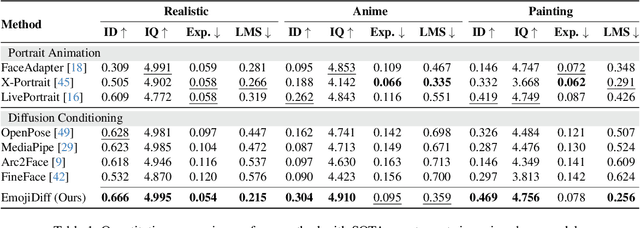

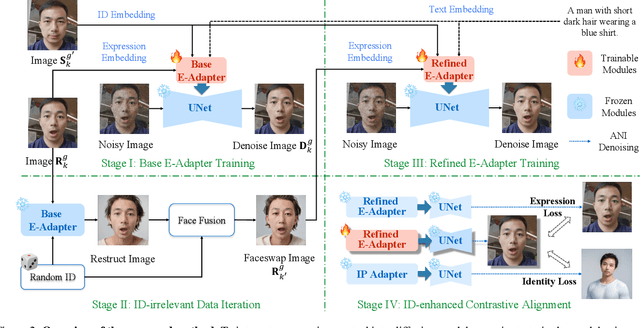
This paper aims to bring fine-grained expression control to identity-preserving portrait generation. Existing methods tend to synthesize portraits with either neutral or stereotypical expressions. Even when supplemented with control signals like facial landmarks, these models struggle to generate accurate and vivid expressions following user instructions. To solve this, we introduce EmojiDiff, an end-to-end solution to facilitate simultaneous dual control of fine expression and identity. Unlike the conventional methods using coarse control signals, our method directly accepts RGB expression images as input templates to provide extremely accurate and fine-grained expression control in the diffusion process. As its core, an innovative decoupled scheme is proposed to disentangle expression features in the expression template from other extraneous information, such as identity, skin, and style. On one hand, we introduce \textbf{I}D-irrelevant \textbf{D}ata \textbf{I}teration (IDI) to synthesize extremely high-quality cross-identity expression pairs for decoupled training, which is the crucial foundation to filter out identity information hidden in the expressions. On the other hand, we meticulously investigate network layer function and select expression-sensitive layers to inject reference expression features, effectively preventing style leakage from expression signals. To further improve identity fidelity, we propose a novel fine-tuning strategy named \textbf{I}D-enhanced \textbf{C}ontrast \textbf{A}lignment (ICA), which eliminates the negative impact of expression control on original identity preservation. Experimental results demonstrate that our method remarkably outperforms counterparts, achieves precise expression control with highly maintained identity, and generalizes well to various diffusion models.
Graph Neural Network Backend for Speaker Recognition
Aug 17, 2023Currently, most speaker recognition backends, such as cosine, linear discriminant analysis (LDA), or probabilistic linear discriminant analysis (PLDA), make decisions by calculating similarity or distance between enrollment and test embeddings which are already extracted from neural networks. However, for each embedding, the local structure of itself and its neighbor embeddings in the low-dimensional space is different, which may be helpful for the recognition but is often ignored. In order to take advantage of it, we propose a graph neural network (GNN) backend to mine latent relationships among embeddings for classification. We assume all the embeddings as nodes on a graph, and their edges are computed based on some similarity function, such as cosine, LDA+cosine, or LDA+PLDA. We study different graph settings and explore variants of GNN to find a better message passing and aggregation way to accomplish the recognition task. Experimental results on NIST SRE14 i-vector challenging, VoxCeleb1-O, VoxCeleb1-E, and VoxCeleb1-H datasets demonstrate that our proposed GNN backends significantly outperform current mainstream methods.