 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViFi-ReID: A Two-Stream Vision-WiFi Multimodal Approach for Person Re-identification
Oct 13, 2024



Person re-identification(ReID), as a crucial technology in the field of security, plays a vital role in safety inspections, personnel counting, and more. Most current ReID approaches primarily extract features from images, which are easily affected by objective conditions such as clothing changes and occlusions. In addition to cameras, we leverage widely available routers as sensing devices by capturing gait information from pedestrians through the Channel State Information (CSI) in WiFi signals and contribute a multimodal dataset. We employ a two-stream network to separately process video understanding and signal analysis tasks, and conduct multi-modal fusion and contrastive learning on pedestrian video and WiFi data. Extensive experiments in real-world scenarios demonstrate that our method effectively uncovers the correlations between heterogeneous data, bridges the gap between visual and signal modalities, significantly expands the sensing range, and improves ReID accuracy across multiple sensors.
Structure-enhanced Contrastive Learning for Graph Clustering
Aug 19, 2024



Graph clustering is a crucial task in network analysis with widespread applications, focusing on partitioning nodes into distinct groups with stronger intra-group connections than inter-group ones. Recently, contrastive learning has achieved significant progress in graph clustering. However, most methods suffer from the following issues: 1) an over-reliance on meticulously designed data augmentation strategies, which can undermine the potential of contrastive learning. 2) overlooking cluster-oriented structural information, particularly the higher-order cluster(community) structure information, which could unveil the mesoscopic cluster structure information of the network. In this study, Structure-enhanced Contrastive Learning (SECL) is introduced to addresses these issues by leveraging inherent network structures. SECL utilizes a cross-view contrastive learning mechanism to enhance node embeddings without elaborate data augmentations, a structural contrastive learning module for ensuring structural consistency, and a modularity maximization strategy for harnessing clustering-oriented information. This comprehensive approach results in robust node representations that greatly enhance clustering performance. Extensive experiments on six datasets confirm SECL's superiority over current state-of-the-art methods, indicating a substantial improvement in the domain of graph clustering.
Time-Frequency Analysis of Variable-Length WiFi CSI Signals for Person Re-Identification
Jul 12, 2024

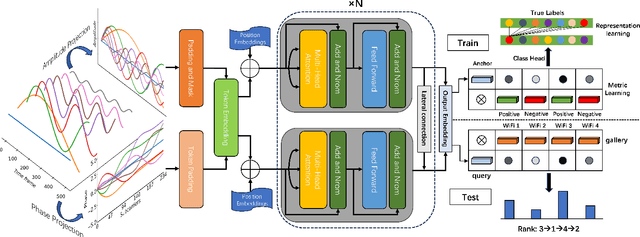
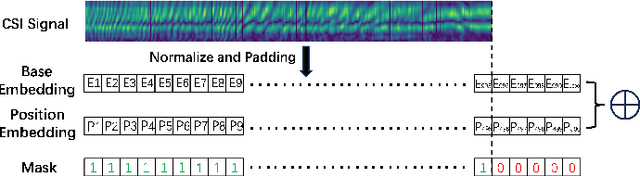
Person re-identification (ReID), as a crucial technology in the field of security, plays an important role in security detection and people counting. Current security and monitoring systems largely rely on visual information, which may infringe on personal privacy and be susceptible to interference from pedestrian appearances and clothing in certain scenarios. Meanwhile, the widespread use of routers offers new possibilities for ReID. This letter introduces a method using WiFi Channel State Information (CSI), leveraging the multipath propagation characteristics of WiFi signals as a basis for distinguishing different pedestrian features. We propose a two-stream network structure capable of processing variable-length data, which analyzes the amplitude in the time domain and the phase in the frequency domain of WiFi signals, fuses time-frequency information through continuous lateral connections, and employs advanced objective functions for representation and metric learning. Tested on a dataset collected in the real world, our method achieves 93.68% mAP and 98.13% Rank-1.
ProGEO: Generating Prompts through Image-Text Contrastive Learning for Visual Geo-localization
Jun 04, 2024Visual Geo-localization (VG) refers to the process to identify the location described in query images, which is widely applied in robotics field and computer vision tasks, such as autonomous driving, metaverse, augmented reality, and SLAM. In fine-grained images lacking specific text descriptions, directly applying pure visual methods to represent neighborhood features often leads to the model focusing on overly fine-grained features, unable to fully mine the semantic information in the images. Therefore, we propose a two-stage training method to enhance visual performance and use contrastive learning to mine challenging samples. We first leverage the multi-modal description capability of CLIP (Contrastive Language-Image Pretraining) to create a set of learnable text prompts for each geographic image feature to form vague descriptions. Then, by utilizing dynamic text prompts to assist the training of the image encoder, we enable the image encoder to learn better and more generalizable visual features. This strategy of applying text to purely visual tasks addresses the challenge of using multi-modal models for geographic images, which often suffer from a lack of precise descriptions, making them difficult to utilize widely. We validate the effectiveness of the proposed strategy on several large-scale visual geo-localization datasets, and our method achieves competitive results on multiple visual geo-localization datasets. Our code and model are available at https://github.com/Chain-Mao/ProGEO.