 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System
Mar 26, 2025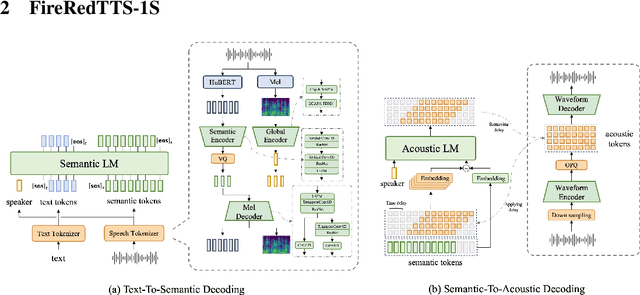
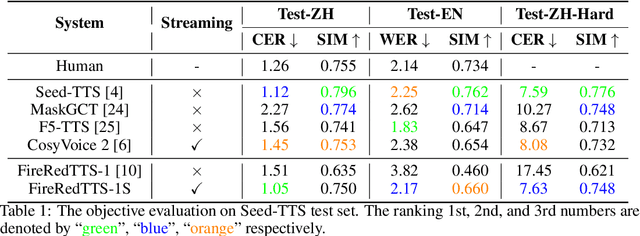
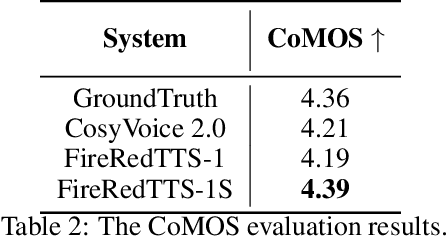
In this work, we propose a high-quality streaming foundation text-to-speech system, FireRedTTS-1S, upgraded from the streamable version of FireRedTTS. FireRedTTS-1S achieves streaming generation via two steps: text-to-semantic decoding and semantic-to-acoustic decoding. In text-to-semantic decoding, a semantic-aware speech tokenizer converts the speech signal into semantic tokens, which can be synthesized from the text via a semantic language model in an auto-regressive manner. Meanwhile, the semantic-to-acoustic decoding module simultaneously translates generated semantic tokens into the speech signal in a streaming way via a super-resolution causal audio codec and a multi-stream acoustic language model. This design enables us to produce high-quality speech audio in zero-shot settings while presenting a real-time generation process with low latency under 150ms. In experiments on zero-shot voice cloning, the objective results validate FireRedTTS-1S as a high-quality foundation model with comparable intelligibility and speaker similarity over industrial baseline systems. Furthermore, the subjective score of FireRedTTS-1S highlights its impressive synthesis performance, achieving comparable quality to the ground-truth recordings. These results validate FireRedTTS-1S as a high-quality streaming foundation TTS system.
FireRedASR: Open-Source Industrial-Grade Mandarin Speech Recognition Models from Encoder-Decoder to LLM Integration
Jan 24, 2025



We present FireRedASR, a family of large-scale automatic speech recognition (ASR) models for Mandarin, designed to meet diverse requirements in superior performance and optimal efficiency across various applications. FireRedASR comprises two variants: FireRedASR-LLM: Designed to achieve state-of-the-art (SOTA) performance and to enable seamless end-to-end speech interaction. It adopts an Encoder-Adapter-LLM framework leveraging large language model (LLM) capabilities. On public Mandarin benchmarks, FireRedASR-LLM (8.3B parameters) achieves an average Character Error Rate (CER) of 3.05%, surpassing the latest SOTA of 3.33% with an 8.4% relative CER reduction (CERR). It demonstrates superior generalization capability over industrial-grade baselines, achieving 24%-40% CERR in multi-source Mandarin ASR scenarios such as video, live, and intelligent assistant. FireRedASR-AED: Designed to balance high performance and computational efficiency and to serve as an effective speech representation module in LLM-based speech models. It utilizes an Attention-based Encoder-Decoder (AED) architecture. On public Mandarin benchmarks, FireRedASR-AED (1.1B parameters) achieves an average CER of 3.18%, slightly worse than FireRedASR-LLM but still outperforming the latest SOTA model with over 12B parameters. It offers a more compact size, making it suitable for resource-constrained applications. Moreover, both models exhibit competitive results on Chinese dialects and English speech benchmarks and excel in singing lyrics recognition. To advance research in speech processing, we release our models and inference code at https://github.com/FireRedTeam/FireRedASR.
FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications
Sep 05, 2024



This work proposes FireRedTTS, a foundation text-to-speech framework, to meet the growing demands for personalized and diverse generative speech applications. The framework comprises three parts: data processing, foundation system, and downstream applications. First, we comprehensively present our data processing pipeline, which transforms massive raw audio into a large-scale high-quality TTS dataset with rich annotations and a wide coverage of content, speaking style, and timbre. Then, we propose a language-model-based foundation TTS system. The speech signal is compressed into discrete semantic tokens via a semantic-aware speech tokenizer, and can be generated by a language model from the prompt text and audio. Then, a two-stage waveform generator is proposed to decode them to the high-fidelity waveform. We present two applications of this system: voice cloning for dubbing and human-like speech generation for chatbots. The experimental results demonstrate the solid in-context learning capability of FireRedTTS, which can stably synthesize high-quality speech consistent with the prompt text and audio. For dubbing, FireRedTTS can clone target voices in a zero-shot way for the UGC scenario and adapt to studio-level expressive voice characters in the PUGC scenario via few-shot fine-tuning with 1-hour recording. Moreover, FireRedTTS achieves controllable human-like speech generation in a casual style with paralinguistic behaviors and emotions via instruction tuning, to better serve spoken chatbots.