 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System
Mar 26, 2025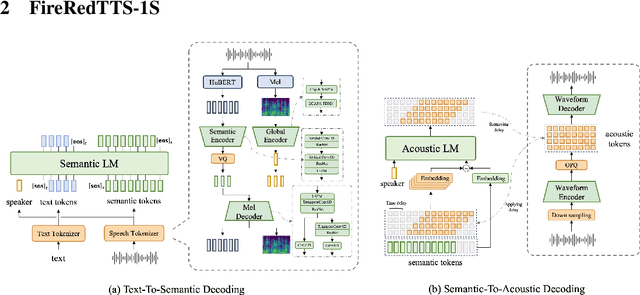
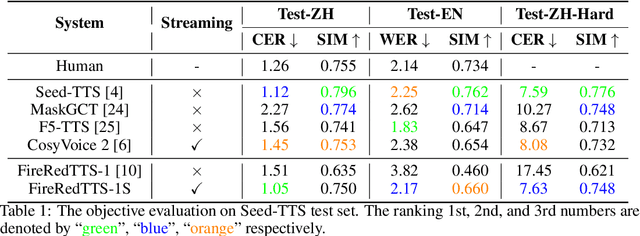
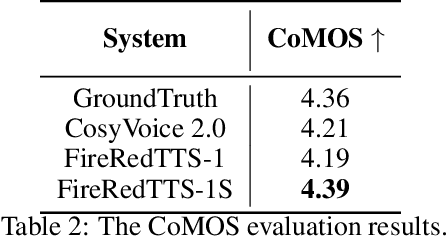
In this work, we propose a high-quality streaming foundation text-to-speech system, FireRedTTS-1S, upgraded from the streamable version of FireRedTTS. FireRedTTS-1S achieves streaming generation via two steps: text-to-semantic decoding and semantic-to-acoustic decoding. In text-to-semantic decoding, a semantic-aware speech tokenizer converts the speech signal into semantic tokens, which can be synthesized from the text via a semantic language model in an auto-regressive manner. Meanwhile, the semantic-to-acoustic decoding module simultaneously translates generated semantic tokens into the speech signal in a streaming way via a super-resolution causal audio codec and a multi-stream acoustic language model. This design enables us to produce high-quality speech audio in zero-shot settings while presenting a real-time generation process with low latency under 150ms. In experiments on zero-shot voice cloning, the objective results validate FireRedTTS-1S as a high-quality foundation model with comparable intelligibility and speaker similarity over industrial baseline systems. Furthermore, the subjective score of FireRedTTS-1S highlights its impressive synthesis performance, achieving comparable quality to the ground-truth recordings. These results validate FireRedTTS-1S as a high-quality streaming foundation TTS system.
Deep Convolutional Neural Networks on Multiclass Classification of Three-Dimensional Brain Images for Parkinson's Disease Stage Prediction
Oct 31, 2024



Parkinson's disease (PD), a degenerative disorder of the central nervous system, is commonly diagnosed using functional medical imaging techniques such as single-photon emission computed tomography (SPECT). In this study, we utilized two SPECT data sets (n = 634 and n = 202) from different hospitals to develop a model capable of accurately predicting PD stages, a multiclass classification task. We used the entire three-dimensional (3D) brain images as input and experimented with various model architectures. Initially, we treated the 3D images as sequences of two-dimensional (2D) slices and fed them sequentially into 2D convolutional neural network (CNN) models pretrained on ImageNet, averaging the outputs to obtain the final predicted stage. We also applied 3D CNN models pretrained on Kinetics-400. Additionally, we incorporated an attention mechanism to account for the varying importance of different slices in the prediction process. To further enhance model efficacy and robustness, we simultaneously trained the two data sets using weight sharing, a technique known as cotraining. Our results demonstrated that 2D models pretrained on ImageNet outperformed 3D models pretrained on Kinetics-400, and models utilizing the attention mechanism outperformed both 2D and 3D models. The cotraining technique proved effective in improving model performance when the cotraining data sets were sufficiently large.
FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications
Sep 05, 2024



This work proposes FireRedTTS, a foundation text-to-speech framework, to meet the growing demands for personalized and diverse generative speech applications. The framework comprises three parts: data processing, foundation system, and downstream applications. First, we comprehensively present our data processing pipeline, which transforms massive raw audio into a large-scale high-quality TTS dataset with rich annotations and a wide coverage of content, speaking style, and timbre. Then, we propose a language-model-based foundation TTS system. The speech signal is compressed into discrete semantic tokens via a semantic-aware speech tokenizer, and can be generated by a language model from the prompt text and audio. Then, a two-stage waveform generator is proposed to decode them to the high-fidelity waveform. We present two applications of this system: voice cloning for dubbing and human-like speech generation for chatbots. The experimental results demonstrate the solid in-context learning capability of FireRedTTS, which can stably synthesize high-quality speech consistent with the prompt text and audio. For dubbing, FireRedTTS can clone target voices in a zero-shot way for the UGC scenario and adapt to studio-level expressive voice characters in the PUGC scenario via few-shot fine-tuning with 1-hour recording. Moreover, FireRedTTS achieves controllable human-like speech generation in a casual style with paralinguistic behaviors and emotions via instruction tuning, to better serve spoken chatbots.