 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System
Paper and Code
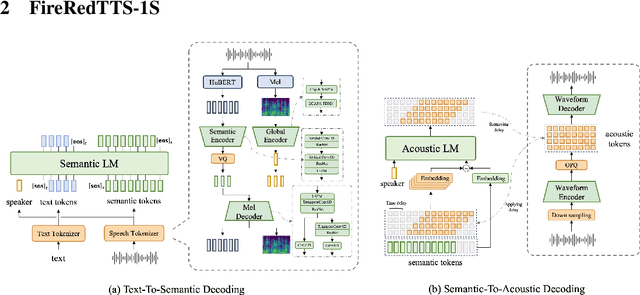
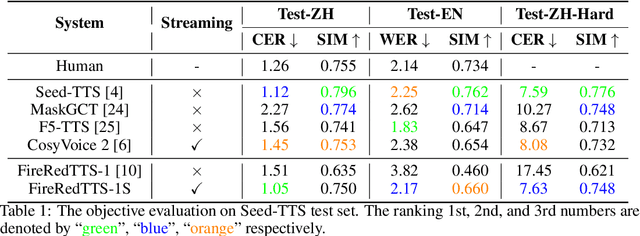
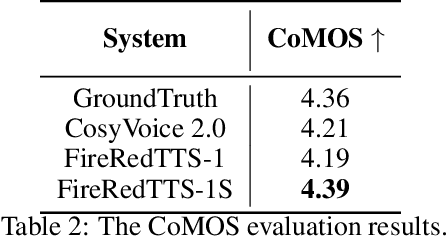
In this work, we propose a high-quality streaming foundation text-to-speech system, FireRedTTS-1S, upgraded from the streamable version of FireRedTTS. FireRedTTS-1S achieves streaming generation via two steps: text-to-semantic decoding and semantic-to-acoustic decoding. In text-to-semantic decoding, a semantic-aware speech tokenizer converts the speech signal into semantic tokens, which can be synthesized from the text via a semantic language model in an auto-regressive manner. Meanwhile, the semantic-to-acoustic decoding module simultaneously translates generated semantic tokens into the speech signal in a streaming way via a super-resolution causal audio codec and a multi-stream acoustic language model. This design enables us to produce high-quality speech audio in zero-shot settings while presenting a real-time generation process with low latency under 150ms. In experiments on zero-shot voice cloning, the objective results validate FireRedTTS-1S as a high-quality foundation model with comparable intelligibility and speaker similarity over industrial baseline systems. Furthermore, the subjective score of FireRedTTS-1S highlights its impressive synthesis performance, achieving comparable quality to the ground-truth recordings. These results validate FireRedTTS-1S as a high-quality streaming foundation TTS system.