 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSCMHMST: A traffic flow prediction model based on Transformer
Mar 16, 2025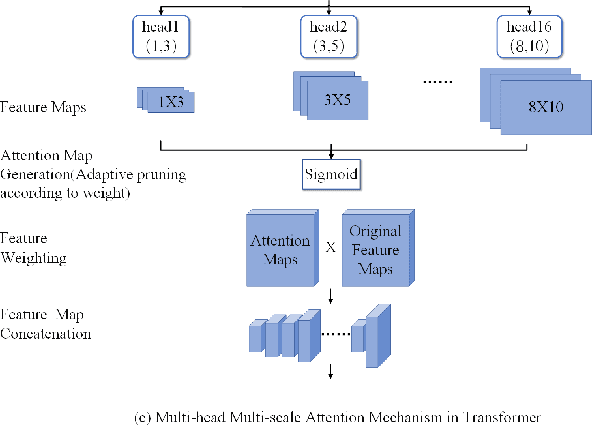
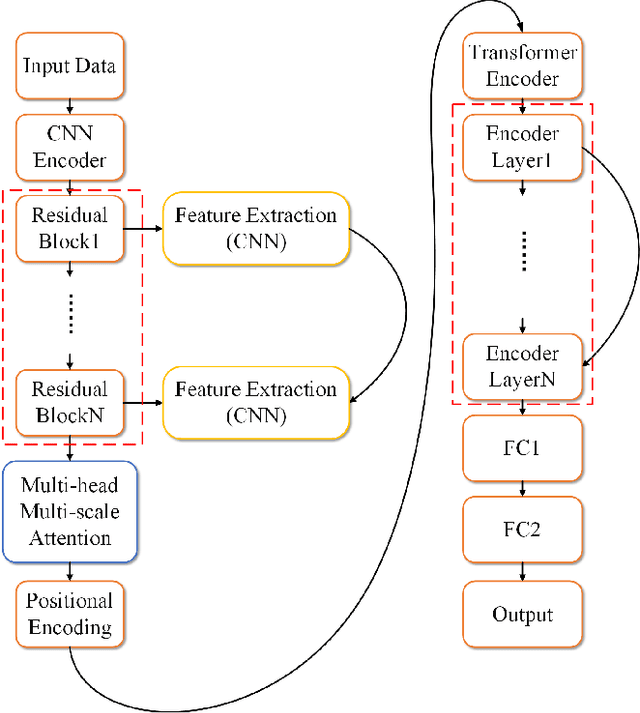
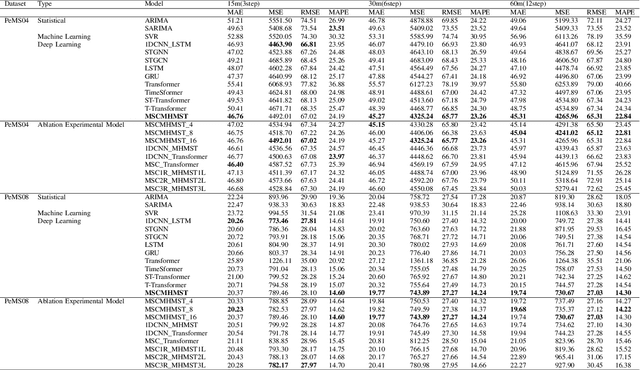
This study proposes a hybrid model based on Transformers, named MSCMHMST, aimed at addressing key challenges in traffic flow prediction. Traditional single-method approaches show limitations in traffic prediction tasks, whereas hybrid methods, by integrating the strengths of different models, can provide more accurate and robust predictions. The MSCMHMST model introduces a multi-head, multi-scale attention mechanism, allowing the model to parallel process different parts of the data and learn its intrinsic representations from multiple perspectives, thereby enhancing the model's ability to handle complex situations. This mechanism enables the model to capture features at various scales effectively, understanding both short-term changes and long-term trends. Verified through experiments on the PeMS04/08 dataset with specific experimental settings, the MSCMHMST model demonstrated excellent robustness and accuracy in long, medium, and short-term traffic flow predictions. The results indicate that this model has significant potential, offering a new and effective solution for the field of traffic flow prediction.
Drone Data Analytics for Measuring Traffic Metrics at Intersections in High-Density Areas
Nov 04, 2024This study employed over 100 hours of high-altitude drone video data from eight intersections in Hohhot to generate a unique and extensive dataset encompassing high-density urban road intersections in China. This research has enhanced the YOLOUAV model to enable precise target recognition on unmanned aerial vehicle (UAV) datasets. An automated calibration algorithm is presented to create a functional dataset in high-density traffic flows, which saves human and material resources. This algorithm can capture up to 200 vehicles per frame while accurately tracking over 1 million road users, including cars, buses, and trucks. Moreover, the dataset has recorded over 50,000 complete lane changes. It is the largest publicly available road user trajectories in high-density urban intersections. Furthermore, this paper updates speed and acceleration algorithms based on UAV elevation and implements a UAV offset correction algorithm. A case study demonstrates the usefulness of the proposed methods, showing essential parameters to evaluate intersections and traffic conditions in traffic engineering. The model can track more than 200 vehicles of different types simultaneously in highly dense traffic on an urban intersection in Hohhot, generating heatmaps based on spatial-temporal traffic flow data and locating traffic conflicts by conducting lane change analysis and surrogate measures. With the diverse data and high accuracy of results, this study aims to advance research and development of UAVs in transportation significantly. The High-Density Intersection Dataset is available for download at https://github.com/Qpu523/High-density-Intersection-Dataset.
Real-Time Vehicle Detection and Urban Traffic Behavior Analysis Based on UAV Traffic Videos on Mobile Devices
Feb 26, 2024This paper focuses on a real-time vehicle detection and urban traffic behavior analysis system based on Unmanned Aerial Vehicle (UAV) traffic video. By using UAV to collect traffic data and combining the YOLOv8 model and SORT tracking algorithm, the object detection and tracking functions are implemented on the iOS mobile platform. For the problem of traffic data acquisition and analysis, the dynamic computing method is used to process the performance in real time and calculate the micro and macro traffic parameters of the vehicles, and real-time traffic behavior analysis is conducted and visualized. The experiment results reveals that the vehicle object detection can reach 98.27% precision rate and 87.93% recall rate, and the real-time processing capacity is stable at 30 frames per seconds. This work integrates drone technology, iOS development, and deep learning techniques to integrate traffic video acquisition, object detection, object tracking, and traffic behavior analysis functions on mobile devices. It provides new possibilities for lightweight traffic information collection and data analysis, and offers innovative solutions to improve the efficiency of analyzing road traffic conditions and addressing transportation issues for transportation authorities.
Deep Q-Network Based Decision Making for Autonomous Driving
Mar 21, 2023Currently decision making is one of the biggest challenges in autonomous driving. This paper introduces a method for safely navigating an autonomous vehicle in highway scenarios by combining deep Q-Networks and insight from control theory. A Deep Q-Network is trained in simulation to serve as a central decision-making unit by proposing targets for a trajectory planner. The generated trajectories in combination with a controller for longitudinal movement are used to execute lane change maneuvers. In order to prove the functionality of this approach it is evaluated on two different highway traffic scenarios. Furthermore, the impact of different state representations on the performance and training process is analyzed. The results show that the proposed system can produce efficient and safe driving behavior.
MFPP: Morphological Fragmental Perturbation Pyramid for Black-Box Model Explanations
Jun 04, 2020
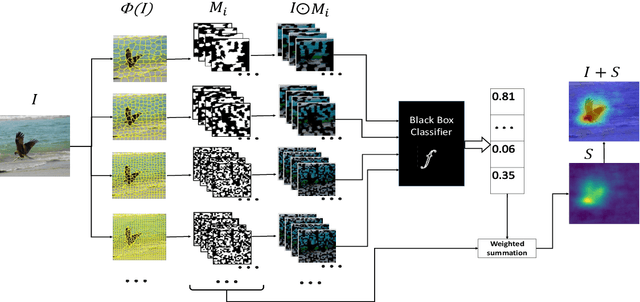
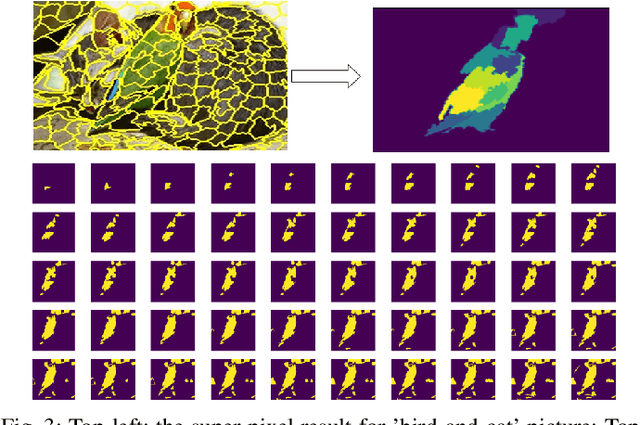
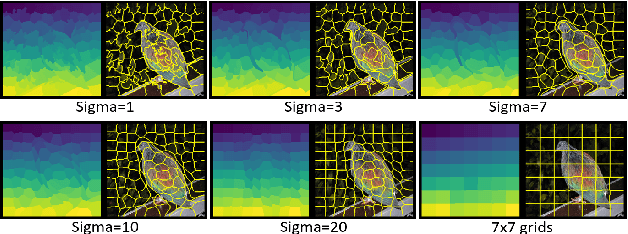
With the increasing popularity of deep neural networks (DNNs), it has recently been applied to many advanced and diverse tasks, such as medical diagnosis, automatic pilot etc. Due to the lack of transparency of the deep models, it causes serious concern about widespread deployment of ML/DL technologies. In this work, we address the Explainable AI problem of black-box classifiers which take images as input and output probabilities of classes. We propose a novel technology, the Morphological Fragmental Perturbation Pyramid (MFPP), in which we segment input image into different scales of fragments and randomly mask them as perturbation to generate an importance map that indicates how salient each pixel is for prediction results of the black-box DNNs. Compared to existing input sampling perturbation methods, this pyramid structure fragmentation has proven to be more efficient and it can better explore the morphological information of input image to match its semantic information, while it does not require any values inside model. We qualitatively and quantitatively demonstrate that MFPP matches and exceeds the performance of state-of-the-art black-box explanation methods on multiple models and datasets.
PipeNet: Selective Modal Pipeline of Fusion Network for Multi-Modal Face Anti-Spoofing
Apr 24, 2020


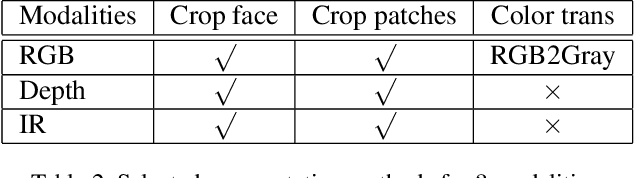
Face anti-spoofing has become an increasingly important and critical security feature for authentication systems, due to rampant and easily launchable presentation attacks. Addressing the shortage of multi-modal face dataset, CASIA recently released the largest up-to-date CASIA-SURF Cross-ethnicity Face Anti-spoofing(CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types in four protocols, and focusing on the challenge of improving the generalization capability of face anti-spoofing in cross-ethnicity and multi-modal continuous data. In this paper, we propose a novel pipeline-based multi-stream CNN architecture called PipeNet for multi-modal face anti-spoofing. Unlike previous works, Selective Modal Pipeline (SMP) is designed to enable a customized pipeline for each data modality to take full advantage of multi-modal data. Limited Frame Vote (LFV) is designed to ensure stable and accurate prediction for video classification. The proposed method wins the third place in the final ranking of Chalearn Multi-modal Cross-ethnicity Face Anti-spoofing Recognition Challenge@CVPR2020. Our final submission achieves the Average Classification Error Rate (ACER) of 2.21 with Standard Deviation of 1.26 on the test set.
Channel Pruning via Optimal Thresholding
Mar 12, 2020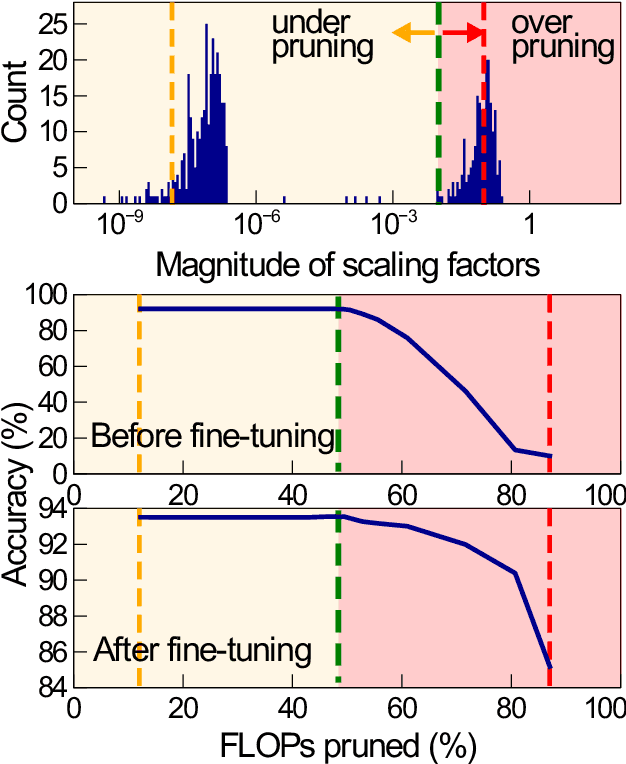
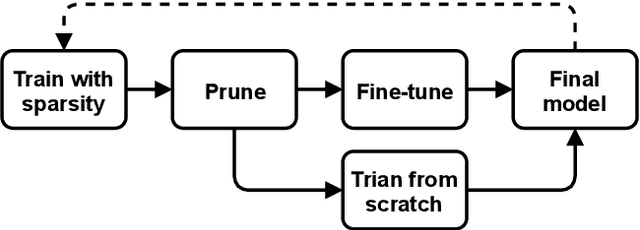
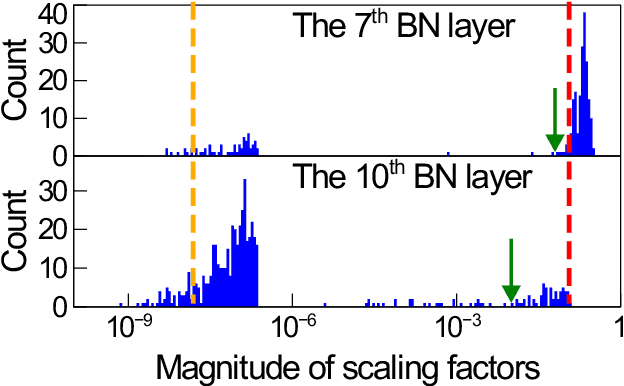
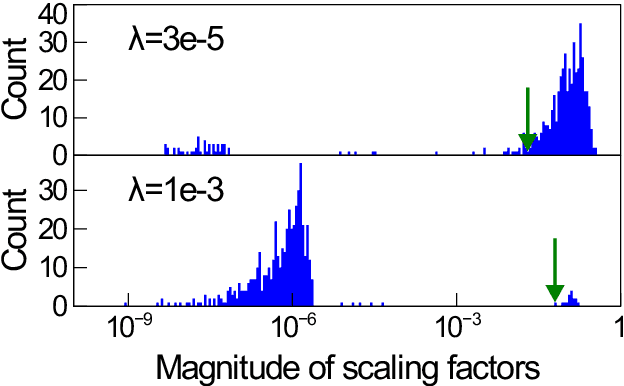
Structured pruning, especially channel pruning is widely used for the reduced computational cost and the compatibility with off-the-shelf hardware devices. Among existing works, weights are typically removed using a predefined global threshold, or a threshold computed from a predefined metric. The predefined global threshold based designs ignore the variation among different layers and weights distribution, therefore, they may often result in sub-optimal performance caused by over-pruning or under-pruning. In this paper, we present a simple yet effective method, termed Optimal Thresholding (OT), to prune channels with layer dependent thresholds that optimally separate important from negligible channels. By using OT, most negligible or unimportant channels are pruned to achieve high sparsity while minimizing performance degradation. Since most important weights are preserved, the pruned model can be further fine-tuned and quickly converge with very few iterations. Our method demonstrates superior performance, especially when compared to the state-of-the-art designs at high levels of sparsity. On CIFAR-100, a pruned and fine-tuned DenseNet-121 by using OT achieves 75.99% accuracy with only 1.46e8 FLOPs and 0.71M parameters. code is available at: https://github.com/yeyun11/netslim.