 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeNet: Selective Modal Pipeline of Fusion Network for Multi-Modal Face Anti-Spoofing
Paper and Code
Apr 24, 2020


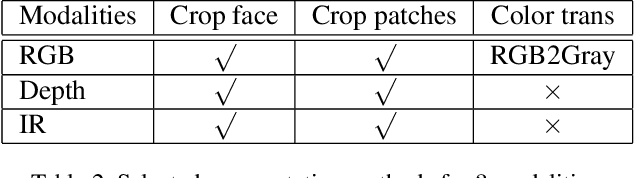
Face anti-spoofing has become an increasingly important and critical security feature for authentication systems, due to rampant and easily launchable presentation attacks. Addressing the shortage of multi-modal face dataset, CASIA recently released the largest up-to-date CASIA-SURF Cross-ethnicity Face Anti-spoofing(CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types in four protocols, and focusing on the challenge of improving the generalization capability of face anti-spoofing in cross-ethnicity and multi-modal continuous data. In this paper, we propose a novel pipeline-based multi-stream CNN architecture called PipeNet for multi-modal face anti-spoofing. Unlike previous works, Selective Modal Pipeline (SMP) is designed to enable a customized pipeline for each data modality to take full advantage of multi-modal data. Limited Frame Vote (LFV) is designed to ensure stable and accurate prediction for video classification. The proposed method wins the third place in the final ranking of Chalearn Multi-modal Cross-ethnicity Face Anti-spoofing Recognition Challenge@CVPR2020. Our final submission achieves the Average Classification Error Rate (ACER) of 2.21 with Standard Deviation of 1.26 on the test set.