 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAug3D: Augmenting large scale outdoor datasets for Generalizable Novel View Synthesis
Jan 11, 2025Recent photorealistic Novel View Synthesis (NVS) advances have increasingly gained attention. However, these approaches remain constrained to small indoor scenes. While optimization-based NVS models have attempted to address this, generalizable feed-forward methods, offering significant advantages, remain underexplored. In this work, we train PixelNeRF, a feed-forward NVS model, on the large-scale UrbanScene3D dataset. We propose four training strategies to cluster and train on this dataset, highlighting that performance is hindered by limited view overlap. To address this, we introduce Aug3D, an augmentation technique that leverages reconstructed scenes using traditional Structure-from-Motion (SfM). Aug3D generates well-conditioned novel views through grid and semantic sampling to enhance feed-forward NVS model learning. Our experiments reveal that reducing the number of views per cluster from 20 to 10 improves PSNR by 10%, but the performance remains suboptimal. Aug3D further addresses this by combining the newly generated novel views with the original dataset, demonstrating its effectiveness in improving the model's ability to predict novel views.
CoCap: Coordinated motion Capture for multi-actor scenes in outdoor environments
Dec 30, 2024Motion capture has become increasingly important, not only in computer animation but also in emerging fields like the virtual reality, bioinformatics, and humanoid training. Capturing outdoor environments offers extended horizon scenes but introduces challenges with occlusions and obstacles. Recent approaches using multi-drone systems to capture multiple actor scenes often fail to account for multi-view consistency and reasoning across cameras in cluttered environments. Coordinated motion Capture (CoCap), inspired by Conflict-Based Search (CBS), addresses this issue by coordinating view planning to ensure multi-view reasoning during conflicts. In scenarios with high occlusions and obstacles, where the likelihood of inter-robot collisions increases, CoCap demonstrates performance that approaches the ideal outcomes of unconstrained planning, outperforming existing sequential planning methods. Additionally, CoCap offers a single-robot view search approach for real-time applications in dense environments.
Enhancing Multi-Drone Coordination for Filming Group Behaviours in Dynamic Environments
Oct 19, 2023



Multi-Agent Path Finding (MAPF) is a fundamental problem in robotics and AI, with numerous applications in real-world scenarios. One such scenario is filming scenes with multiple actors, where the goal is to capture the scene from multiple angles simultaneously. Here, we present a formation-based filming directive of task assignment followed by a Conflict-Based MAPF algorithm for efficient path planning of multiple agents to achieve filming objectives while avoiding collisions. We propose an extension to the standard MAPF formulation to accommodate actor-specific requirements and constraints. Our approach incorporates Conflict-Based Search, a widely used heuristic search technique for solving MAPF problems. We demonstrate the effectiveness of our approach through experiments on various MAPF scenarios in a simulated environment. The proposed algorithm enables the efficient online task assignment of formation-based filming to capture dynamic scenes, making it suitable for various filming and coverage applications.
Greedy Perspectives: Multi-Drone View Planning for Collaborative Coverage in Cluttered Environments
Oct 16, 2023

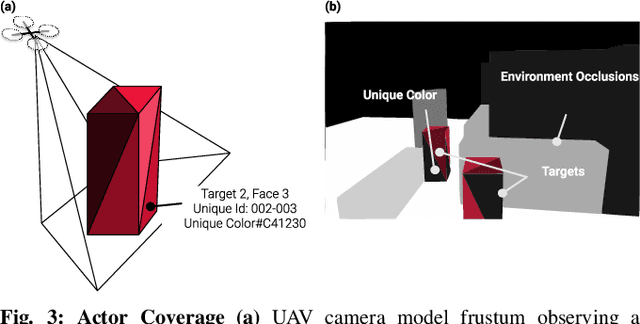

Deployment of teams of aerial robots could enable large-scale filming of dynamic groups of people (actors) in complex environments for novel applications in areas such as team sports and cinematography. Toward this end, methods for submodular maximization via sequential greedy planning can be used for scalable optimization of camera views across teams of robots but face challenges with efficient coordination in cluttered environments. Obstacles can produce occlusions and increase chances of inter-robot collision which can violate requirements for near-optimality guarantees. To coordinate teams of aerial robots in filming groups of people in dense environments, a more general view-planning approach is required. We explore how collision and occlusion impact performance in filming applications through the development of a multi-robot multi-actor view planner with an occlusion-aware objective for filming groups of people and compare with a greedy formation planner. To evaluate performance, we plan in five test environments with complex multiple-actor behaviors. Compared with a formation planner, our sequential planner generates 14% greater view reward over the actors for three scenarios and comparable performance to formation planning on two others. We also observe near identical performance of sequential planning both with and without inter-robot collision constraints. Overall, we demonstrate effective coordination of teams of aerial robots for filming groups that may split, merge, or spread apart and in environments cluttered with obstacles that may cause collisions or occlusions.