 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Safety: Language-Conditioned Safety Filtering for Robot Navigation
Nov 08, 2025As robots become increasingly integrated into open-world, human-centered environments, their ability to interpret natural language instructions and adhere to safety constraints is critical for effective and trustworthy interaction. Existing approaches often focus on mapping language to reward functions instead of safety specifications or address only narrow constraint classes (e.g., obstacle avoidance), limiting their robustness and applicability. We propose a modular framework for language-conditioned safety in robot navigation. Our framework is composed of three core components: (1) a large language model (LLM)-based module that translates free-form instructions into structured safety specifications, (2) a perception module that grounds these specifications by maintaining object-level 3D representations of the environment, and (3) a model predictive control (MPC)-based safety filter that enforces both semantic and geometric constraints in real time. We evaluate the effectiveness of the proposed framework through both simulation studies and hardware experiments, demonstrating that it robustly interprets and enforces diverse language-specified constraints across a wide range of environments and scenarios.
MADR: MPC-guided Adversarial DeepReach
Oct 21, 2025Hamilton-Jacobi (HJ) Reachability offers a framework for generating safe value functions and policies in the face of adversarial disturbance, but is limited by the curse of dimensionality. Physics-informed deep learning is able to overcome this infeasibility, but itself suffers from slow and inaccurate convergence, primarily due to weak PDE gradients and the complexity of self-supervised learning. A few works, recently, have demonstrated that enriching the self-supervision process with regular supervision (based on the nature of the optimal control problem), greatly accelerates convergence and solution quality, however, these have been limited to single player problems and simple games. In this work, we introduce MADR: MPC-guided Adversarial DeepReach, a general framework to robustly approximate the two-player, zero-sum differential game value function. In doing so, MADR yields the corresponding optimal strategies for both players in zero-sum games as well as safe policies for worst-case robustness. We test MADR on a multitude of high-dimensional simulated and real robotic agents with varying dynamics and games, finding that our approach significantly out-performs state-of-the-art baselines in simulation and produces impressive results in hardware.
Safety Evaluation of Motion Plans Using Trajectory Predictors as Forward Reachable Set Estimators
Jul 30, 2025

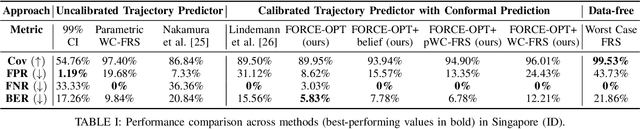

The advent of end-to-end autonomy stacks - often lacking interpretable intermediate modules - has placed an increased burden on ensuring that the final output, i.e., the motion plan, is safe in order to validate the safety of the entire stack. This requires a safety monitor that is both complete (able to detect all unsafe plans) and sound (does not flag safe plans). In this work, we propose a principled safety monitor that leverages modern multi-modal trajectory predictors to approximate forward reachable sets (FRS) of surrounding agents. By formulating a convex program, we efficiently extract these data-driven FRSs directly from the predicted state distributions, conditioned on scene context such as lane topology and agent history. To ensure completeness, we leverage conformal prediction to calibrate the FRS and guarantee coverage of ground-truth trajectories with high probability. To preserve soundness in out-of-distribution (OOD) scenarios or under predictor failure, we introduce a Bayesian filter that dynamically adjusts the FRS conservativeness based on the predictor's observed performance. We then assess the safety of the ego vehicle's motion plan by checking for intersections with these calibrated FRSs, ensuring the plan remains collision-free under plausible future behaviors of others. Extensive experiments on the nuScenes dataset show our approach significantly improves soundness while maintaining completeness, offering a practical and reliable safety monitor for learned autonomy stacks.
Bridging Model Predictive Control and Deep Learning for Scalable Reachability Analysis
May 04, 2025Hamilton-Jacobi (HJ) reachability analysis is a widely used method for ensuring the safety of robotic systems. Traditional approaches compute reachable sets by numerically solving an HJ Partial Differential Equation (PDE) over a grid, which is computationally prohibitive due to the curse of dimensionality. Recent learning-based methods have sought to address this challenge by approximating reachability solutions using neural networks trained with PDE residual error. However, these approaches often suffer from unstable training dynamics and suboptimal solutions due to the weak learning signal provided by the residual loss. In this work, we propose a novel approach that leverages model predictive control (MPC) techniques to guide and accelerate the reachability learning process. Observing that HJ reachability is inherently rooted in optimal control, we utilize MPC to generate approximate reachability solutions at key collocation points, which are then used to tactically guide the neural network training by ensuring compliance with these approximations. Moreover, we iteratively refine the MPC generated solutions using the learned reachability solution, mitigating convergence to local optima. Case studies on a 2D vertical drone, a 13D quadrotor, a 7D F1Tenth car, and a 40D publisher-subscriber system demonstrate that bridging MPC with deep learning yields significant improvements in the robustness and accuracy of reachable sets, as well as corresponding safety assurances, compared to existing methods.
System-Level Safety Monitoring and Recovery for Perception Failures in Autonomous Vehicles
Sep 26, 2024
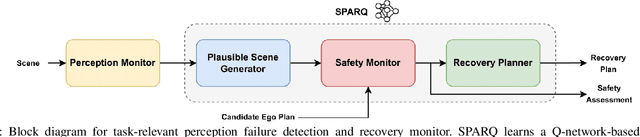
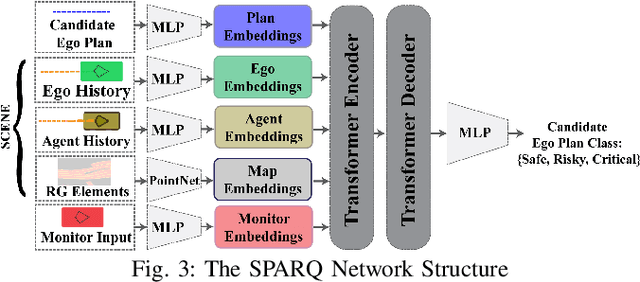
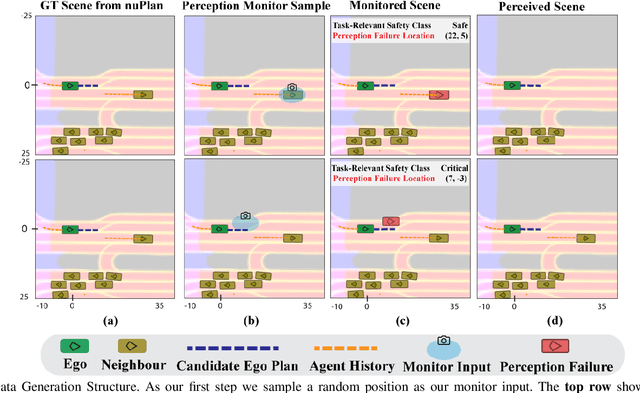
The safety-critical nature of autonomous vehicle (AV) operation necessitates development of task-relevant algorithms that can reason about safety at the system level and not just at the component level. To reason about the impact of a perception failure on the entire system performance, such task-relevant algorithms must contend with various challenges: complexity of AV stacks, high uncertainty in the operating environments, and the need for real-time performance. To overcome these challenges, in this work, we introduce a Q-network called SPARQ (abbreviation for Safety evaluation for Perception And Recovery Q-network) that evaluates the safety of a plan generated by a planning algorithm, accounting for perception failures that the planning process may have overlooked. This Q-network can be queried during system runtime to assess whether a proposed plan is safe for execution or poses potential safety risks. If a violation is detected, the network can then recommend a corrective plan while accounting for the perceptual failure. We validate our algorithm using the NuPlan-Vegas dataset, demonstrating its ability to handle cases where a perception failure compromises a proposed plan while the corrective plan remains safe. We observe an overall accuracy and recall of 90% while sustaining a frequency of 42Hz on the unseen testing dataset. We compare our performance to a popular reachability-based baseline and analyze some interesting properties of our approach in improving the safety properties of an AV pipeline.
SAFE-GIL: SAFEty Guided Imitation Learning
Apr 08, 2024Behavior Cloning is a popular approach to Imitation Learning, in which a robot observes an expert supervisor and learns a control policy. However, behavior cloning suffers from the "compounding error" problem - the policy errors compound as it deviates from the expert demonstrations and might lead to catastrophic system failures, limiting its use in safety-critical applications. On-policy data aggregation methods are able to address this issue at the cost of rolling out and repeated training of the imitation policy, which can be tedious and computationally prohibitive. We propose SAFE-GIL, an off-policy behavior cloning method that guides the expert via adversarial disturbance during data collection. The algorithm abstracts the imitation error as an adversarial disturbance in the system dynamics, injects it during data collection to expose the expert to safety critical states, and collects corrective actions. Our method biases training to more closely replicate expert behavior in safety-critical states and allows more variance in less critical states. We compare our method with several behavior cloning techniques and DAgger on autonomous navigation and autonomous taxiing tasks and show higher task success and safety, especially in low data regimes where the likelihood of error is higher, at a slight drop in the performance.
Imposing Exact Safety Specifications in Neural Reachable Tubes
Mar 31, 2024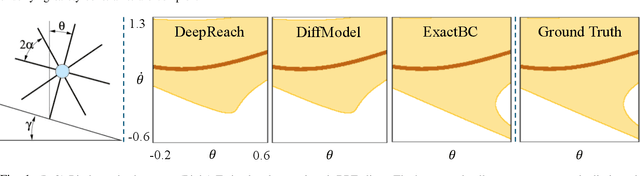
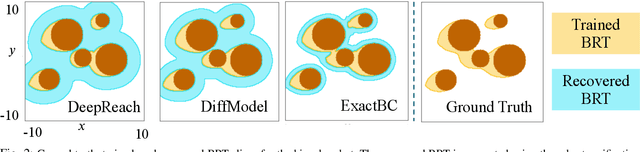
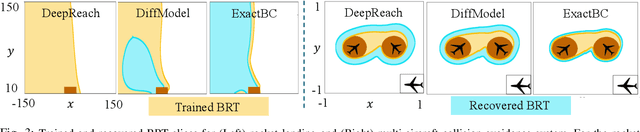

Hamilton-Jacobi (HJ) reachability analysis is a verification tool that provides safety and performance guarantees for autonomous systems. It is widely adopted because of its ability to handle nonlinear dynamical systems with bounded adversarial disturbances and constraints on states and inputs. However, it involves solving a PDE to compute a safety value function, whose computational and memory complexity scales exponentially with the state dimension, making its direct usage in large-scale systems intractable. Recently, a learning-based approach called DeepReach, has been proposed to approximate high-dimensional reachable tubes using neural networks. While DeepReach has been shown to be effective, the accuracy of the learned solution decreases with the increase in system complexity. One of the reasons for this degradation is the inexact imposition of safety constraints during the learning process, which corresponds to the PDE's boundary conditions. Specifically, DeepReach imposes boundary conditions as soft constraints in the loss function, which leaves room for error during the value function learning. Moreover, one needs to carefully adjust the relative contributions from the imposition of boundary conditions and the imposition of the PDE in the loss function. This, in turn, induces errors in the overall learned solution. In this work, we propose a variant of DeepReach that exactly imposes safety constraints during the learning process by restructuring the overall value function as a weighted sum of the boundary condition and neural network output. This eliminates the need for a boundary loss during training, thus bypassing the need for loss adjustment. We demonstrate the efficacy of the proposed approach in significantly improving the accuracy of learned solutions for challenging high-dimensional reachability tasks, such as rocket-landing and multivehicle collision-avoidance problems.