 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Evaluation of Motion Plans Using Trajectory Predictors as Forward Reachable Set Estimators
Jul 30, 2025

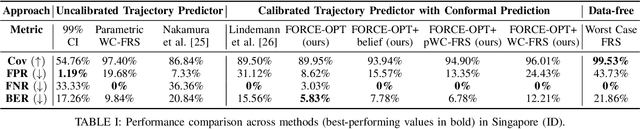

The advent of end-to-end autonomy stacks - often lacking interpretable intermediate modules - has placed an increased burden on ensuring that the final output, i.e., the motion plan, is safe in order to validate the safety of the entire stack. This requires a safety monitor that is both complete (able to detect all unsafe plans) and sound (does not flag safe plans). In this work, we propose a principled safety monitor that leverages modern multi-modal trajectory predictors to approximate forward reachable sets (FRS) of surrounding agents. By formulating a convex program, we efficiently extract these data-driven FRSs directly from the predicted state distributions, conditioned on scene context such as lane topology and agent history. To ensure completeness, we leverage conformal prediction to calibrate the FRS and guarantee coverage of ground-truth trajectories with high probability. To preserve soundness in out-of-distribution (OOD) scenarios or under predictor failure, we introduce a Bayesian filter that dynamically adjusts the FRS conservativeness based on the predictor's observed performance. We then assess the safety of the ego vehicle's motion plan by checking for intersections with these calibrated FRSs, ensuring the plan remains collision-free under plausible future behaviors of others. Extensive experiments on the nuScenes dataset show our approach significantly improves soundness while maintaining completeness, offering a practical and reliable safety monitor for learned autonomy stacks.
Refining Obstacle Perception Safety Zones via Maneuver-Based Decomposition
Aug 11, 2023



A critical task for developing safe autonomous driving stacks is to determine whether an obstacle is safety-critical, i.e., poses an imminent threat to the autonomous vehicle. Our previous work showed that Hamilton Jacobi reachability theory can be applied to compute interaction-dynamics-aware perception safety zones that better inform an ego vehicle's perception module which obstacles are considered safety-critical. For completeness, these zones are typically larger than absolutely necessary, forcing the perception module to pay attention to a larger collection of objects for the sake of conservatism. As an improvement, we propose a maneuver-based decomposition of our safety zones that leverages information about the ego maneuver to reduce the zone volume. In particular, we propose a "temporal convolution" operation that produces safety zones for specific ego maneuvers, thus limiting the ego's behavior to reduce the size of the safety zones. We show with numerical experiments that maneuver-based zones are significantly smaller (up to 76% size reduction) than the baseline while maintaining completeness.
Interaction-Dynamics-Aware Perception Zones for Obstacle Detection Safety Evaluation
Jun 24, 2022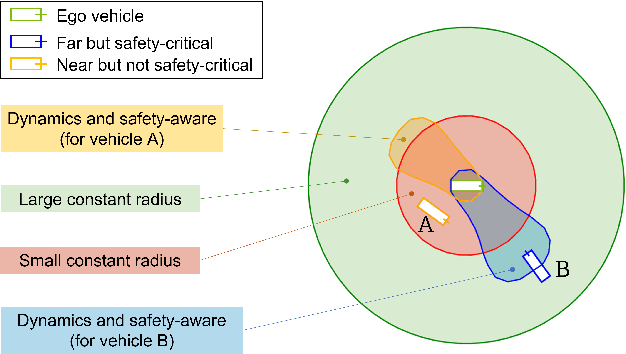
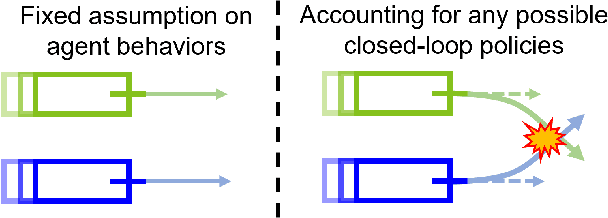
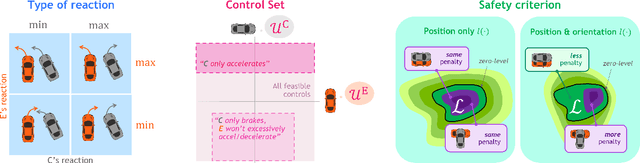
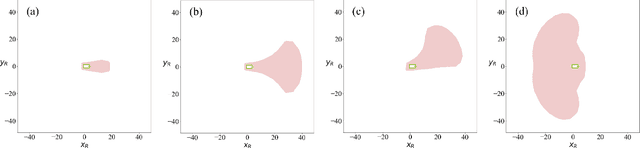
To enable safe autonomous vehicle (AV) operations, it is critical that an AV's obstacle detection module can reliably detect obstacles that pose a safety threat (i.e., are safety-critical). It is therefore desirable that the evaluation metric for the perception system captures the safety-criticality of objects. Unfortunately, existing perception evaluation metrics tend to make strong assumptions about the objects and ignore the dynamic interactions between agents, and thus do not accurately capture the safety risks in reality. To address these shortcomings, we introduce an interaction-dynamics-aware obstacle detection evaluation metric by accounting for closed-loop dynamic interactions between an ego vehicle and obstacles in the scene. By borrowing existing theory from optimal control theory, namely Hamilton-Jacobi reachability, we present a computationally tractable method for constructing a ``safety zone'': a region in state space that defines where safety-critical obstacles lie for the purpose of defining safety metrics. Our proposed safety zone is mathematically complete, and can be easily computed to reflect a variety of safety requirements. Using an off-the-shelf detection algorithm from the nuScenes detection challenge leaderboard, we demonstrate that our approach is computationally lightweight, and can better capture safety-critical perception errors than a baseline approach.
Techniques for Symbol Grounding with SATNet
Jun 16, 2021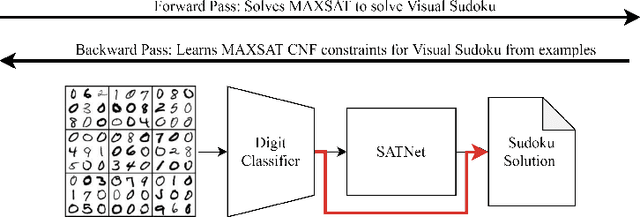

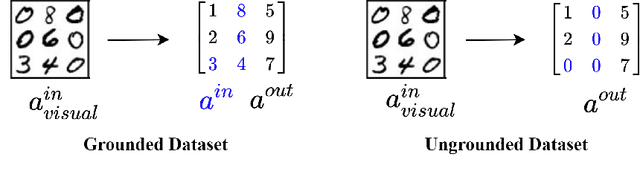

Many experts argue that the future of artificial intelligence is limited by the field's ability to integrate symbolic logical reasoning into deep learning architectures. The recently proposed differentiable MAXSAT solver, SATNet, was a breakthrough in its capacity to integrate with a traditional neural network and solve visual reasoning problems. For instance, it can learn the rules of Sudoku purely from image examples. Despite its success, SATNet was shown to succumb to a key challenge in neurosymbolic systems known as the Symbol Grounding Problem: the inability to map visual inputs to symbolic variables without explicit supervision ("label leakage"). In this work, we present a self-supervised pre-training pipeline that enables SATNet to overcome this limitation, thus broadening the class of problems that SATNet architectures can solve to include datasets where no intermediary labels are available at all. We demonstrate that our method allows SATNet to attain full accuracy even with a harder problem setup that prevents any label leakage. We additionally introduce a proofreading method that further improves the performance of SATNet architectures, beating the state-of-the-art on Visual Sudoku.