 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided Video Models
Dec 05, 2024
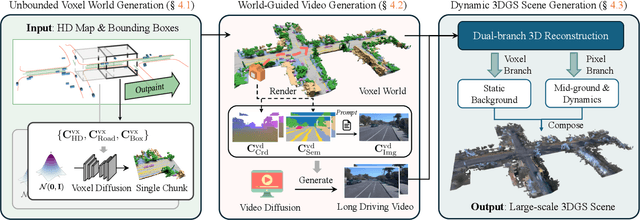
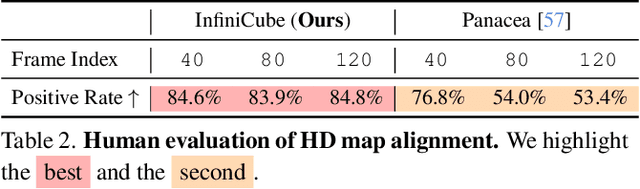
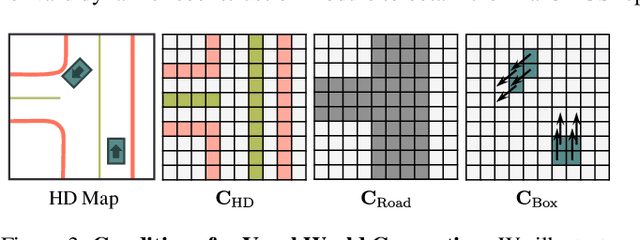
We present InfiniCube, a scalable method for generating unbounded dynamic 3D driving scenes with high fidelity and controllability. Previous methods for scene generation either suffer from limited scales or lack geometric and appearance consistency along generated sequences. In contrast, we leverage the recent advancements in scalable 3D representation and video models to achieve large dynamic scene generation that allows flexible controls through HD maps, vehicle bounding boxes, and text descriptions. First, we construct a map-conditioned sparse-voxel-based 3D generative model to unleash its power for unbounded voxel world generation. Then, we re-purpose a video model and ground it on the voxel world through a set of carefully designed pixel-aligned guidance buffers, synthesizing a consistent appearance. Finally, we propose a fast feed-forward approach that employs both voxel and pixel branches to lift the dynamic videos to dynamic 3D Gaussians with controllable objects. Our method can generate controllable and realistic 3D driving scenes, and extensive experiments validate the effectiveness and superiority of our model.
SCube: Instant Large-Scale Scene Reconstruction using VoxSplats
Oct 26, 2024



We present SCube, a novel method for reconstructing large-scale 3D scenes (geometry, appearance, and semantics) from a sparse set of posed images. Our method encodes reconstructed scenes using a novel representation VoxSplat, which is a set of 3D Gaussians supported on a high-resolution sparse-voxel scaffold. To reconstruct a VoxSplat from images, we employ a hierarchical voxel latent diffusion model conditioned on the input images followed by a feedforward appearance prediction model. The diffusion model generates high-resolution grids progressively in a coarse-to-fine manner, and the appearance network predicts a set of Gaussians within each voxel. From as few as 3 non-overlapping input images, SCube can generate millions of Gaussians with a 1024^3 voxel grid spanning hundreds of meters in 20 seconds. Past works tackling scene reconstruction from images either rely on per-scene optimization and fail to reconstruct the scene away from input views (thus requiring dense view coverage as input) or leverage geometric priors based on low-resolution models, which produce blurry results. In contrast, SCube leverages high-resolution sparse networks and produces sharp outputs from few views. We show the superiority of SCube compared to prior art using the Waymo self-driving dataset on 3D reconstruction and demonstrate its applications, such as LiDAR simulation and text-to-scene generation.
EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Oct 10, 2024
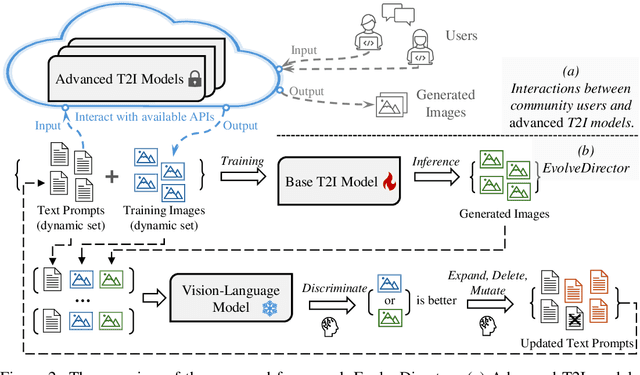

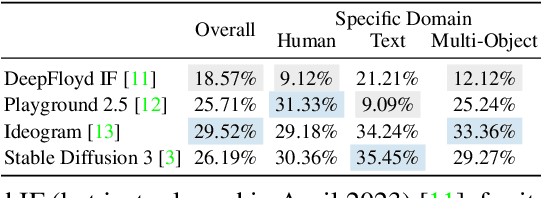
Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The code and model weights are available at https://github.com/showlab/EvolveDirector.
Occluded Prohibited Items Detection: An X-ray Security Inspection Benchmark and De-occlusion Attention Module
May 26, 2020
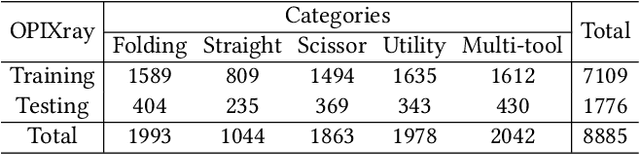
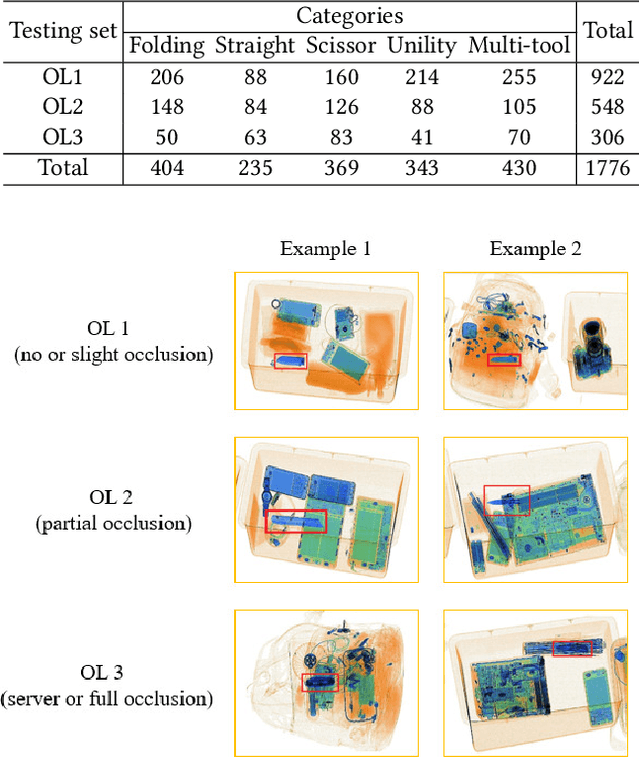
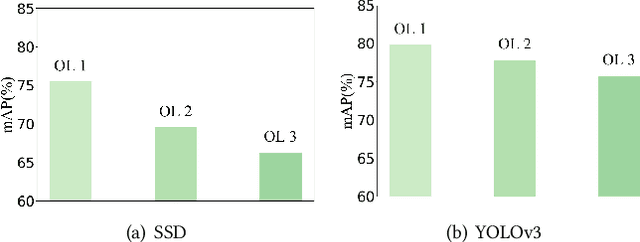
Security inspection often deals with a piece of baggage or suitcase where objects are heavily overlapped with each other, resulting in an unsatisfactory performance for prohibited items detection in X-ray images. In the literature, there have been rare studies and datasets touching this important topic. In this work, we contribute the first high-quality object detection dataset for security inspection, named Occluded Prohibited Items X-ray (OPIXray) image benchmark. OPIXray focused on the widely-occurred prohibited item "cutter", annotated manually by professional inspectors from the international airport. The test set is further divided into three occlusion levels to better understand the performance of detectors. Furthermore, to deal with the occlusion in X-ray images detection, we propose the De-occlusion Attention Module (DOAM), a plug-and-play module that can be easily inserted into and thus promote most popular detectors. Despite the heavy occlusion in X-ray imaging, shape appearance of objects can be preserved well, and meanwhile different materials visually appear with different colors and textures. Motivated by these observations, our DOAM simultaneously leverages the different appearance information of the prohibited item to generate the attention map, which helps refine feature maps for the general detectors. We comprehensively evaluate our module on the OPIXray dataset, and demonstrate that our module can consistently improve the performance of the state-of-the-art detection methods such as SSD, FCOS, etc, and significantly outperforms several widely-used attention mechanisms. In particular, the advantages of DOAM are more significant in the scenarios with higher levels of occlusion, which demonstrates its potential application in real-world inspections. The OPIXray benchmark and our model are released at https://github.com/OPIXray-author/OPIXray.