 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided Video Models
Paper and Code

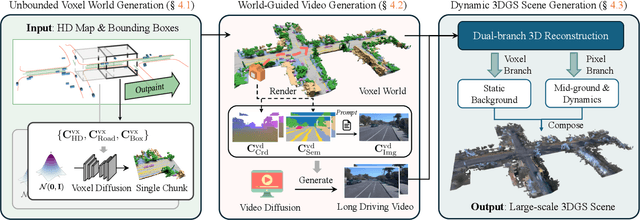
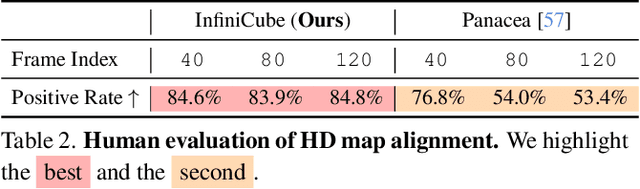
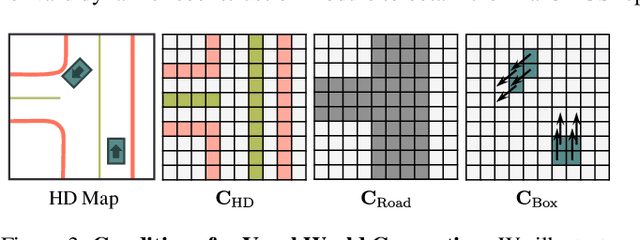
We present InfiniCube, a scalable method for generating unbounded dynamic 3D driving scenes with high fidelity and controllability. Previous methods for scene generation either suffer from limited scales or lack geometric and appearance consistency along generated sequences. In contrast, we leverage the recent advancements in scalable 3D representation and video models to achieve large dynamic scene generation that allows flexible controls through HD maps, vehicle bounding boxes, and text descriptions. First, we construct a map-conditioned sparse-voxel-based 3D generative model to unleash its power for unbounded voxel world generation. Then, we re-purpose a video model and ground it on the voxel world through a set of carefully designed pixel-aligned guidance buffers, synthesizing a consistent appearance. Finally, we propose a fast feed-forward approach that employs both voxel and pixel branches to lift the dynamic videos to dynamic 3D Gaussians with controllable objects. Our method can generate controllable and realistic 3D driving scenes, and extensive experiments validate the effectiveness and superiority of our model.