 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRINT Enables Interpretable and Ultra-Fast Virtual Screening against Thousands of Proteomes
Nov 23, 2024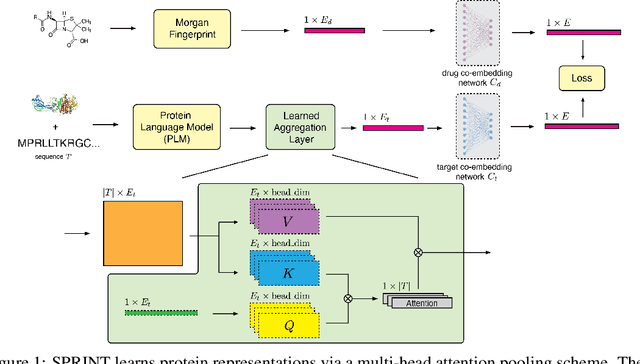


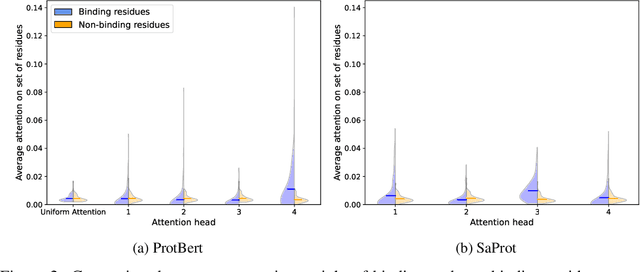
Virtual screening of small molecules against protein targets can accelerate drug discovery and development by predicting drug-target interactions (DTIs). However, structure-based methods like molecular docking are too slow to allow for broad proteome-scale screens, limiting their application in screening for off-target effects or new molecular mechanisms. Recently, vector-based methods using protein language models (PLMs) have emerged as a complementary approach that bypasses explicit 3D structure modeling. Here, we develop SPRINT, a vector-based approach for screening entire chemical libraries against whole proteomes for DTIs and novel mechanisms of action. SPRINT improves on prior work by using a self-attention based architecture and structure-aware PLMs to learn drug-target co-embeddings for binder prediction, search, and retrieval. SPRINT achieves SOTA enrichment factors in virtual screening on LIT-PCBA and DTI classification benchmarks, while providing interpretability in the form of residue-level attention maps. In addition to being both accurate and interpretable, SPRINT is ultra-fast: querying the whole human proteome against the ENAMINE Real Database (6.7B drugs) for the 100 most likely binders per protein takes 16 minutes. SPRINT promises to enable virtual screening at an unprecedented scale, opening up new opportunities for in silico drug repurposing and development. SPRINT is available on the web as ColabScreen: https://bit.ly/colab-screen
Contextualized Machine Learning
Oct 17, 2023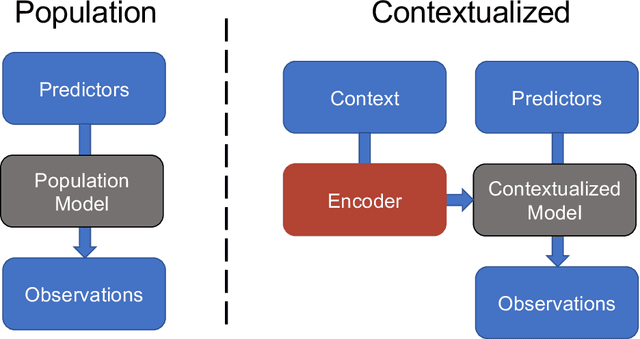
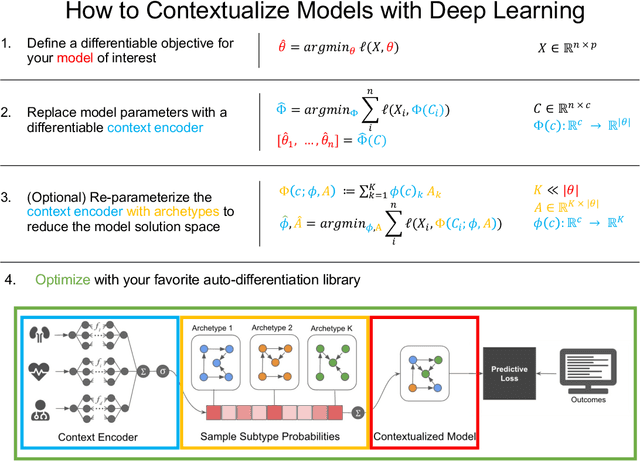

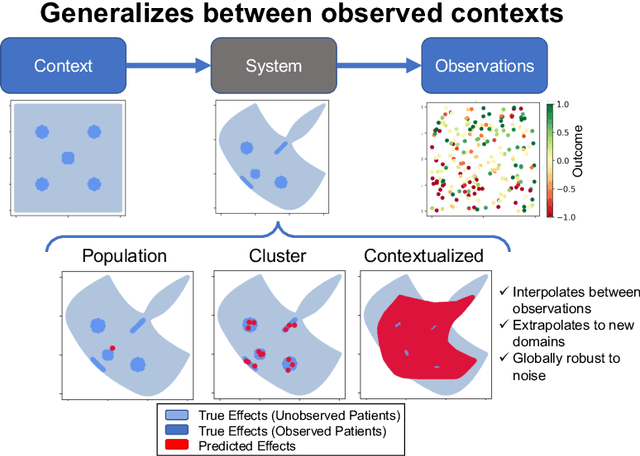
We examine Contextualized Machine Learning (ML), a paradigm for learning heterogeneous and context-dependent effects. Contextualized ML estimates heterogeneous functions by applying deep learning to the meta-relationship between contextual information and context-specific parametric models. This is a form of varying-coefficient modeling that unifies existing frameworks including cluster analysis and cohort modeling by introducing two reusable concepts: a context encoder which translates sample context into model parameters, and sample-specific model which operates on sample predictors. We review the process of developing contextualized models, nonparametric inference from contextualized models, and identifiability conditions of contextualized models. Finally, we present the open-source PyTorch package ContextualizedML.
Contextualized Policy Recovery: Modeling and Interpreting Medical Decisions with Adaptive Imitation Learning
Oct 11, 2023Interpretable policy learning seeks to estimate intelligible decision policies from observed actions; however, existing models fall short by forcing a tradeoff between accuracy and interpretability. This tradeoff limits data-driven interpretations of human decision-making process. e.g. to audit medical decisions for biases and suboptimal practices, we require models of decision processes which provide concise descriptions of complex behaviors. Fundamentally, existing approaches are burdened by this tradeoff because they represent the underlying decision process as a universal policy, when in fact human decisions are dynamic and can change drastically with contextual information. Thus, we propose Contextualized Policy Recovery (CPR), which re-frames the problem of modeling complex decision processes as a multi-task learning problem in which complex decision policies are comprised of context-specific policies. CPR models each context-specific policy as a linear observation-to-action mapping, and generates new decision models $\textit{on-demand}$ as contexts are updated with new observations. CPR is compatible with fully offline and partially observable decision environments, and can be tailored to incorporate any recurrent black-box model or interpretable decision model. We assess CPR through studies on simulated and real data, achieving state-of-the-art performance on the canonical tasks of predicting antibiotic prescription in intensive care units ($+22\%$ AUROC vs. previous SOTA) and predicting MRI prescription for Alzheimer's patients ($+7.7\%$ AUROC vs. previous SOTA). With this improvement in predictive performance, CPR closes the accuracy gap between interpretable and black-box methods for policy learning, allowing high-resolution exploration and analysis of context-specific decision models.