 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRINT Enables Interpretable and Ultra-Fast Virtual Screening against Thousands of Proteomes
Nov 23, 2024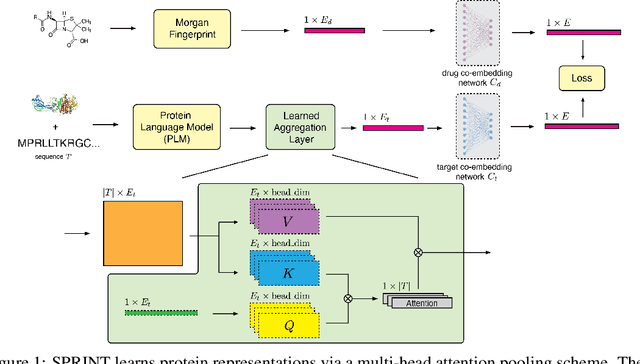


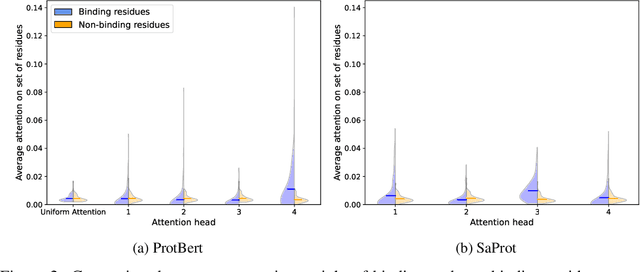
Virtual screening of small molecules against protein targets can accelerate drug discovery and development by predicting drug-target interactions (DTIs). However, structure-based methods like molecular docking are too slow to allow for broad proteome-scale screens, limiting their application in screening for off-target effects or new molecular mechanisms. Recently, vector-based methods using protein language models (PLMs) have emerged as a complementary approach that bypasses explicit 3D structure modeling. Here, we develop SPRINT, a vector-based approach for screening entire chemical libraries against whole proteomes for DTIs and novel mechanisms of action. SPRINT improves on prior work by using a self-attention based architecture and structure-aware PLMs to learn drug-target co-embeddings for binder prediction, search, and retrieval. SPRINT achieves SOTA enrichment factors in virtual screening on LIT-PCBA and DTI classification benchmarks, while providing interpretability in the form of residue-level attention maps. In addition to being both accurate and interpretable, SPRINT is ultra-fast: querying the whole human proteome against the ENAMINE Real Database (6.7B drugs) for the 100 most likely binders per protein takes 16 minutes. SPRINT promises to enable virtual screening at an unprecedented scale, opening up new opportunities for in silico drug repurposing and development. SPRINT is available on the web as ColabScreen: https://bit.ly/colab-screen