 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Stable Multi-Interest Learning for Out-of-distribution Sequential Recommendation
Apr 12, 2023Recently, multi-interest models, which extract interests of a user as multiple representation vectors, have shown promising performances for sequential recommendation. However, none of existing multi-interest recommendation models consider the Out-Of-Distribution (OOD) generalization problem, in which interest distribution may change. Considering multiple interests of a user are usually highly correlated, the model has chance to learn spurious correlations between noisy interests and target items. Once the data distribution changes, the correlations among interests may also change, and the spurious correlations will mislead the model to make wrong predictions. To tackle with above OOD generalization problem, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which attempts to de-correlate the extracted interests in the model, and thus spurious correlations can be eliminated. DESMIL applies an attentive module to extract multiple interests, and then selects the most important one for making final predictions. Meanwhile, DESMIL incorporates a weighted correlation estimation loss based on Hilbert-Schmidt Independence Criterion (HSIC), with which training samples are weighted, to minimize the correlations among extracted interests. Extensive experiments have been conducted under both OOD and random settings, and up to 36.8% and 21.7% relative improvements are achieved respectively.
A Closer Look at Few-Shot Video Classification: A New Baseline and Benchmark
Oct 24, 2021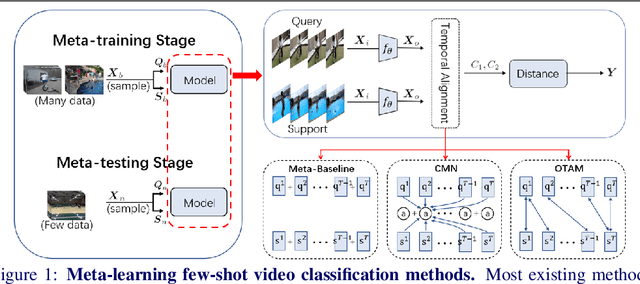
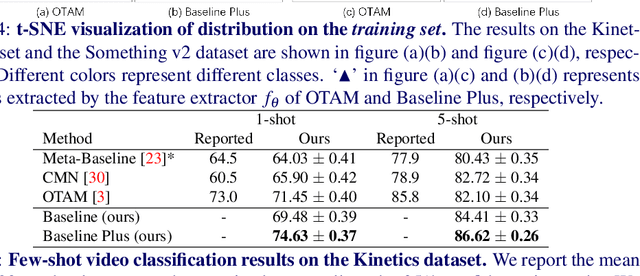
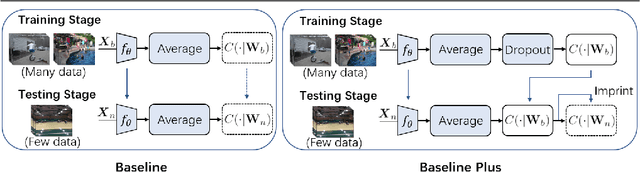
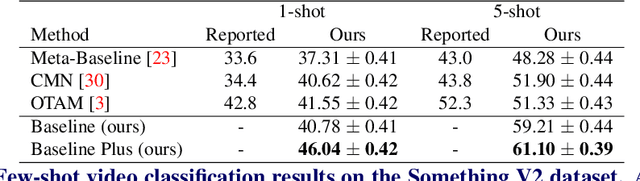
The existing few-shot video classification methods often employ a meta-learning paradigm by designing customized temporal alignment module for similarity calculation. While significant progress has been made, these methods fail to focus on learning effective representations, and heavily rely on the ImageNet pre-training, which might be unreasonable for the few-shot recognition setting due to semantics overlap. In this paper, we aim to present an in-depth study on few-shot video classification by making three contributions. First, we perform a consistent comparative study on the existing metric-based methods to figure out their limitations in representation learning. Accordingly, we propose a simple classifier-based baseline without any temporal alignment that surprisingly outperforms the state-of-the-art meta-learning based methods. Second, we discover that there is a high correlation between the novel action class and the ImageNet object class, which is problematic in the few-shot recognition setting. Our results show that the performance of training from scratch drops significantly, which implies that the existing benchmarks cannot provide enough base data. Finally, we present a new benchmark with more base data to facilitate future few-shot video classification without pre-training. The code will be made available at https://github.com/MCG-NJU/FSL-Video.
Active Learning to Classify Macromolecular Structures in situ for Less Supervision in Cryo-Electron Tomography
Feb 24, 2021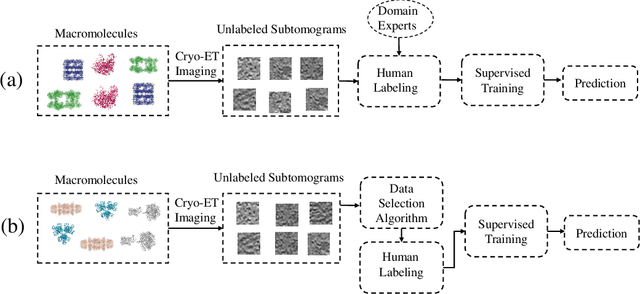
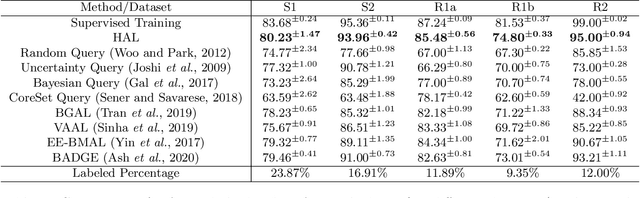
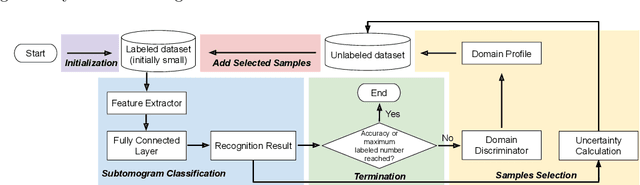

Motivation: Cryo-Electron Tomography (cryo-ET) is a 3D bioimaging tool that visualizes the structural and spatial organization of macromolecules at a near-native state in single cells, which has broad applications in life science. However, the systematic structural recognition and recovery of macromolecules captured by cryo-ET are difficult due to high structural complexity and imaging limits. Deep learning based subtomogram classification have played critical roles for such tasks. As supervised approaches, however, their performance relies on sufficient and laborious annotation on a large training dataset. Results: To alleviate this major labeling burden, we proposed a Hybrid Active Learning (HAL) framework for querying subtomograms for labelling from a large unlabeled subtomogram pool. Firstly, HAL adopts uncertainty sampling to select the subtomograms that have the most uncertain predictions. Moreover, to mitigate the sampling bias caused by such strategy, a discriminator is introduced to judge if a certain subtomogram is labeled or unlabeled and subsequently the model queries the subtomogram that have higher probabilities to be unlabeled. Additionally, HAL introduces a subset sampling strategy to improve the diversity of the query set, so that the information overlap is decreased between the queried batches and the algorithmic efficiency is improved. Our experiments on subtomogram classification tasks using both simulated and real data demonstrate that we can achieve comparable testing performance (on average only 3% accuracy drop) by using less than 30% of the labeled subtomograms, which shows a very promising result for subtomogram classification task with limited labeling resources.