 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Few-Shot Video Classification: A New Baseline and Benchmark
Paper and Code
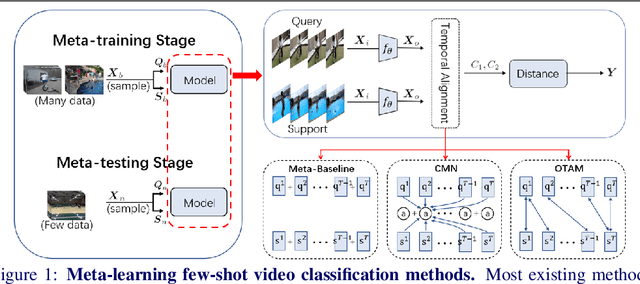
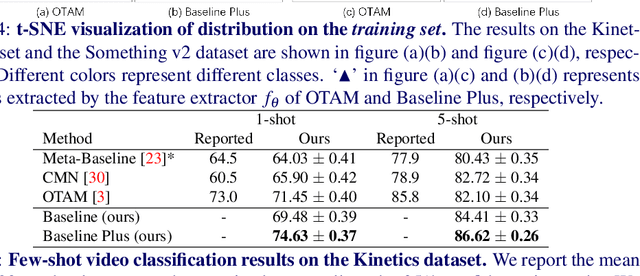
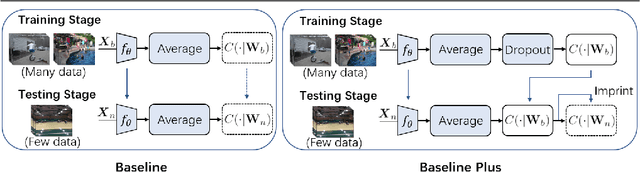
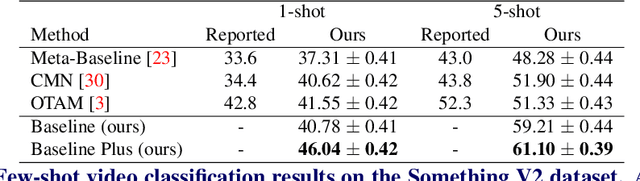
The existing few-shot video classification methods often employ a meta-learning paradigm by designing customized temporal alignment module for similarity calculation. While significant progress has been made, these methods fail to focus on learning effective representations, and heavily rely on the ImageNet pre-training, which might be unreasonable for the few-shot recognition setting due to semantics overlap. In this paper, we aim to present an in-depth study on few-shot video classification by making three contributions. First, we perform a consistent comparative study on the existing metric-based methods to figure out their limitations in representation learning. Accordingly, we propose a simple classifier-based baseline without any temporal alignment that surprisingly outperforms the state-of-the-art meta-learning based methods. Second, we discover that there is a high correlation between the novel action class and the ImageNet object class, which is problematic in the few-shot recognition setting. Our results show that the performance of training from scratch drops significantly, which implies that the existing benchmarks cannot provide enough base data. Finally, we present a new benchmark with more base data to facilitate future few-shot video classification without pre-training. The code will be made available at https://github.com/MCG-NJU/FSL-Video.