 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Heterogeneous Biomolecules via Hierarchical Gaussian Mixtures and Part Discovery
Jun 06, 2025


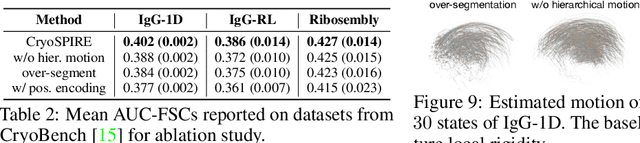
Cryo-EM is a transformational paradigm in molecular biology where computational methods are used to infer 3D molecular structure at atomic resolution from extremely noisy 2D electron microscope images. At the forefront of research is how to model the structure when the imaged particles exhibit non-rigid conformational flexibility and compositional variation where parts are sometimes missing. We introduce a novel 3D reconstruction framework with a hierarchical Gaussian mixture model, inspired in part by Gaussian Splatting for 4D scene reconstruction. In particular, the structure of the model is grounded in an initial process that infers a part-based segmentation of the particle, providing essential inductive bias in order to handle both conformational and compositional variability. The framework, called CryoSPIRE, is shown to reveal biologically meaningful structures on complex experimental datasets, and establishes a new state-of-the-art on CryoBench, a benchmark for cryo-EM heterogeneity methods.
Improving Ab-Initio Cryo-EM Reconstruction with Semi-Amortized Pose Inference
Jun 15, 2024
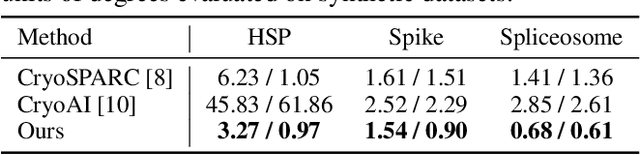


Cryo-Electron Microscopy (cryo-EM) is an increasingly popular experimental technique for estimating the 3D structure of macromolecular complexes such as proteins based on 2D images. These images are notoriously noisy, and the pose of the structure in each image is unknown \textit{a priori}. Ab-initio 3D reconstruction from 2D images entails estimating the pose in addition to the structure. In this work, we propose a new approach to this problem. We first adopt a multi-head architecture as a pose encoder to infer multiple plausible poses per-image in an amortized fashion. This approach mitigates the high uncertainty in pose estimation by encouraging exploration of pose space early in reconstruction. Once uncertainty is reduced, we refine poses in an auto-decoding fashion. In particular, we initialize with the most likely pose and iteratively update it for individual images using stochastic gradient descent (SGD). Through evaluation on synthetic datasets, we demonstrate that our method is able to handle multi-modal pose distributions during the amortized inference stage, while the later, more flexible stage of direct pose optimization yields faster and more accurate convergence of poses compared to baselines. Finally, on experimental data, we show that our approach is faster than state-of-the-art cryoAI and achieves higher-resolution reconstruction.
Dual-Camera Joint Deblurring-Denoising
Sep 16, 2023Recent image enhancement methods have shown the advantages of using a pair of long and short-exposure images for low-light photography. These image modalities offer complementary strengths and weaknesses. The former yields an image that is clean but blurry due to camera or object motion, whereas the latter is sharp but noisy due to low photon count. Motivated by the fact that modern smartphones come equipped with multiple rear-facing camera sensors, we propose a novel dual-camera method for obtaining a high-quality image. Our method uses a synchronized burst of short exposure images captured by one camera and a long exposure image simultaneously captured by another. Having a synchronized short exposure burst alongside the long exposure image enables us to (i) obtain better denoising by using a burst instead of a single image, (ii) recover motion from the burst and use it for motion-aware deblurring of the long exposure image, and (iii) fuse the two results to further enhance quality. Our method is able to achieve state-of-the-art results on synthetic dual-camera images from the GoPro dataset with five times fewer training parameters compared to the next best method. We also show that our method qualitatively outperforms competing approaches on real synchronized dual-camera captures.
Residual Multiplicative Filter Networks for Multiscale Reconstruction
Jun 01, 2022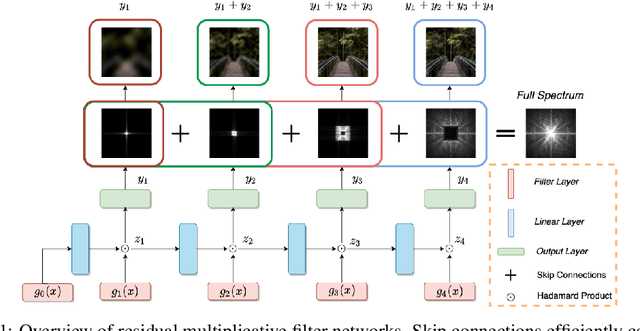
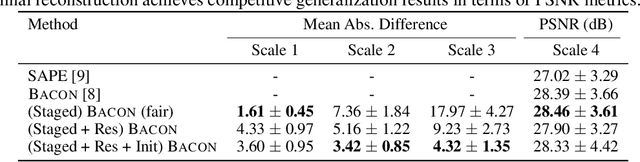
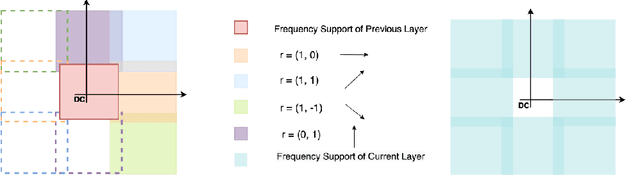
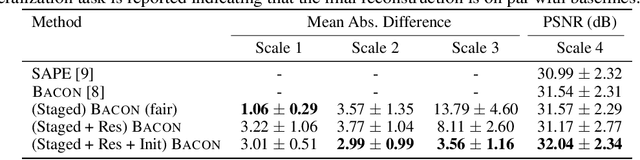
Coordinate networks like Multiplicative Filter Networks (MFNs) and BACON offer some control over the frequency spectrum used to represent continuous signals such as images or 3D volumes. Yet, they are not readily applicable to problems for which coarse-to-fine estimation is required, including various inverse problems in which coarse-to-fine optimization plays a key role in avoiding poor local minima. We introduce a new coordinate network architecture and training scheme that enables coarse-to-fine optimization with fine-grained control over the frequency support of learned reconstructions. This is achieved with two key innovations. First, we incorporate skip connections so that structure at one scale is preserved when fitting finer-scale structure. Second, we propose a novel initialization scheme to provide control over the model frequency spectrum at each stage of optimization. We demonstrate how these modifications enable multiscale optimization for coarse-to-fine fitting to natural images. We then evaluate our model on synthetically generated datasets for the the problem of single-particle cryo-EM reconstruction. We learn high resolution multiscale structures, on par with the state-of-the art.
Self-Attention Equipped Graph Convolutions for Disease Prediction
Dec 24, 2018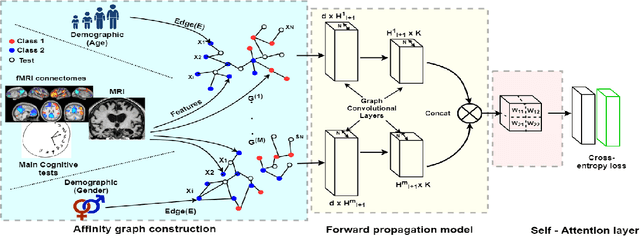
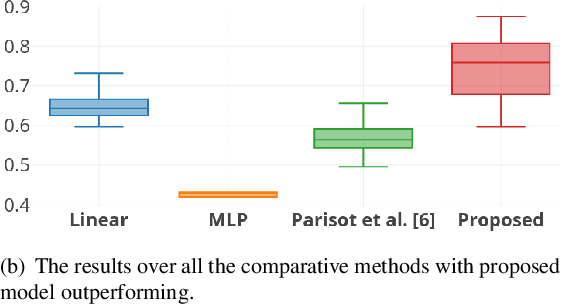
Multi-modal data comprising imaging (MRI, fMRI, PET, etc.) and non-imaging (clinical test, demographics, etc.) data can be collected together and used for disease prediction. Such diverse data gives complementary information about the patient\'s condition to make an informed diagnosis. A model capable of leveraging the individuality of each multi-modal data is required for better disease prediction. We propose a graph convolution based deep model which takes into account the distinctiveness of each element of the multi-modal data. We incorporate a novel self-attention layer, which weights every element of the demographic data by exploring its relation to the underlying disease. We demonstrate the superiority of our developed technique in terms of computational speed and performance when compared to state-of-the-art methods. Our method outperforms other methods with a significant margin.