 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Global Contact-Implicit MPC via Sampling and Local Complementarity
May 19, 2025To achieve general-purpose dexterous manipulation, robots must rapidly devise and execute contact-rich behaviors. Existing model-based controllers are incapable of globally optimizing in real-time over the exponential number of possible contact sequences. Instead, recent progress in contact-implicit control has leveraged simpler models that, while still hybrid, make local approximations. However, the use of local models inherently limits the controller to only exploit nearby interactions, potentially requiring intervention to richly explore the space of possible contacts. We present a novel approach which leverages the strengths of local complementarity-based control in combination with low-dimensional, but global, sampling of possible end-effector locations. Our key insight is to consider a contact-free stage preceding a contact-rich stage at every control loop. Our algorithm, in parallel, samples end effector locations to which the contact-free stage can move the robot, then considers the cost predicted by contact-rich MPC local to each sampled location. The result is a globally-informed, contact-implicit controller capable of real-time dexterous manipulation. We demonstrate our controller on precise, non-prehensile manipulation of non-convex objects using a Franka Panda arm. Project page: https://approximating-global-ci-mpc.github.io
Vysics: Object Reconstruction Under Occlusion by Fusing Vision and Contact-Rich Physics
Apr 25, 2025



We introduce Vysics, a vision-and-physics framework for a robot to build an expressive geometry and dynamics model of a single rigid body, using a seconds-long RGBD video and the robot's proprioception. While the computer vision community has built powerful visual 3D perception algorithms, cluttered environments with heavy occlusions can limit the visibility of objects of interest. However, observed motion of partially occluded objects can imply physical interactions took place, such as contact with a robot or the environment. These inferred contacts can supplement the visible geometry with "physible geometry," which best explains the observed object motion through physics. Vysics uses a vision-based tracking and reconstruction method, BundleSDF, to estimate the trajectory and the visible geometry from an RGBD video, and an odometry-based model learning method, Physics Learning Library (PLL), to infer the "physible" geometry from the trajectory through implicit contact dynamics optimization. The visible and "physible" geometries jointly factor into optimizing a signed distance function (SDF) to represent the object shape. Vysics does not require pretraining, nor tactile or force sensors. Compared with vision-only methods, Vysics yields object models with higher geometric accuracy and better dynamics prediction in experiments where the object interacts with the robot and the environment under heavy occlusion. Project page: https://vysics-vision-and-physics.github.io/
Simultaneous Learning of Contact and Continuous Dynamics
Oct 18, 2023Robotic manipulation can greatly benefit from the data efficiency, robustness, and predictability of model-based methods if robots can quickly generate models of novel objects they encounter. This is especially difficult when effects like complex joint friction lack clear first-principles models and are usually ignored by physics simulators. Further, numerically-stiff contact dynamics can make common model-building approaches struggle. We propose a method to simultaneously learn contact and continuous dynamics of a novel, possibly multi-link object by observing its motion through contact-rich trajectories. We formulate a system identification process with a loss that infers unmeasured contact forces, penalizing their violation of physical constraints and laws of motion given current model parameters. Our loss is unlike prediction-based losses used in differentiable simulation. Using a new dataset of real articulated object trajectories and an existing cube toss dataset, our method outperforms differentiable simulation and end-to-end alternatives with more data efficiency. See our project page for code, datasets, and media: https://sites.google.com/view/continuous-contact-nets/home
Instance-Agnostic Geometry and Contact Dynamics Learning
Sep 28, 2023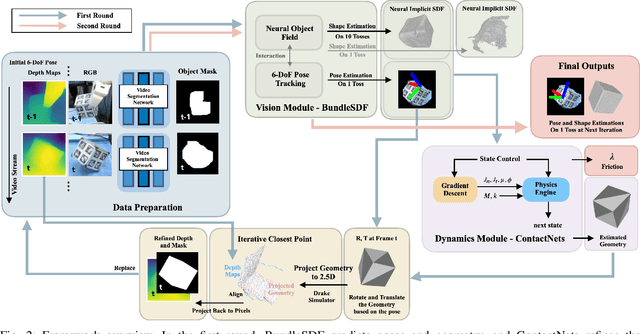

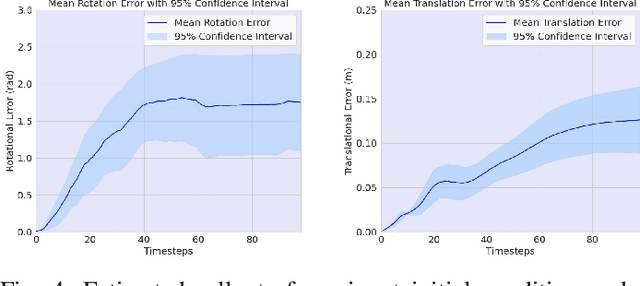
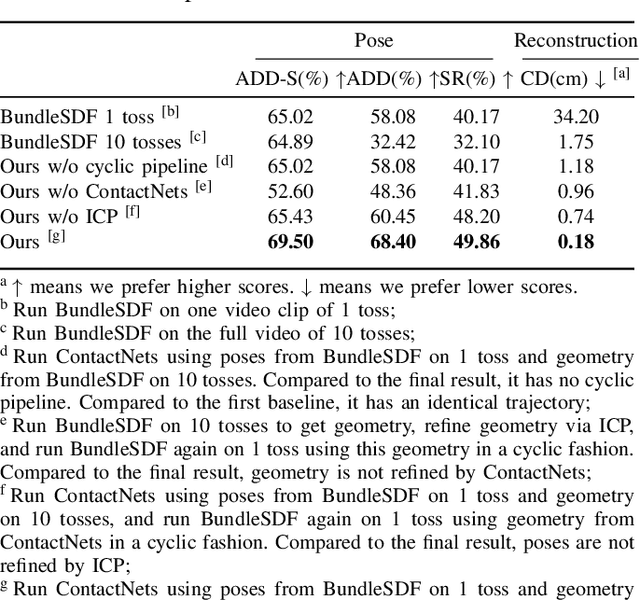
This work presents an instance-agnostic learning framework that fuses vision with dynamics to simultaneously learn shape, pose trajectories, and physical properties via the use of geometry as a shared representation. Unlike many contact learning approaches that assume motion capture input and a known shape prior for the collision model, our proposed framework learns an object's geometric and dynamic properties from RGBD video, without requiring either category-level or instance-level shape priors. We integrate a vision system, BundleSDF, with a dynamics system, ContactNets, and propose a cyclic training pipeline to use the output from the dynamics module to refine the poses and the geometry from the vision module, using perspective reprojection. Experiments demonstrate our framework's ability to learn the geometry and dynamics of rigid and convex objects and improve upon the current tracking framework.
Generalization Bounded Implicit Learning of Nearly Discontinuous Functions
Dec 14, 2021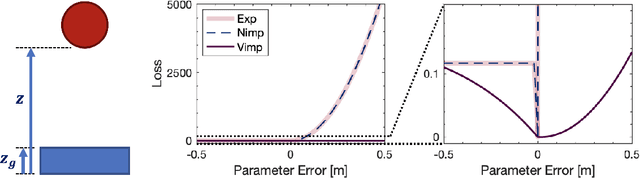
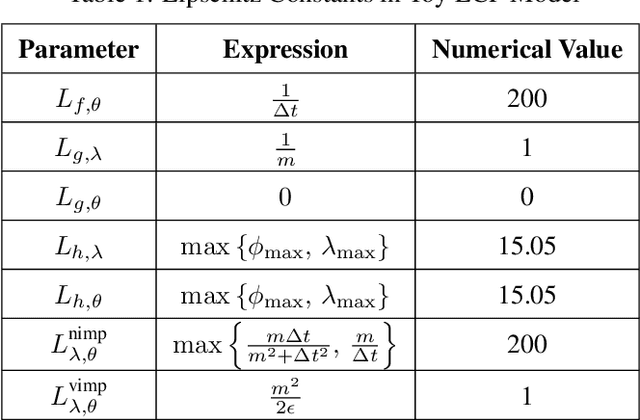
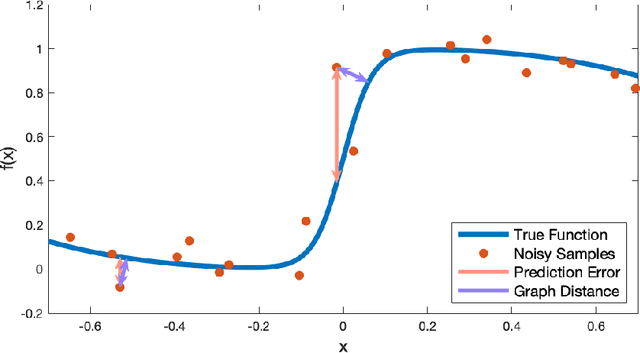
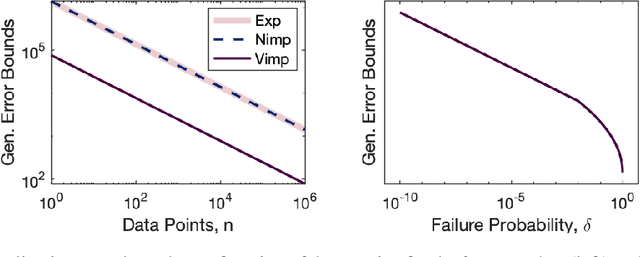
Inspired by recent strides in empirical efficacy of implicit learning in many robotics tasks, we seek to understand the theoretical benefits of implicit formulations in the face of nearly discontinuous functions, common characteristics for systems that make and break contact with the environment such as in legged locomotion and manipulation. We present and motivate three formulations for learning a function: one explicit and two implicit. We derive generalization bounds for each of these three approaches, exposing where explicit and implicit methods alike based on prediction error losses typically fail to produce tight bounds, in contrast to other implicit methods with violation-based loss definitions that can be fundamentally more robust to steep slopes. Furthermore, we demonstrate that this violation implicit loss can tightly bound graph distance, a quantity that often has physical roots and handles noise in inputs and outputs alike, instead of prediction losses which consider output noise only. Our insights into the generalizability and physical relevance of violation implicit formulations match evidence from prior works and are validated through a toy problem, inspired by rigid-contact models and referenced throughout our theoretical analysis.