 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBordIRlines: A Dataset for Evaluating Cross-lingual Retrieval-Augmented Generation
Oct 02, 2024


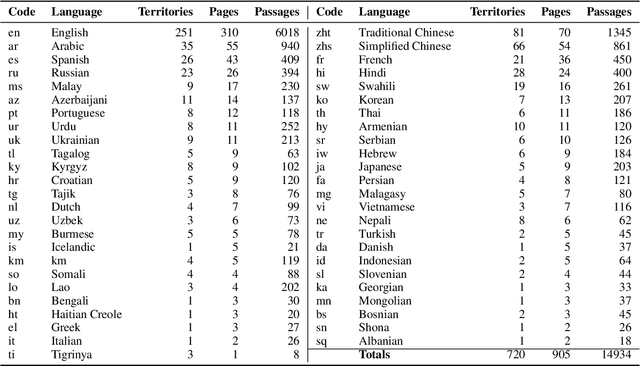
Large language models excel at creative generation but continue to struggle with the issues of hallucination and bias. While retrieval-augmented generation (RAG) provides a framework for grounding LLMs' responses in accurate and up-to-date information, it still raises the question of bias: which sources should be selected for inclusion in the context? And how should their importance be weighted? In this paper, we study the challenge of cross-lingual RAG and present a dataset to investigate the robustness of existing systems at answering queries about geopolitical disputes, which exist at the intersection of linguistic, cultural, and political boundaries. Our dataset is sourced from Wikipedia pages containing information relevant to the given queries and we investigate the impact of including additional context, as well as the composition of this context in terms of language and source, on an LLM's response. Our results show that existing RAG systems continue to be challenged by cross-lingual use cases and suffer from a lack of consistency when they are provided with competing information in multiple languages. We present case studies to illustrate these issues and outline steps for future research to address these challenges. We make our dataset and code publicly available at https://github.com/manestay/bordIRlines.
Detecting Social Media Manipulation in Low-Resource Languages
Nov 10, 2020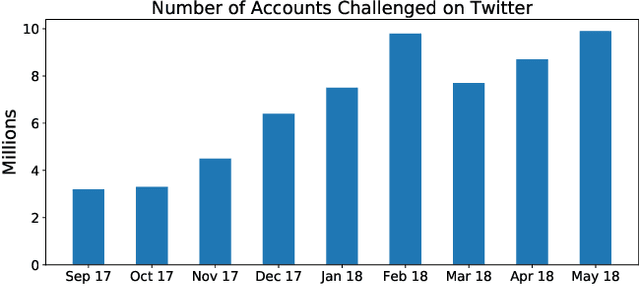
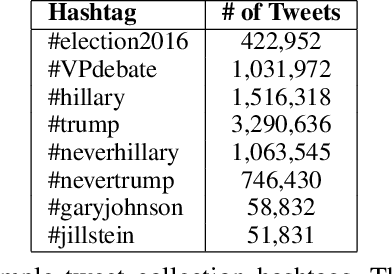
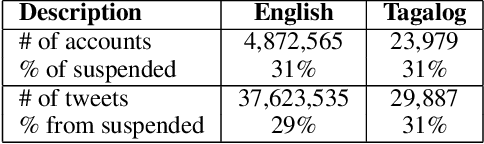
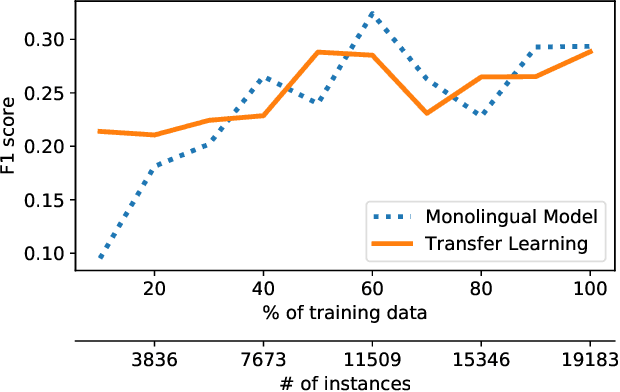
Social media have been deliberately used for malicious purposes, including political manipulation and disinformation. Most research focuses on high-resource languages. However, malicious actors share content across countries and languages, including low-resource ones. Here, we investigate whether and to what extent malicious actors can be detected in low-resource language settings. We discovered that a high number of accounts posting in Tagalog were suspended as part of Twitter's crackdown on interference operations after the 2016 US Presidential election. By combining text embedding and transfer learning, our framework can detect, with promising accuracy, malicious users posting in Tagalog without any prior knowledge or training on malicious content in that language. We first learn an embedding model for each language, namely a high-resource language (English) and a low-resource one (Tagalog), independently. Then, we learn a mapping between the two latent spaces to transfer the detection model. We demonstrate that the proposed approach significantly outperforms state-of-the-art models, including BERT, and yields marked advantages in settings with very limited training data-the norm when dealing with detecting malicious activity in online platforms.