 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInjecting Relational Structural Representation in Neural Networks for Question Similarity
Jun 20, 2018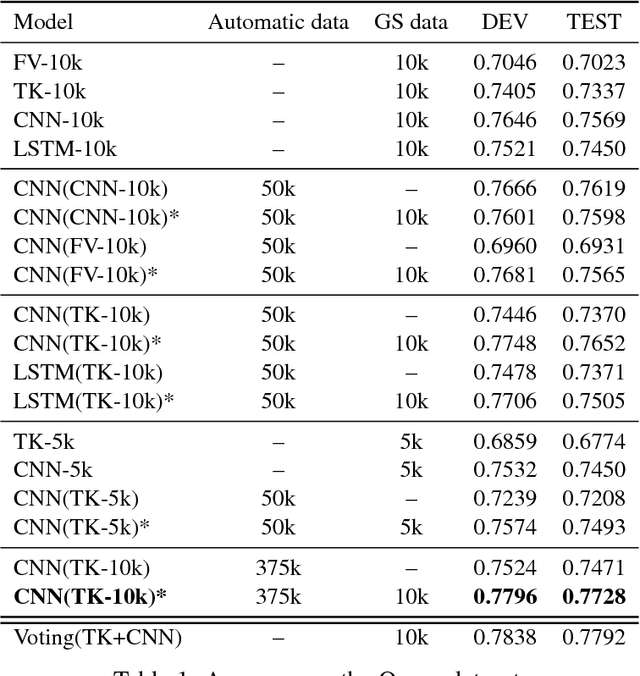
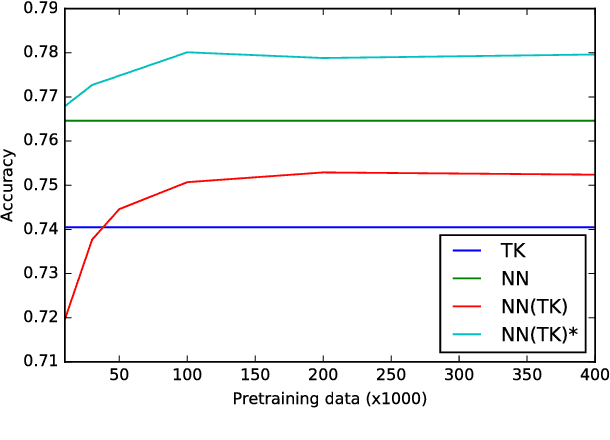
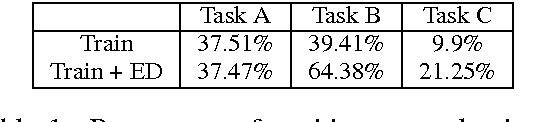
Effectively using full syntactic parsing information in Neural Networks (NNs) to solve relational tasks, e.g., question similarity, is still an open problem. In this paper, we propose to inject structural representations in NNs by (i) learning an SVM model using Tree Kernels (TKs) on relatively few pairs of questions (few thousands) as gold standard (GS) training data is typically scarce, (ii) predicting labels on a very large corpus of question pairs, and (iii) pre-training NNs on such large corpus. The results on Quora and SemEval question similarity datasets show that NNs trained with our approach can learn more accurate models, especially after fine tuning on GS.
Multitask Learning with Deep Neural Networks for Community Question Answering
Feb 13, 2017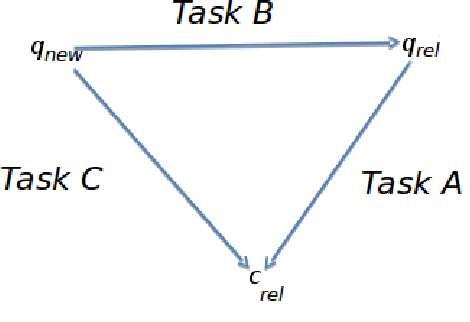
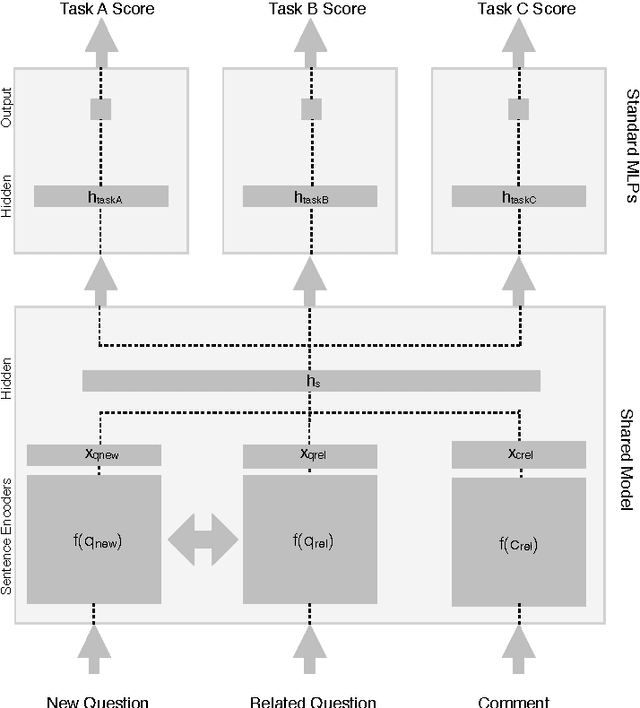

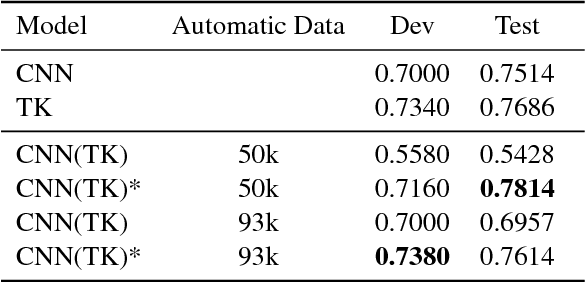
In this paper, we developed a deep neural network (DNN) that learns to solve simultaneously the three tasks of the cQA challenge proposed by the SemEval-2016 Task 3, i.e., question-comment similarity, question-question similarity and new question-comment similarity. The latter is the main task, which can exploit the previous two for achieving better results. Our DNN is trained jointly on all the three cQA tasks and learns to encode questions and comments into a single vector representation shared across the multiple tasks. The results on the official challenge test set show that our approach produces higher accuracy and faster convergence rates than the individual neural networks. Additionally, our method, which does not use any manual feature engineering, approaches the state of the art established with methods that make heavy use of it.
Addressing Community Question Answering in English and Arabic
Oct 18, 2016
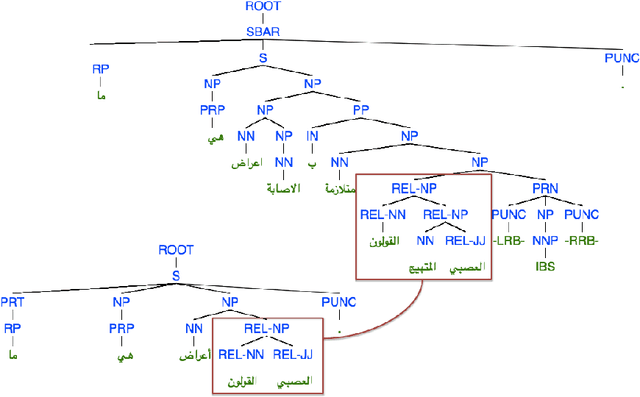
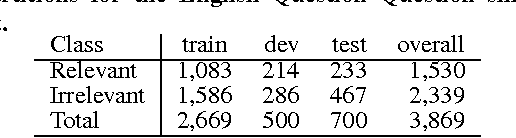
This paper studies the impact of different types of features applied to learning to re-rank questions in community Question Answering. We tested our models on two datasets released in SemEval-2016 Task 3 on "Community Question Answering". Task 3 targeted real-life Web fora both in English and Arabic. Our models include bag-of-words features (BoW), syntactic tree kernels (TKs), rank features, embeddings, and machine translation evaluation features. To the best of our knowledge, structural kernels have barely been applied to the question reranking task, where they have to model paraphrase relations. In the case of the English question re-ranking task, we compare our learning to rank (L2R) algorithms against a strong baseline given by the Google-generated ranking (GR). The results show that i) the shallow structures used in our TKs are robust enough to noisy data and ii) improving GR is possible, but effective BoW features and TKs along with an accurate model of GR features in the used L2R algorithm are required. In the case of the Arabic question re-ranking task, for the first time we applied tree kernels on syntactic trees of Arabic sentences. Our approaches to both tasks obtained the second best results on SemEval-2016 subtasks B on English and D on Arabic.