 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthEmbeddingExplorer: A Web Application for Cross-Modal Retrieval of Global Satellite Images
Mar 31, 2026While the Earth observation community has witnessed a surge in high-impact foundation models and global Earth embedding datasets, a significant barrier remains in translating these academic assets into freely accessible tools. This tutorial introduces EarthEmbeddingExplorer, an interactive web application designed to bridge this gap, transforming static research artifacts into dynamic, practical workflows for discovery. We will provide a comprehensive hands-on guide to the system, detailing its cloud-native software architecture, demonstrating cross-modal queries (natural language, visual, and geolocation), and showcasing how to derive scientific insights from retrieval results. By democratizing access to precomputed Earth embeddings, this tutorial empowers researchers to seamlessly transition from state-of-the-art models and data archives to real-world application and analysis. The web application is available at https://modelscope.ai/studios/Major-TOM/EarthEmbeddingExplorer.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.
Beluga Whale Detection from Satellite Imagery with Point Labels
May 17, 2025



Very high-resolution (VHR) satellite imagery has emerged as a powerful tool for monitoring marine animals on a large scale. However, existing deep learning-based whale detection methods usually require manually created, high-quality bounding box annotations, which are labor-intensive to produce. Moreover, existing studies often exclude ``uncertain whales'', individuals that have ambiguous appearances in satellite imagery, limiting the applicability of these models in real-world scenarios. To address these limitations, this study introduces an automated pipeline for detecting beluga whales and harp seals in VHR satellite imagery. The pipeline leverages point annotations and the Segment Anything Model (SAM) to generate precise bounding box annotations, which are used to train YOLOv8 for multiclass detection of certain whales, uncertain whales, and harp seals. Experimental results demonstrated that SAM-generated annotations significantly improved detection performance, achieving higher $\text{F}_\text{1}$-scores compared to traditional buffer-based annotations. YOLOv8 trained on SAM-labeled boxes achieved an overall $\text{F}_\text{1}$-score of 72.2% for whales overall and 70.3% for harp seals, with superior performance in dense scenes. The proposed approach not only reduces the manual effort required for annotation but also enhances the detection of uncertain whales, offering a more comprehensive solution for marine animal monitoring. This method holds great potential for extending to other species, habitats, and remote sensing platforms, as well as for estimating whale biometrics, thereby advancing ecological monitoring and conservation efforts. The codes for our label and detection pipeline are publicly available at http://github.com/voyagerxvoyagerx/beluga-seeker .
OrchMLLM: Orchestrate Multimodal Data with Batch Post-Balancing to Accelerate Multimodal Large Language Model Training
Mar 31, 2025Multimodal large language models (MLLMs), such as GPT-4o, are garnering significant attention. During the exploration of MLLM training, we identified Modality Composition Incoherence, a phenomenon that the proportion of a certain modality varies dramatically across different examples. It exacerbates the challenges of addressing mini-batch imbalances, which lead to uneven GPU utilization between Data Parallel (DP) instances and severely degrades the efficiency and scalability of MLLM training, ultimately affecting training speed and hindering further research on MLLMs. To address these challenges, we introduce OrchMLLM, a comprehensive framework designed to mitigate the inefficiencies in MLLM training caused by Modality Composition Incoherence. First, we propose Batch Post-Balancing Dispatcher, a technique that efficiently eliminates mini-batch imbalances in sequential data. Additionally, we integrate MLLM Global Orchestrator into the training framework to orchestrate multimodal data and tackle the issues arising from Modality Composition Incoherence. We evaluate OrchMLLM across various MLLM sizes, demonstrating its efficiency and scalability. Experimental results reveal that OrchMLLM achieves a Model FLOPs Utilization (MFU) of $41.6\%$ when training an 84B MLLM with three modalities on $2560$ H100 GPUs, outperforming Megatron-LM by up to $3.1\times$ in throughput.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Self-attention-based non-linear basis transformations for compact latent space modelling of dynamic optical fibre transmission matrices
Jun 11, 2024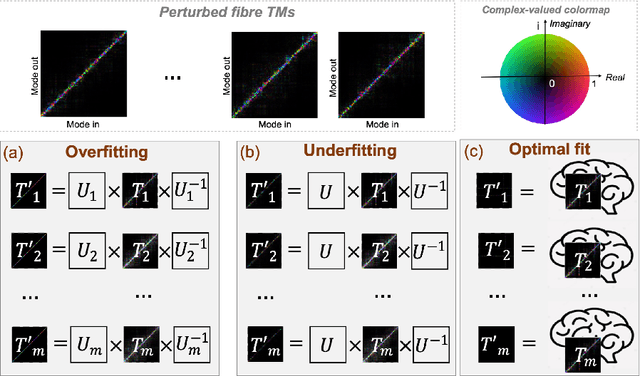



Multimode optical fibres are hair-thin strands of glass that efficiently transport light. They promise next-generation medical endoscopes that provide unprecedented sub-cellular image resolution deep inside the body. However, confining light to such fibres means that images are inherently scrambled in transit. Conventionally, this scrambling has been compensated by pre-calibrating how a specific fibre scrambles light and solving a stationary linear matrix equation that represents a physical model of the fibre. However, as the technology develops towards real-world deployment, the unscrambling process must account for dynamic changes in the matrix representing the fibre's effect on light, due to factors such as movement and temperature shifts, and non-linearities resulting from the inaccessibility of the fibre tip when inside the body. Such complex, dynamic and nonlinear behaviour is well-suited to approximation by neural networks, but most leading image reconstruction networks rely on convolutional layers, which assume strong correlations between adjacent pixels, a strong inductive bias that is inappropriate for fibre matrices which may be expressed in a range of arbitrary coordinate representations with long-range correlations. We introduce a new concept that uses self-attention layers to dynamically transform the coordinate representations of varying fibre matrices to a basis that admits compact, low-dimensional representations suitable for further processing. We demonstrate the effectiveness of this approach on diverse fibre matrix datasets. We show our models significantly improve the sparsity of fibre bases in their transformed bases with a participation ratio, p, as a measure of sparsity, of between 0.01 and 0.11. Further, we show that these transformed representations admit reconstruction of the original matrices with < 10% reconstruction error, demonstrating the invertibility.
Interpretable cancer cell detection with phonon microscopy using multi-task conditional neural networks for inter-batch calibration
Mar 26, 2024



Advances in artificial intelligence (AI) show great potential in revealing underlying information from phonon microscopy (high-frequency ultrasound) data to identify cancerous cells. However, this technology suffers from the 'batch effect' that comes from unavoidable technical variations between each experiment, creating confounding variables that the AI model may inadvertently learn. We therefore present a multi-task conditional neural network framework to simultaneously achieve inter-batch calibration, by removing confounding variables, and accurate cell classification of time-resolved phonon-derived signals. We validate our approach by training and validating on different experimental batches, achieving a balanced precision of 89.22% and an average cross-validated precision of 89.07% for classifying background, healthy and cancerous regions. Classification can be performed in 0.5 seconds with only simple prior batch information required for multiple batch corrections. Further, we extend our model to reconstruct denoised signals, enabling physical interpretation of salient features indicating disease state including sound velocity, sound attenuation and cell-adhesion to substrate.
Single-ended Recovery of Optical fiber Transmission Matrices using Neural Networks
Mar 31, 2023Ultra-thin multimode optical fiber imaging technology promises next-generation medical endoscopes that provide high image resolution deep in the body (e.g. blood vessels, brain). However, this technology suffers from severe optical distortion. The fiber's transmission matrix (TM) calibrates for this distortion but is sensitive to bending and temperature so must be measured immediately prior to imaging, i.e. \emph{in vivo} and thus with access to a single end only. We present a neural network (NN)-based approach that quickly reconstructs transmission matrices based on multi-wavelength reflection-mode measurements. We introduce a custom loss function insensitive to global phase-degeneracy that enables effective NN training. We then train two different NN architectures, a fully connected NN and convolutional U-Net, to reconstruct $64\times64$ complex-valued fiber TMs through a simulated single-ended optical fiber with $\leq 4\%$ error. This enables image reconstruction with $\leq 8\%$ error. This TM recovery approach shows advantages compared to conventional TM recovery methods: 4500 times faster; robustness to 6\% fiber perturbation during characterization; operation with non-square TMs and no requirement for prior characterization of reflectors.