 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attention-based non-linear basis transformations for compact latent space modelling of dynamic optical fibre transmission matrices
Jun 11, 2024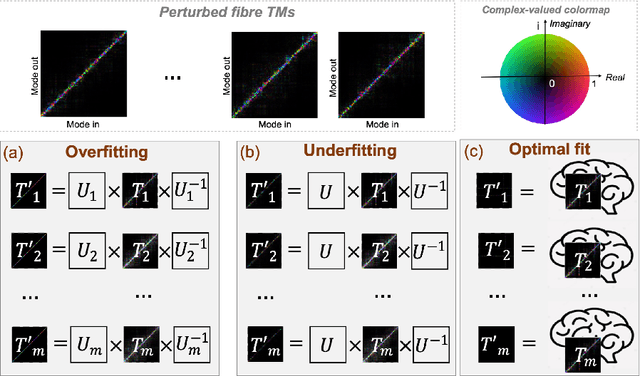



Multimode optical fibres are hair-thin strands of glass that efficiently transport light. They promise next-generation medical endoscopes that provide unprecedented sub-cellular image resolution deep inside the body. However, confining light to such fibres means that images are inherently scrambled in transit. Conventionally, this scrambling has been compensated by pre-calibrating how a specific fibre scrambles light and solving a stationary linear matrix equation that represents a physical model of the fibre. However, as the technology develops towards real-world deployment, the unscrambling process must account for dynamic changes in the matrix representing the fibre's effect on light, due to factors such as movement and temperature shifts, and non-linearities resulting from the inaccessibility of the fibre tip when inside the body. Such complex, dynamic and nonlinear behaviour is well-suited to approximation by neural networks, but most leading image reconstruction networks rely on convolutional layers, which assume strong correlations between adjacent pixels, a strong inductive bias that is inappropriate for fibre matrices which may be expressed in a range of arbitrary coordinate representations with long-range correlations. We introduce a new concept that uses self-attention layers to dynamically transform the coordinate representations of varying fibre matrices to a basis that admits compact, low-dimensional representations suitable for further processing. We demonstrate the effectiveness of this approach on diverse fibre matrix datasets. We show our models significantly improve the sparsity of fibre bases in their transformed bases with a participation ratio, p, as a measure of sparsity, of between 0.01 and 0.11. Further, we show that these transformed representations admit reconstruction of the original matrices with < 10% reconstruction error, demonstrating the invertibility.
Adaptive foveated single-pixel imaging with dynamic super-sampling
Jul 27, 2016As an alternative to conventional multi-pixel cameras, single-pixel cameras enable images to be recorded using a single detector that measures the correlations between the scene and a set of patterns. However, to fully sample a scene in this way requires at least the same number of correlation measurements as there are pixels in the reconstructed image. Therefore single-pixel imaging systems typically exhibit low frame-rates. To mitigate this, a range of compressive sensing techniques have been developed which rely on a priori knowledge of the scene to reconstruct images from an under-sampled set of measurements. In this work we take a different approach and adopt a strategy inspired by the foveated vision systems found in the animal kingdom - a framework that exploits the spatio-temporal redundancy present in many dynamic scenes. In our single-pixel imaging system a high-resolution foveal region follows motion within the scene, but unlike a simple zoom, every frame delivers new spatial information from across the entire field-of-view. Using this approach we demonstrate a four-fold reduction in the time taken to record the detail of rapidly evolving features, whilst simultaneously accumulating detail of more slowly evolving regions over several consecutive frames. This tiered super-sampling technique enables the reconstruction of video streams in which both the resolution and the effective exposure-time spatially vary and adapt dynamically in response to the evolution of the scene. The methods described here can complement existing compressive sensing approaches and may be applied to enhance a variety of computational imagers that rely on sequential correlation measurements.