 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutation-based Fault Localization of Deep Neural Networks
Sep 10, 2023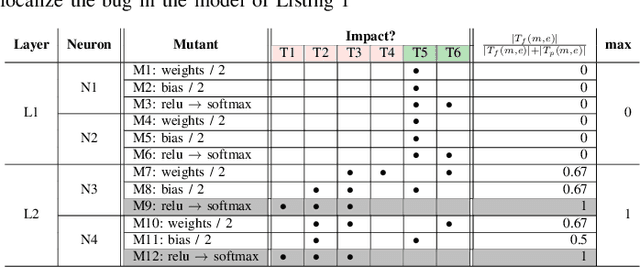
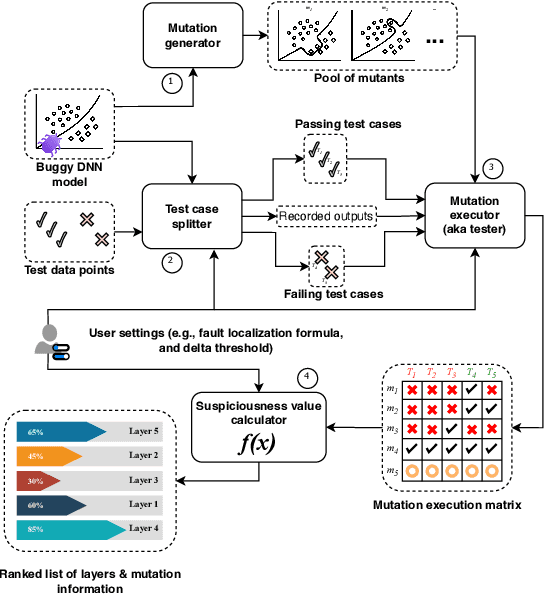

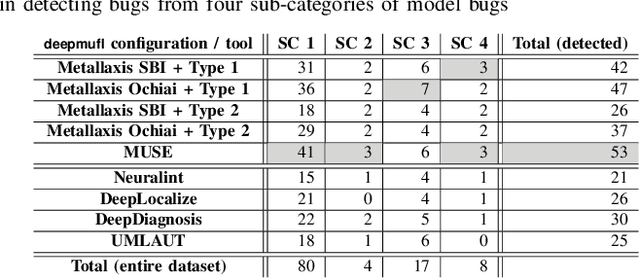
Deep neural networks (DNNs) are susceptible to bugs, just like other types of software systems. A significant uptick in using DNN, and its applications in wide-ranging areas, including safety-critical systems, warrant extensive research on software engineering tools for improving the reliability of DNN-based systems. One such tool that has gained significant attention in the recent years is DNN fault localization. This paper revisits mutation-based fault localization in the context of DNN models and proposes a novel technique, named deepmufl, applicable to a wide range of DNN models. We have implemented deepmufl and have evaluated its effectiveness using 109 bugs obtained from StackOverflow. Our results show that deepmufl detects 53/109 of the bugs by ranking the buggy layer in top-1 position, outperforming state-of-the-art static and dynamic DNN fault localization systems that are also designed to target the class of bugs supported by deepmufl. Moreover, we observed that we can halve the fault localization time for a pre-trained model using mutation selection, yet losing only 7.55% of the bugs localized in top-1 position.
Temporal Aware Deep Reinforcement Learning
Sep 05, 2021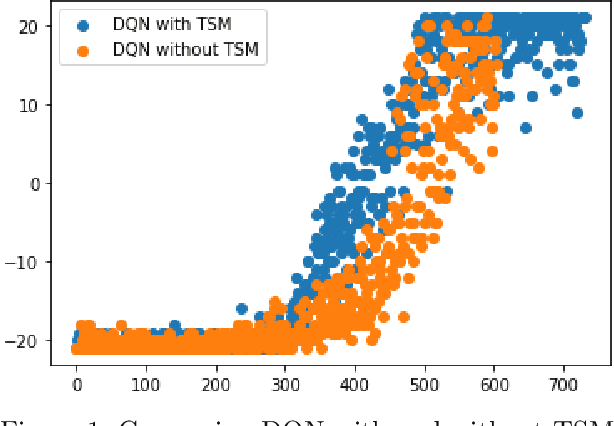
The function approximators employed by traditional image based Deep Reinforcement Learning (DRL) algorithms usually lack a temporal learning component and instead focus on learning the spatial component. We propose a technique wherein both temporal as well as spatial components are jointly learned. Our tested was tested with a generic DQN and it outperformed it in terms of maximum rewards as well as sample complexity. This algorithm has implications in the robotics as well as sequential decision making domains.
Interpretable UAV Collision Avoidance using Deep Reinforcement Learning
Jun 04, 2021
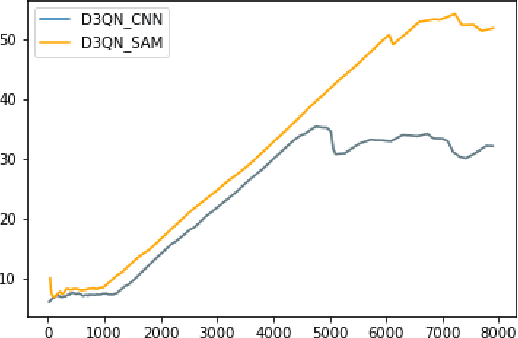
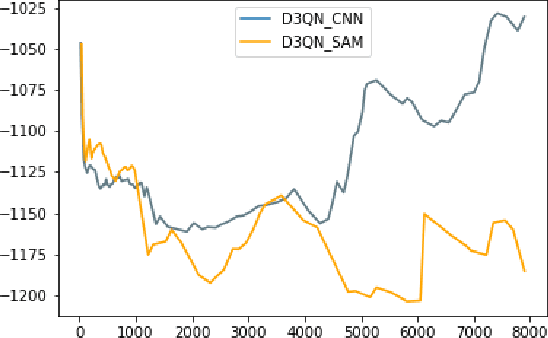
The significant components of any successful autonomous flight system are task completion and collision avoidance. Most deep learning algorithms successfully execute these aspects under the environment and conditions they are trained. However, they fail when subjected to novel environments. This paper presents an autonomous multi-rotor flight algorithm, using Deep Reinforcement Learning augmented with Self-Attention Models, that can effectively reason when subjected to varying inputs. In addition to their reasoning ability, they are also interpretable, enabling it to be used under real-world conditions. We have tested our algorithm under different weather conditions and environments and found it robust compared to conventional Deep Reinforcement Learning algorithms.
Towards the Next Generation Airline Revenue Management: A Deep Reinforcement Learning Approach to Seat Inventory Control and Overbooking
Feb 18, 2019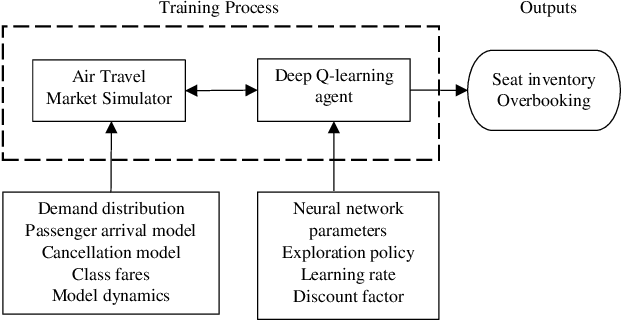
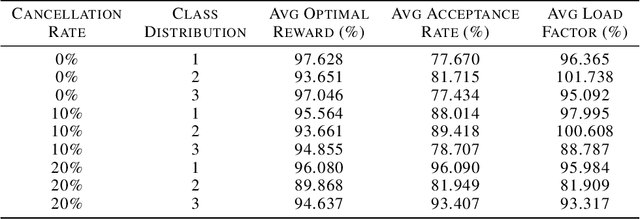
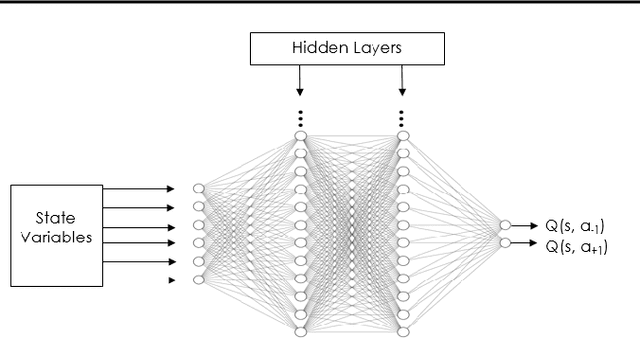
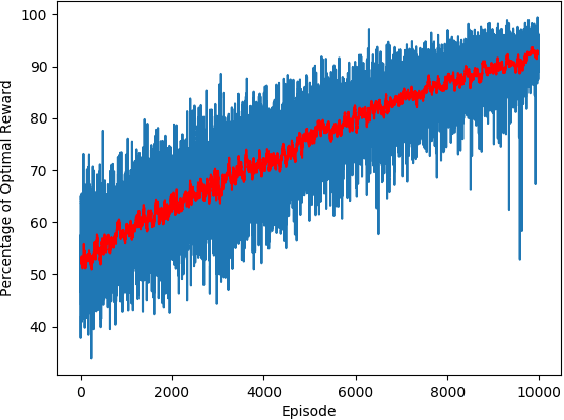
Revenue management can enable airline corporations to maximize the revenue generated from each scheduled flight departing in their transportation network by means of finding the optimal policies for differential pricing, seat inventory control and overbooking. As different demand segments in the market have different Willingness-To-Pay (WTP), airlines use differential pricing, booking restrictions, and service amenities to determine different fare classes or products targeted at each of these demand segments. Because seats are limited for each flight, airlines also need to allocate seats for each of these fare classes to prevent lower fare class passengers from displacing higher fare class ones and set overbooking limits in anticipation of cancellations and no-shows such that revenue is maximized. Previous work addresses these problems using optimization techniques or classical Reinforcement Learning methods. This paper focuses on the latter problem - the seat inventory control problem - casting it as a Markov Decision Process to be able to find the optimal policy. Multiple fare classes, concurrent continuous arrival of passengers of different fare classes, overbooking and random cancellations that are independent of class have been considered in the model. We have addressed this problem using Deep Q-Learning with the goal of maximizing the reward for each flight departure. The implementation of this technique allows us to employ large continuous state space but also presents the potential opportunity to test on real time airline data. To generate data and train the agent, a basic air-travel market simulator was developed. The performance of the agent in different simulated market scenarios was compared against theoretically optimal solutions and was found to be nearly close to the expected optimal revenue.