Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Aware Deep Reinforcement Learning
Paper and Code
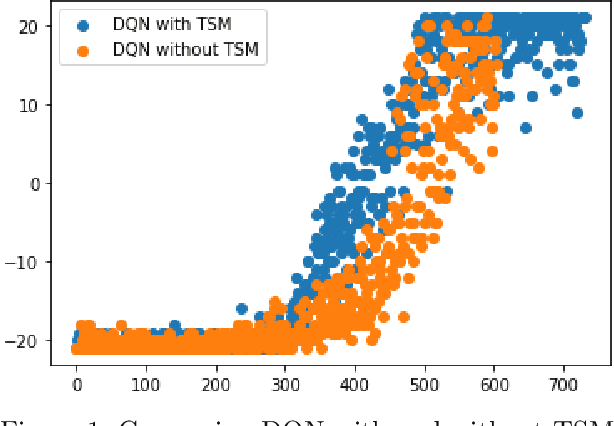
The function approximators employed by traditional image based Deep Reinforcement Learning (DRL) algorithms usually lack a temporal learning component and instead focus on learning the spatial component. We propose a technique wherein both temporal as well as spatial components are jointly learned. Our tested was tested with a generic DQN and it outperformed it in terms of maximum rewards as well as sample complexity. This algorithm has implications in the robotics as well as sequential decision making domains.
View paper on