 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrengthening the Case for a Bayesian Approach to Car-following Model Calibration and Validation using Probabilistic Programming
Paper and Code


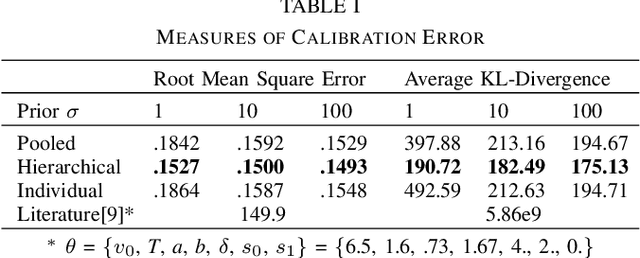
Compute and memory constraints have historically prevented traffic simulation software users from fully utilizing the predictive models underlying them. When calibrating car-following models, particularly, accommodations have included 1) using sensitivity analysis to limit the number of parameters to be calibrated, and 2) identifying only one set of parameter values using data collected from multiple car-following instances across multiple drivers. Shortcuts are further motivated by insufficient data set sizes, for which a driver may have too few instances to fully account for the variation in their driving behavior. In this paper, we demonstrate that recent technological advances can enable transportation researchers and engineers to overcome these constraints and produce calibration results that 1) outperform industry standard approaches, and 2) allow for a unique set of parameters to be estimated for each driver in a data set, even given a small amount of data. We propose a novel calibration procedure for car-following models based on Bayesian machine learning and probabilistic programming, and apply it to real-world data from a naturalistic driving study. We also discuss how this combination of mathematical and software tools can offer additional benefits such as more informative model validation and the incorporation of true-to-data uncertainty into simulation traces.