 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should a Robot Replan? Regret-Guided Update Scheduling in Time-Varying MDPs
Jun 15, 2026Robots operating in non-stationary environments must continually adapt their policies as the dynamics drift, but onboard energy and compute budgets cap how often a full state estimation and re-planning step can be performed. This raises a question: \emph{when}, along a horizon, should a robot spend its limited budget? We formulate this problem in time-varying Markov decision processes (TVMDPs) with a known bound on the rate of transition drift. We model execution as a \emph{skip-update} scheme in which, at chosen update times, the agent estimates the transition kernel by maximum likelihood and computes a finite-horizon policy, and between updates reuses this policy under a propagated state estimate. We analyze the dynamic regret of this scheme and show how it grows during skip intervals in terms of the properties of the TVMDP and the skip lengths; the resulting bound answers the opening question via an online, regret-guided update rule that allocates the budget adaptively. We evaluate the rule in a simulated Mars-rover navigation task with time-varying slip dynamics and on a Crazyflie quadrotor in indoor obstacle fields. Adaptive allocation outperforms other budgeted baselines.
Task-Aware Environment Augmentation for Reliable Navigation via Shielded Conditional Diffusion
Jun 13, 2026Reliable trajectory planning under partial observability depends not only on computing a feasible geometric path, but also on whether the robot receives informative observations while executing that trajectory. Existing approaches usually keep the environment fixed and adapt the robot through belief-space planning, active localization, or added sensing, often incurring costly uncertainty propagation and brittle behavior in observation-poor regions. We flip this perspective and address the largely open problem of \emph{task-aware environment augmentation}: given a mapped environment, a planned task trajectory, and a small budget of visual fiducial markers, where should the environment be augmented so that the planned trajectory can be executed reliably under uncertainty? Our key observation is that useful marker layouts are defined by the localization support they provide along the task trajectory: a small number of well-timed observations can be sufficient to prevent uncertainty from accumulating in regions where state-estimation error would otherwise compromise control. Building on this observation, we present \tbp{SCoDA}, $\textbf{S}$hielded $\textbf{Co}$nditional $\textbf{D}$iffusion for Environment $\textbf{A}$ugmentation. \tbp{SCoDA} learns a conditional distribution over high-performing fiducial layouts from data, using the environment, planned trajectory, disturbance context, and desired execution profile as conditioning. Its shielded sampler reasons over where along the planned execution pose corrections should occur, and steers this distribution toward task-relevant, finite-budget augmentations. Across simulated benchmarks and hardware deployments, we show that \tbp{SCoDA} improves trajectory execution reliability and completion time over strong baselines. Code, models and dataset available at: \hyperlink{scoda-diffusion.github.io}{https://scoda-diffusion.github.io/}
Trajectory-Level Redirection Attacks on Vision-Language-Action Models
Jun 11, 2026Vision-language-action (VLA) policies bring natural language into closed-loop robot control, enabling robots to execute manipulation tasks directly from text instructions. The same interface gives text a recurring role in control because the prompt is reused at every replanning step, and each prompt-conditioned action changes the future observations on which the policy acts. Existing VLA attacks study adversarial prompts that elicit targeted low-level actions or make such actions persist across changing images. We identify a stronger trajectory-level failure mode: a prompt that still $\textit{appears}$ to specify the intended task but redirects the final physical outcome. We mathematically formalize this setting as $\textit{command-preserving trajectory redirection}$, a prompt-only threat model in which the attacker chooses one prompt before the episode, all policy and environment components remain fixed, and the prompt must stay close to the benign instruction while omitting target words and correction language. To find such prompts, we introduce an on-policy prompt search method that uses rollouts to discover perturbations whose closed-loop behavior tracks a target task while satisfying the command-preserving constraints. Experiments in simulation and on hardware show that near-benign prompt perturbations can redirect VLA rollouts to attacker-specified targets. These results expose a trajectory-level vulnerability in VLA instruction grounding: text that appears to preserve the intended command can still give an adversary control over the robot's final physical outcome. Project website: https://vla-redirection-attack.github.io/
Muninn: Your Trajectory Diffusion Model But Faster
May 11, 2026Diffusion-based trajectory planners can synthesize rich, multimodal robot motions, but their iterative denoising makes online planning and control prohibitively slow. Existing accelerations either modify the sampler or compress the network--sacrificing plan quality or requiring retraining without accounting for downstream control risk. We address the problem of making diffusion-based trajectory planners fast enough for real-time robot use without retraining the model or sacrificing trajectory quality, and in a way that works across diverse state-space diffusion architectures. Our key insight is that diffusion trajectory planners expose two signals we can exploit: a cheap probe of how their internal trajectory representation changes across steps, and analytic coefficients that describe how denoiser errors affect the sampler's state update. By calibrating the first signal against the second on offline runs, we obtain a per-step score that upper-bounds how far the final trajectory can deviate when we reuse a cached denoiser output, and we treat this bound as an uncertainty budget that we can spend over the denoising process. Building on this insight, we present Muninn, a training-free caching wrapper that tracks this uncertainty budget during sampling and, at each diffusion step, chooses between reusing a cached denoiser output when the predicted deviation is small and recomputing the denoiser when it is not. Across standard benchmarks Muninn delivers up to 4.6x wall-clock speedups across several trajectory diffusion models by reducing denoiser evaluations, while preserving task performance and safety metrics. Muninn further certifies that cached rollouts remain within a specified distance of their full-compute counterparts, and we validate these gains in real-time closed-loop navigation and manipulation hardware deployments. Project page: https://github.com/gokulp01/Muninn.
Amortizing Trajectory Diffusion with Keyed Drift Fields
Mar 14, 2026Diffusion-based trajectory planners can synthesize rich, multimodal action sequences for offline reinforcement learning, but their iterative denoising incurs substantial inference-time cost, making closed-loop planning slow under tight compute budgets. We study the problem of achieving diffusion-like trajectory planning behavior with one-step inference, while retaining the ability to sample diverse candidate plans and condition on the current state in a receding-horizon control loop. Our key observation is that conditional trajectory generation fails under naïve distribution-matching objectives when the similarity measure used to align generated trajectories with the dataset is dominated by unconstrained future dimensions. In practice, this causes attraction toward average trajectories, collapses action diversity, and yields near-static behavior. Our key insight is that conditional generative planning requires a conditioning-aware notion of neighborhood: trajectory updates should be computed using distances in a compact key space that reflects the condition, while still applying updates in the full trajectory space. Building on this, we introduce Keyed Drifting Policies (KDP), a one-step trajectory generator trained with a drift-field objective that attracts generated trajectories toward condition-matched dataset windows and repels them from nearby generated samples, using a stop-gradient drifted target to amortize iterative refinement into training. At inference, the resulting policy produces a full trajectory window in a single forward pass. Across standard RL benchmarks and real-time hardware deployments, KDP achieves strong performance with one-step inference and substantially lower planning latency than diffusion sampling. Project website, code and videos: https://keyed-drifting.github.io/
SCoUT: Scalable Communication via Utility-Guided Temporal Grouping in Multi-Agent Reinforcement Learning
Mar 05, 2026Communication can improve coordination in partially observed multi-agent reinforcement learning (MARL), but learning \emph{when} and \emph{who} to communicate with requires choosing among many possible sender-recipient pairs, and the effect of any single message on future reward is hard to isolate. We introduce \textbf{SCoUT} (\textbf{S}calable \textbf{Co}mmunication via \textbf{U}tility-guided \textbf{T}emporal grouping), which addresses both these challenges via temporal and agent abstraction within traditional MARL. During training, SCoUT resamples \textit{soft} agent groups every \(K\) environment steps (macro-steps) via Gumbel-Softmax; these groups are latent clusters that induce an affinity used as a differentiable prior over recipients. Using the same assignments, a group-aware critic predicts values for each agent group and maps them to per-agent baselines through the same soft assignments, reducing critic complexity and variance. Each agent is trained with a three-headed policy: environment action, send decision, and recipient selection. To obtain precise communication learning signals, we derive counterfactual communication advantages by analytically removing each sender's contribution from the recipient's aggregated messages. This counterfactual computation enables precise credit assignment for both send and recipient-selection decisions. At execution time, all centralized training components are discarded and only the per-agent policy is run, preserving decentralized execution. Project website, videos and code: \hyperlink{https://scout-comm.github.io/}{https://scout-comm.github.io/}
Online Learning of Deceptive Policies under Intermittent Observation
Sep 19, 2025In supervisory control settings, autonomous systems are not monitored continuously. Instead, monitoring often occurs at sporadic intervals within known bounds. We study the problem of deception, where an agent pursues a private objective while remaining plausibly compliant with a supervisor's reference policy when observations occur. Motivated by the behavior of real, human supervisors, we situate the problem within Theory of Mind: the representation of what an observer believes and expects to see. We show that Theory of Mind can be repurposed to steer online reinforcement learning (RL) toward such deceptive behavior. We model the supervisor's expectations and distill from them a single, calibrated scalar -- the expected evidence of deviation if an observation were to happen now. This scalar combines how unlike the reference and current action distributions appear, with the agent's belief that an observation is imminent. Injected as a state-dependent weight into a KL-regularized policy improvement step within an online RL loop, this scalar informs a closed-form update that smoothly trades off self-interest and compliance, thus sidestepping hand-crafted or heuristic policies. In real-world, real-time hardware experiments on marine (ASV) and aerial (UAV) navigation, our ToM-guided RL runs online, achieves high return and success with observed-trace evidence calibrated to the supervisor's expectations.
Motion Planning and Control with Unknown Nonlinear Dynamics through Predicted Reachability
Mar 05, 2025Autonomous motion planning under unknown nonlinear dynamics presents significant challenges. An agent needs to continuously explore the system dynamics to acquire its properties, such as reachability, in order to guide system navigation adaptively. In this paper, we propose a hybrid planning-control framework designed to compute a feasible trajectory toward a target. Our approach involves partitioning the state space and approximating the system by a piecewise affine (PWA) system with constrained control inputs. By abstracting the PWA system into a directed weighted graph, we incrementally update the existence of its edges via affine system identification and reach control theory, introducing a predictive reachability condition by exploiting prior information of the unknown dynamics. Heuristic weights are assigned to edges based on whether their existence is certain or remains indeterminate. Consequently, we propose a framework that adaptively collects and analyzes data during mission execution, continually updates the predictive graph, and synthesizes a controller online based on the graph search outcomes. We demonstrate the efficacy of our approach through simulation scenarios involving a mobile robot operating in unknown terrains, with its unknown dynamics abstracted as a single integrator model.
TAB-Fields: A Maximum Entropy Framework for Mission-Aware Adversarial Planning
Dec 03, 2024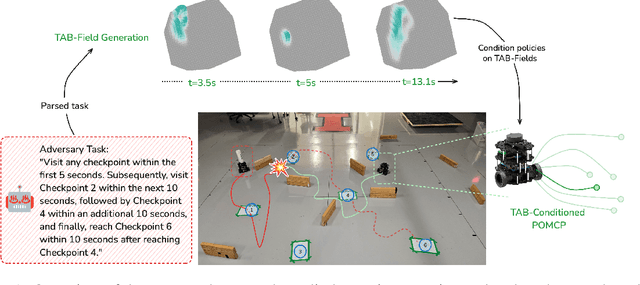
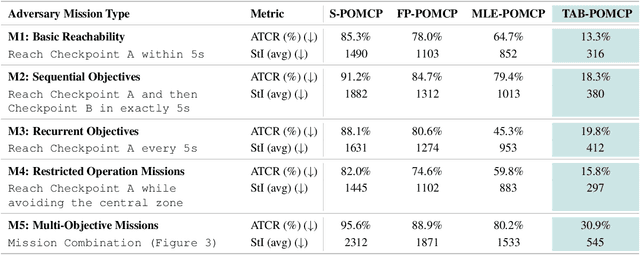
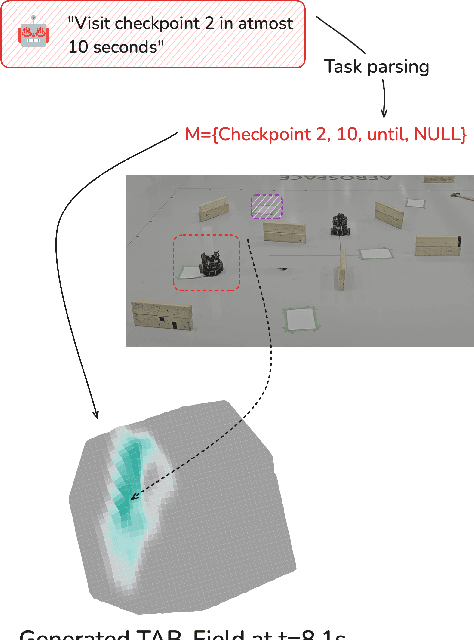
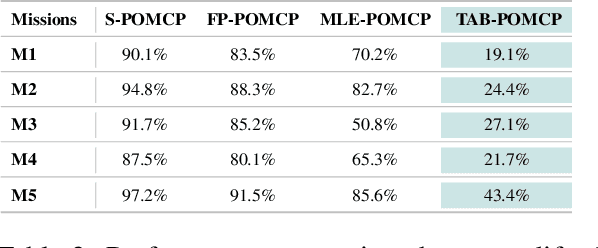
Autonomous agents operating in adversarial scenarios face a fundamental challenge: while they may know their adversaries' high-level objectives, such as reaching specific destinations within time constraints, the exact policies these adversaries will employ remain unknown. Traditional approaches address this challenge by treating the adversary's state as a partially observable element, leading to a formulation as a Partially Observable Markov Decision Process (POMDP). However, the induced belief-space dynamics in a POMDP require knowledge of the system's transition dynamics, which, in this case, depend on the adversary's unknown policy. Our key observation is that while an adversary's exact policy is unknown, their behavior is necessarily constrained by their mission objectives and the physical environment, allowing us to characterize the space of possible behaviors without assuming specific policies. In this paper, we develop Task-Aware Behavior Fields (TAB-Fields), a representation that captures adversary state distributions over time by computing the most unbiased probability distribution consistent with known constraints. We construct TAB-Fields by solving a constrained optimization problem that minimizes additional assumptions about adversary behavior beyond mission and environmental requirements. We integrate TAB-Fields with standard planning algorithms by introducing TAB-conditioned POMCP, an adaptation of Partially Observable Monte Carlo Planning. Through experiments in simulation with underwater robots and hardware implementations with ground robots, we demonstrate that our approach achieves superior performance compared to baselines that either assume specific adversary policies or neglect mission constraints altogether. Evaluation videos and code are available at https://tab-fields.github.io.
Enhancing Robot Navigation Policies with Task-Specific Uncertainty Management
Oct 19, 2024
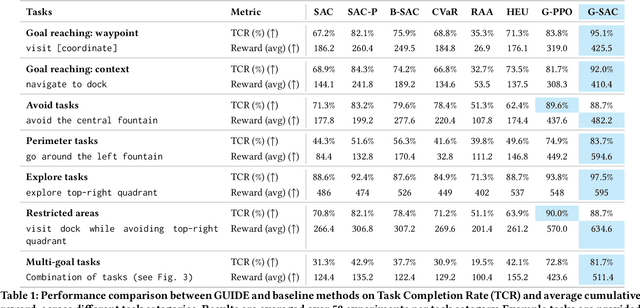
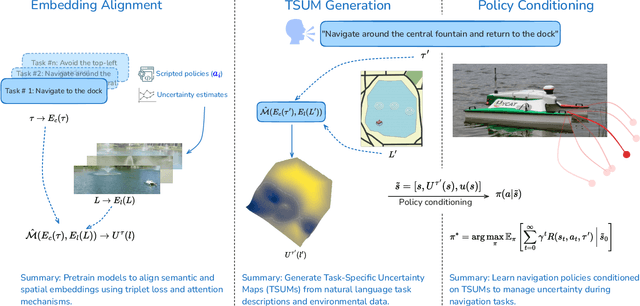
Robots performing navigation tasks in complex environments face significant challenges due to uncertainty in state estimation. Effectively managing this uncertainty is crucial, but the optimal approach varies depending on the specific details of the task: different tasks require varying levels of precision in different regions of the environment. For instance, a robot navigating a crowded space might need precise localization near obstacles but can operate effectively with less precise state estimates in open areas. This varying need for certainty in different parts of the environment, depending on the task, calls for policies that can adapt their uncertainty management strategies based on task-specific requirements. In this paper, we present a framework for integrating task-specific uncertainty requirements directly into navigation policies. We introduce Task-Specific Uncertainty Map (TSUM), which represents acceptable levels of state estimation uncertainty across different regions of the operating environment for a given task. Using TSUM, we propose Generalized Uncertainty Integration for Decision-Making and Execution (GUIDE), a policy conditioning framework that incorporates these uncertainty requirements into the robot's decision-making process. We find that conditioning policies on TSUMs provides an effective way to express task-specific uncertainty requirements and enables the robot to reason about the context-dependent value of certainty. We show how integrating GUIDE into reinforcement learning frameworks allows the agent to learn navigation policies without the need for explicit reward engineering to balance task completion and uncertainty management. We evaluate GUIDE on a variety of real-world navigation tasks and find that it demonstrates significant improvements in task completion rates compared to baselines. Evaluation videos can be found at https://guided-agents.github.io.