 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom RNNs to Foundation Models: An Empirical Study on Commercial Building Energy Consumption
Paper and Code
Nov 21, 2024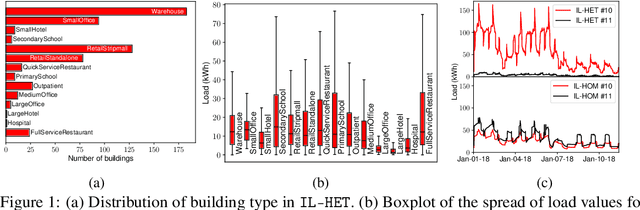
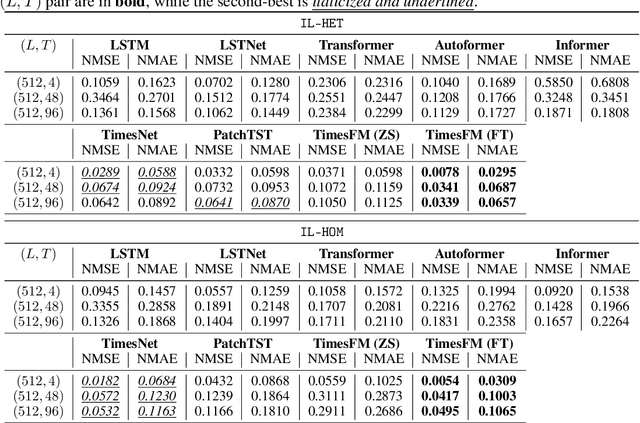
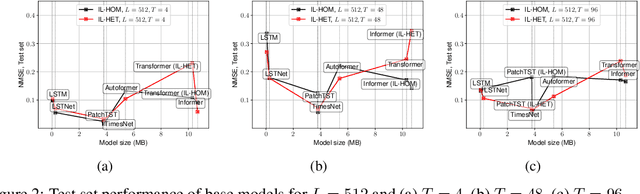

Accurate short-term energy consumption forecasting for commercial buildings is crucial for smart grid operations. While smart meters and deep learning models enable forecasting using past data from multiple buildings, data heterogeneity from diverse buildings can reduce model performance. The impact of increasing dataset heterogeneity in time series forecasting, while keeping size and model constant, is understudied. We tackle this issue using the ComStock dataset, which provides synthetic energy consumption data for U.S. commercial buildings. Two curated subsets, identical in size and region but differing in building type diversity, are used to assess the performance of various time series forecasting models, including fine-tuned open-source foundation models (FMs). The results show that dataset heterogeneity and model architecture have a greater impact on post-training forecasting performance than the parameter count. Moreover, despite the higher computational cost, fine-tuned FMs demonstrate competitive performance compared to base models trained from scratch.