 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDOVECL: AI-generated Dataset of Outpainted Vehicles for Eye-level Classification and Localization
Oct 31, 2024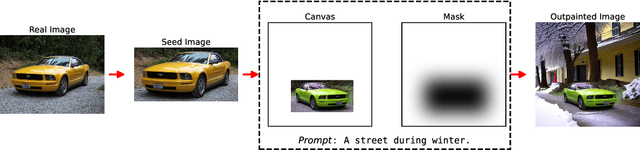



Image labeling is a critical bottleneck in the development of computer vision technologies, often constraining the potential of machine learning models due to the time-intensive nature of manual annotations. This work introduces a novel approach that leverages outpainting to address the problem of annotated data scarcity by generating artificial contexts and annotations, significantly reducing manual labeling efforts. We apply this technique to a particularly acute challenge in autonomous driving, urban planning, and environmental monitoring: the lack of diverse, eye-level vehicle images in desired classes. Our dataset comprises AI-generated vehicle images obtained by detecting and cropping vehicles from manually selected seed images, which are then outpainted onto larger canvases to simulate varied real-world conditions. The outpainted images include detailed annotations, providing high-quality ground truth data. Advanced outpainting techniques and image quality assessments ensure visual fidelity and contextual relevance. Augmentation with outpainted vehicles improves overall performance metrics by up to 8\% and enhances prediction of underrepresented classes by up to 20\%. This approach, exemplifying outpainting as a self-annotating paradigm, presents a solution that enhances dataset versatility across multiple domains of machine learning. The code and links to datasets used in this study are available for further research and replication at https://github.com/amir-kazemi/aidovecl.
Sequence Generation via Subsequence Similarity: Theory and Application to UAV Identification
Jan 20, 2023



The ability to generate synthetic sequences is crucial for a wide range of applications, and recent advances in deep learning architectures and generative frameworks have greatly facilitated this process. Particularly, unconditional one-shot generative models constitute an attractive line of research that focuses on capturing the internal information of a single image, video, etc. to generate samples with similar contents. Since many of those one-shot models are shifting toward efficient non-deep and non-adversarial approaches, we examine the versatility of a one-shot generative model for augmenting whole datasets. In this work, we focus on how similarity at the subsequence level affects similarity at the sequence level, and derive bounds on the optimal transport of real and generated sequences based on that of corresponding subsequences. We use a one-shot generative model to sample from the vicinity of individual sequences and generate subsequence-similar ones and demonstrate the improvement of this approach by applying it to the problem of Unmanned Aerial Vehicle (UAV) identification using limited radio-frequency (RF) signals. In the context of UAV identification, RF fingerprinting is an effective method for distinguishing legitimate devices from malicious ones, but heterogenous environments and channel impairments can impose data scarcity and affect the performance of classification models. By using subsequence similarity to augment sequences of RF data with a low ratio (5\%-20\%) of training dataset, we achieve significant improvements in performance metrics such as accuracy, precision, recall, and F1 score.
IGANI: Iterative Generative Adversarial Networks for Imputation Applied to Prediction of Traffic Data
Aug 11, 2020



Generative adversarial networks (GANs) are implicit generative models that can be used for data imputation as an unsupervised learning problem. This works introduces an iterative GAN architecture for data imputation based on the invertibility of the generative imputer. This property is a sufficient condition for the convergence of the proposed GAN architecture. The performance of imputation is demonstrated by applying different imputation algorithms on the traffic speed data from Guangzhou (China). It is shown that our proposed algorithm produces more accurate results compared to those of previous GAN-based imputation architectures.