 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Label Classification with Generative AI Models in Healthcare: A Case Study of Suicidality and Risk Factors
Jul 22, 2025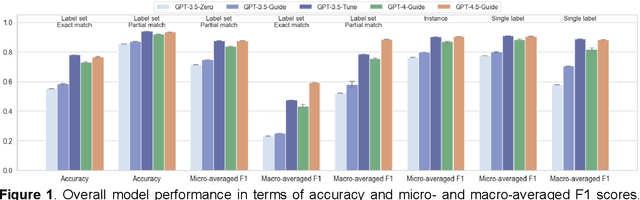
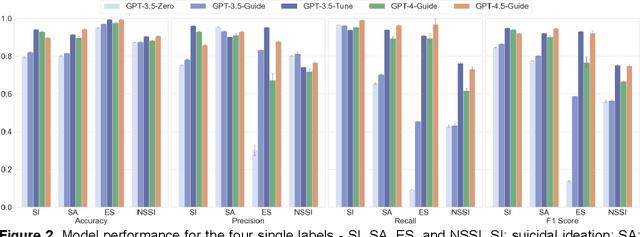
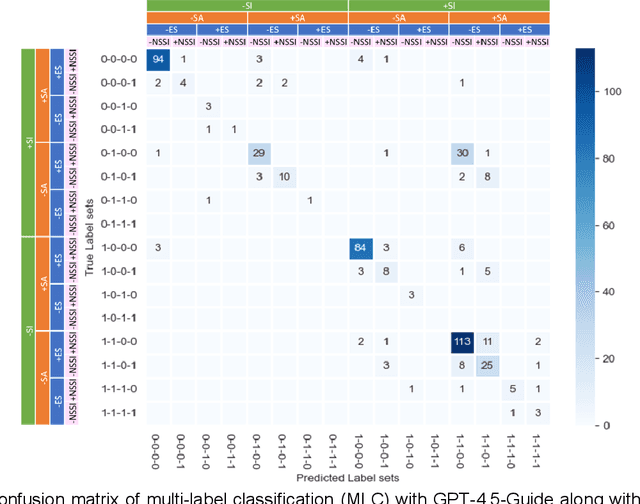
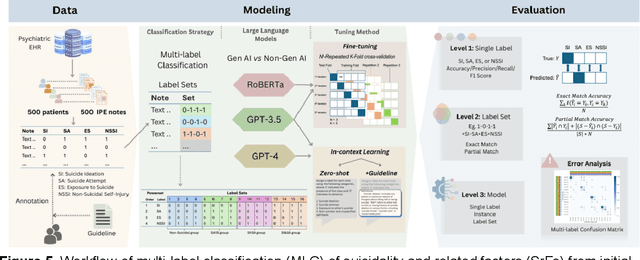
Suicide remains a pressing global health crisis, with over 720,000 deaths annually and millions more affected by suicide ideation (SI) and suicide attempts (SA). Early identification of suicidality-related factors (SrFs), including SI, SA, exposure to suicide (ES), and non-suicidal self-injury (NSSI), is critical for timely intervention. While prior studies have applied AI to detect SrFs in clinical notes, most treat suicidality as a binary classification task, overlooking the complexity of cooccurring risk factors. This study explores the use of generative large language models (LLMs), specifically GPT-3.5 and GPT-4.5, for multi-label classification (MLC) of SrFs from psychiatric electronic health records (EHRs). We present a novel end to end generative MLC pipeline and introduce advanced evaluation methods, including label set level metrics and a multilabel confusion matrix for error analysis. Finetuned GPT-3.5 achieved top performance with 0.94 partial match accuracy and 0.91 F1 score, while GPT-4.5 with guided prompting showed superior performance across label sets, including rare or minority label sets, indicating a more balanced and robust performance. Our findings reveal systematic error patterns, such as the conflation of SI and SA, and highlight the models tendency toward cautious over labeling. This work not only demonstrates the feasibility of using generative AI for complex clinical classification tasks but also provides a blueprint for structuring unstructured EHR data to support large scale clinical research and evidence based medicine.
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness
Nov 04, 2024Large language models (LLM) have demonstrated emergent abilities in text generation, question answering, and reasoning, facilitating various tasks and domains. Despite their proficiency in various tasks, LLMs like LaPM 540B and Llama-3.1 405B face limitations due to large parameter sizes and computational demands, often requiring cloud API use which raises privacy concerns, limits real-time applications on edge devices, and increases fine-tuning costs. Additionally, LLMs often underperform in specialized domains such as healthcare and law due to insufficient domain-specific knowledge, necessitating specialized models. Therefore, Small Language Models (SLMs) are increasingly favored for their low inference latency, cost-effectiveness, efficient development, and easy customization and adaptability. These models are particularly well-suited for resource-limited environments and domain knowledge acquisition, addressing LLMs' challenges and proving ideal for applications that require localized data handling for privacy, minimal inference latency for efficiency, and domain knowledge acquisition through lightweight fine-tuning. The rising demand for SLMs has spurred extensive research and development. However, a comprehensive survey investigating issues related to the definition, acquisition, application, enhancement, and reliability of SLM remains lacking, prompting us to conduct a detailed survey on these topics. The definition of SLMs varies widely, thus to standardize, we propose defining SLMs by their capability to perform specialized tasks and suitability for resource-constrained settings, setting boundaries based on the minimal size for emergent abilities and the maximum size sustainable under resource constraints. For other aspects, we provide a taxonomy of relevant models/methods and develop general frameworks for each category to enhance and utilize SLMs effectively.
Suicide Phenotyping from Clinical Notes in Safety-Net Psychiatric Hospital Using Multi-Label Classification with Pre-Trained Language Models
Sep 27, 2024



Accurate identification and categorization of suicidal events can yield better suicide precautions, reducing operational burden, and improving care quality in high-acuity psychiatric settings. Pre-trained language models offer promise for identifying suicidality from unstructured clinical narratives. We evaluated the performance of four BERT-based models using two fine-tuning strategies (multiple single-label and single multi-label) for detecting coexisting suicidal events from 500 annotated psychiatric evaluation notes. The notes were labeled for suicidal ideation (SI), suicide attempts (SA), exposure to suicide (ES), and non-suicidal self-injury (NSSI). RoBERTa outperformed other models using binary relevance (acc=0.86, F1=0.78). MentalBERT (F1=0.74) also exceeded BioClinicalBERT (F1=0.72). RoBERTa fine-tuned with a single multi-label classifier further improved performance (acc=0.88, F1=0.81), highlighting that models pre-trained on domain-relevant data and the single multi-label classification strategy enhance efficiency and performance. Keywords: EHR-based Phynotyping; Natural Language Processing; Secondary Use of EHR Data; Suicide Classification; BERT-based Model; Psychiatry; Mental Health
Can GPT-4 Help Detect Quit Vaping Intentions? An Exploration of Automatic Data Annotation Approach
Jun 28, 2024



In recent years, the United States has witnessed a significant surge in the popularity of vaping or e-cigarette use, leading to a notable rise in cases of e-cigarette and vaping use-associated lung injury (EVALI) that caused hospitalizations and fatalities during the EVALI outbreak in 2019, highlighting the urgency to comprehend vaping behaviors and develop effective strategies for cessation. Due to the ubiquity of social media platforms, over 4.7 billion users worldwide use them for connectivity, communications, news, and entertainment with a significant portion of the discourse related to health, thereby establishing social media data as an invaluable organic data resource for public health research. In this study, we extracted a sample dataset from one vaping sub-community on Reddit to analyze users' quit-vaping intentions. Leveraging OpenAI's latest large language model GPT-4 for sentence-level quit vaping intention detection, this study compares the outcomes of this model against layman and clinical expert annotations. Using different prompting strategies such as zero-shot, one-shot, few-shot and chain-of-thought prompting, we developed 8 prompts with varying levels of detail to explain the task to GPT-4 and also evaluated the performance of the strategies against each other. These preliminary findings emphasize the potential of GPT-4 in social media data analysis, especially in identifying users' subtle intentions that may elude human detection.
Utilizing Large Language Models to Identify Reddit Users Considering Vaping Cessation for Digital Interventions
Apr 25, 2024The widespread adoption of social media platforms globally not only enhances users' connectivity and communication but also emerges as a vital channel for the dissemination of health-related information, thereby establishing social media data as an invaluable organic data resource for public health research. The surge in popularity of vaping or e-cigarette use in the United States and other countries has caused an outbreak of e-cigarette and vaping use-associated lung injury (EVALI), leading to hospitalizations and fatalities in 2019, highlighting the urgency to comprehend vaping behaviors and develop effective strategies for cession. In this study, we extracted a sample dataset from one vaping sub-community on Reddit to analyze users' quit vaping intentions. Leveraging large language models including both the latest GPT-4 and traditional BERT-based language models for sentence-level quit-vaping intention prediction tasks, this study compares the outcomes of these models against human annotations. Notably, when compared to human evaluators, GPT-4 model demonstrates superior consistency in adhering to annotation guidelines and processes, showcasing advanced capabilities to detect nuanced user quit-vaping intentions that human evaluators might overlook. These preliminary findings emphasize the potential of GPT-4 in enhancing the accuracy and reliability of social media data analysis, especially in identifying subtle users' intentions that may elude human detection.
Flexible Variational Information Bottleneck: Achieving Diverse Compression with a Single Training
Feb 02, 2024



Information Bottleneck (IB) is a widely used framework that enables the extraction of information related to a target random variable from a source random variable. In the objective function, IB controls the trade-off between data compression and predictiveness through the Lagrange multiplier $\beta$. Traditionally, to find the trade-off to be learned, IB requires a search for $\beta$ through multiple training cycles, which is computationally expensive. In this study, we introduce Flexible Variational Information Bottleneck (FVIB), an innovative framework for classification task that can obtain optimal models for all values of $\beta$ with single, computationally efficient training. We theoretically demonstrate that across all values of reasonable $\beta$, FVIB can simultaneously maximize an approximation of the objective function for Variational Information Bottleneck (VIB), the conventional IB method. Then we empirically show that FVIB can learn the VIB objective as effectively as VIB. Furthermore, in terms of calibration performance, FVIB outperforms other IB and calibration methods by enabling continuous optimization of $\beta$. Our codes are available at https://github.com/sotakudo/fvib.
Detecting Reddit Users with Depression Using a Hybrid Neural Network
Feb 03, 2023



Depression is a widespread mental health issue, affecting an estimated 3.8% of the global population. It is also one of the main contributors to disability worldwide. Recently it is becoming popular for individuals to use social media platforms (e.g., Reddit) to express their difficulties and health issues (e.g., depression) and seek support from other users in online communities. It opens great opportunities to automatically identify social media users with depression by parsing millions of posts for potential interventions. Deep learning methods have begun to dominate in the field of machine learning and natural language processing (NLP) because of their ease of use, efficient processing, and state-of-the-art results on many NLP tasks. In this work, we propose a hybrid deep learning model which combines a pretrained sentence BERT (SBERT) and convolutional neural network (CNN) to detect individuals with depression with their Reddit posts. The sentence BERT is used to learn the meaningful representation of semantic information in each post. CNN enables the further transformation of those embeddings and the temporal identification of behavioral patterns of users. We trained and evaluated the model performance to identify Reddit users with depression by utilizing the Self-reported Mental Health Diagnoses (SMHD) data. The hybrid deep learning model achieved an accuracy of 0.86 and an F1 score of 0.86 and outperformed the state-of-the-art documented result (F1 score of 0.79) by other machine learning models in the literature. The results show the feasibility of the hybrid model to identify individuals with depression. Although the hybrid model is validated to detect depression with Reddit posts, it can be easily tuned and applied to other text classification tasks and different clinical applications.
A New Outlier Removal Strategy Based on Reliability of Correspondence Graph for Fast Point Cloud Registration
May 16, 2022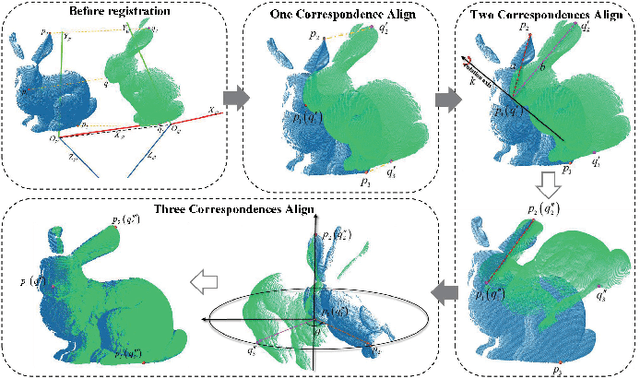

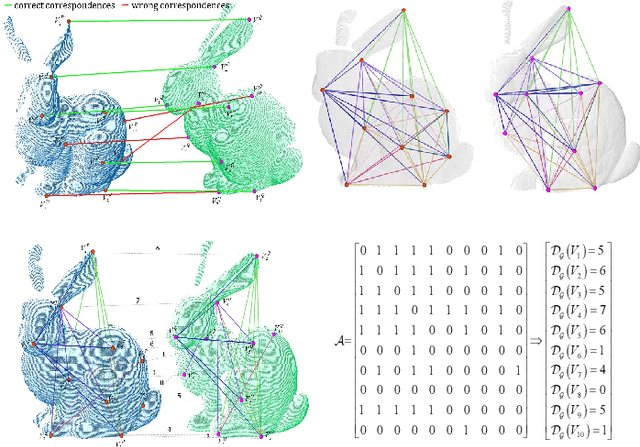
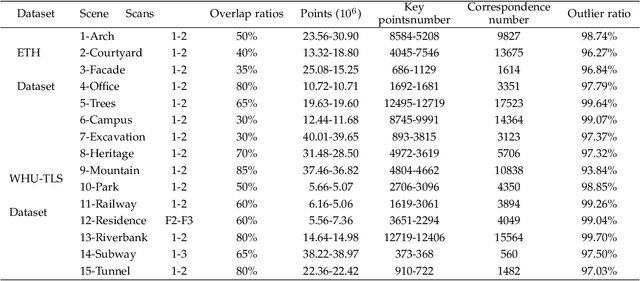
Registration is a basic yet crucial task in point cloud processing. In correspondence-based point cloud registration, matching correspondences by point feature techniques may lead to an extremely high outlier ratio. Current methods still suffer from low efficiency, accuracy, and recall rate. We use a simple and intuitive method to describe the 6-DOF (degree of freedom) curtailment process in point cloud registration and propose an outlier removal strategy based on the reliability of the correspondence graph. The method constructs the corresponding graph according to the given correspondences and designs the concept of the reliability degree of the graph node for optimal candidate selection and the reliability degree of the graph edge to obtain the global maximum consensus set. The presented method could achieve fast and accurate outliers removal along with gradual aligning parameters estimation. Extensive experiments on simulations and challenging real-world datasets demonstrate that the proposed method can still perform effective point cloud registration even the correspondence outlier ratio is over 99%, and the efficiency is better than the state-of-the-art. Code is available at https://github.com/WPC-WHU/GROR.
Enhancement on Model Interpretability and Sleep Stage Scoring Performance with A Novel Pipeline Based on Deep Neural Network
Apr 07, 2022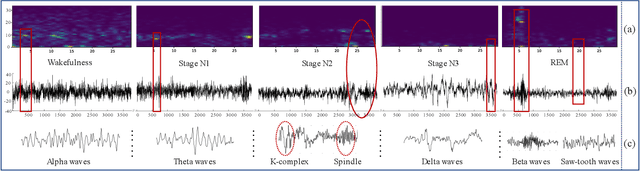
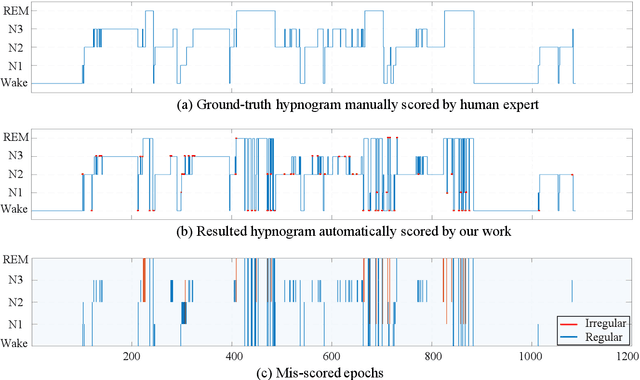

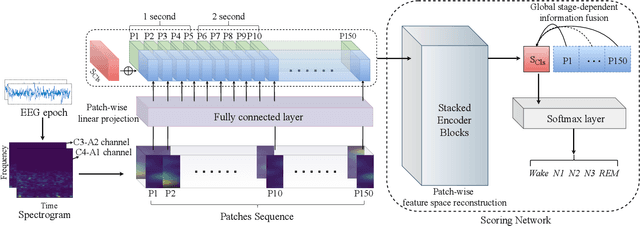
Considering the natural frequency characteristics in sleep medicine, this paper first proposes a time-frequency framework for the representation learning of the electroencephalogram (EEG) following the definition of the American Academy of Sleep Medicine. To meet the temporal-random and transient nature of the defining characteristics of sleep stages, we further design a context-sensitive flexible pipeline that automatically adapts to the attributes of data itself. That is, the input EEG spectrogram is partitioned into a sequence of patches in the time and frequency axes, and then input to a delicate deep learning network for further representation learning to extract the stage-dependent features, which are used in the classification step finally. The proposed pipeline is validated against a large database, i.e., the Sleep Heart Health Study (SHHS), and the results demonstrate that the competitive performance for the wake, N2, and N3 stages outperforms the state-of-art works, with the F1 scores being 0.93, 0.88, and 0.87, respectively, and the proposed method has a high inter-rater reliability of 0.80 kappa. Importantly, we visualize the stage scoring process of the model decision with the Layer-wise Relevance Propagation (LRP) method, which shows that the proposed pipeline is more sensitive and perceivable in the decision-making process than the baseline pipelines. Therefore, the pipeline together with the LRP method can provide better model interpretability, which is important for clinical support.
Cancer Subtyping via Embedded Unsupervised Learning on Transcriptomics Data
Apr 02, 2022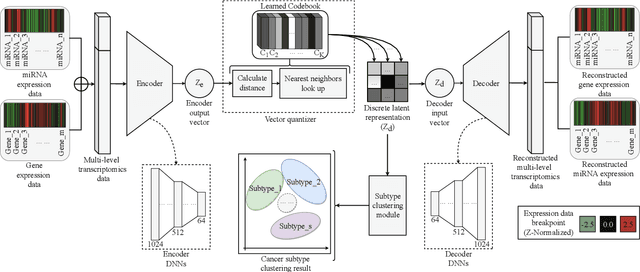
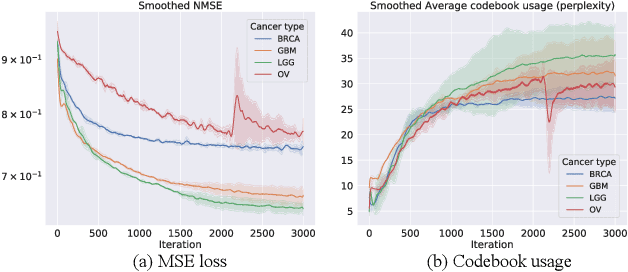
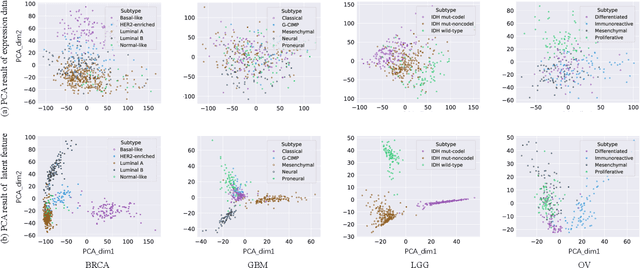

Cancer is one of the deadliest diseases worldwide. Accurate diagnosis and classification of cancer subtypes are indispensable for effective clinical treatment. Promising results on automatic cancer subtyping systems have been published recently with the emergence of various deep learning methods. However, such automatic systems often overfit the data due to the high dimensionality and scarcity. In this paper, we propose to investigate automatic subtyping from an unsupervised learning perspective by directly constructing the underlying data distribution itself, hence sufficient data can be generated to alleviate the issue of overfitting. Specifically, we bypass the strong Gaussianity assumption that typically exists but fails in the unsupervised learning subtyping literature due to small-sized samples by vector quantization. Our proposed method better captures the latent space features and models the cancer subtype manifestation on a molecular basis, as demonstrated by the extensive experimental results.