 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCancer Subtyping via Embedded Unsupervised Learning on Transcriptomics Data
Paper and Code
Apr 02, 2022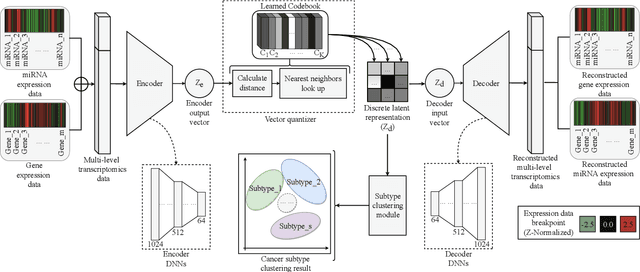
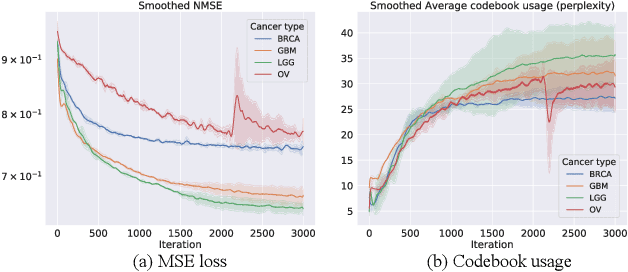
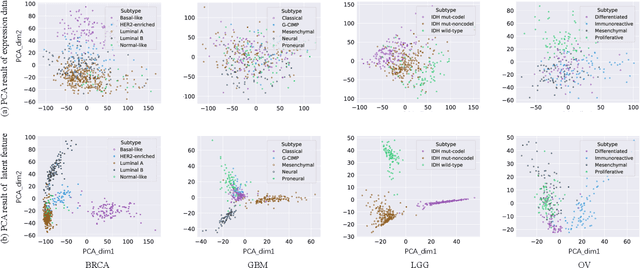

Cancer is one of the deadliest diseases worldwide. Accurate diagnosis and classification of cancer subtypes are indispensable for effective clinical treatment. Promising results on automatic cancer subtyping systems have been published recently with the emergence of various deep learning methods. However, such automatic systems often overfit the data due to the high dimensionality and scarcity. In this paper, we propose to investigate automatic subtyping from an unsupervised learning perspective by directly constructing the underlying data distribution itself, hence sufficient data can be generated to alleviate the issue of overfitting. Specifically, we bypass the strong Gaussianity assumption that typically exists but fails in the unsupervised learning subtyping literature due to small-sized samples by vector quantization. Our proposed method better captures the latent space features and models the cancer subtype manifestation on a molecular basis, as demonstrated by the extensive experimental results.