 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisinformation with Legal Consequences (MisLC): A New Task Towards Harnessing Societal Harm of Misinformation
Oct 04, 2024Misinformation, defined as false or inaccurate information, can result in significant societal harm when it is spread with malicious or even innocuous intent. The rapid online information exchange necessitates advanced detection mechanisms to mitigate misinformation-induced harm. Existing research, however, has predominantly focused on assessing veracity, overlooking the legal implications and social consequences of misinformation. In this work, we take a novel angle to consolidate the definition of misinformation detection using legal issues as a measurement of societal ramifications, aiming to bring interdisciplinary efforts to tackle misinformation and its consequence. We introduce a new task: Misinformation with Legal Consequence (MisLC), which leverages definitions from a wide range of legal domains covering 4 broader legal topics and 11 fine-grained legal issues, including hate speech, election laws, and privacy regulations. For this task, we advocate a two-step dataset curation approach that utilizes crowd-sourced checkworthiness and expert evaluations of misinformation. We provide insights about the MisLC task through empirical evidence, from the problem definition to experiments and expert involvement. While the latest large language models and retrieval-augmented generation are effective baselines for the task, we find they are still far from replicating expert performance.
Experimenting with Legal AI Solutions: The Case of Question-Answering for Access to Justice
Sep 12, 2024Generative AI models, such as the GPT and Llama series, have significant potential to assist laypeople in answering legal questions. However, little prior work focuses on the data sourcing, inference, and evaluation of these models in the context of laypersons. To this end, we propose a human-centric legal NLP pipeline, covering data sourcing, inference, and evaluation. We introduce and release a dataset, LegalQA, with real and specific legal questions spanning from employment law to criminal law, corresponding answers written by legal experts, and citations for each answer. We develop an automatic evaluation protocol for this dataset, then show that retrieval-augmented generation from only 850 citations in the train set can match or outperform internet-wide retrieval, despite containing 9 orders of magnitude less data. Finally, we propose future directions for open-sourced efforts, which fall behind closed-sourced models.
Evaluating AI for Law: Bridging the Gap with Open-Source Solutions
Apr 18, 2024



This study evaluates the performance of general-purpose AI, like ChatGPT, in legal question-answering tasks, highlighting significant risks to legal professionals and clients. It suggests leveraging foundational models enhanced by domain-specific knowledge to overcome these issues. The paper advocates for creating open-source legal AI systems to improve accuracy, transparency, and narrative diversity, addressing general AI's shortcomings in legal contexts.
Prototype-Based Interpretability for Legal Citation Prediction
May 25, 2023

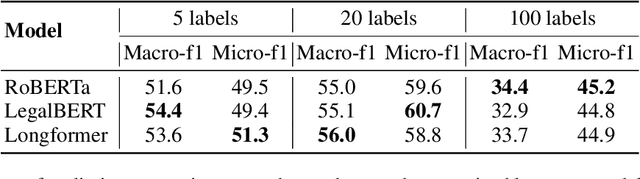
Deep learning has made significant progress in the past decade, and demonstrates potential to solve problems with extensive social impact. In high-stakes decision making areas such as law, experts often require interpretability for automatic systems to be utilized in practical settings. In this work, we attempt to address these requirements applied to the important problem of legal citation prediction (LCP). We design the task with parallels to the thought-process of lawyers, i.e., with reference to both precedents and legislative provisions. After initial experimental results, we refine the target citation predictions with the feedback of legal experts. Additionally, we introduce a prototype architecture to add interpretability, achieving strong performance while adhering to decision parameters used by lawyers. Our study builds on and leverages the state-of-the-art language processing models for law, while addressing vital considerations for high-stakes tasks with practical societal impact.
Towards Legally Enforceable Hate Speech Detection for Public Forums
May 23, 2023



Hate speech is a serious issue on public forums, and proper enforcement of hate speech laws is key for protecting groups of people against harmful and discriminatory language. However, determining what constitutes hate speech is a complex task that is highly open to subjective interpretations. Existing works do not align their systems with enforceable definitions of hate speech, which can make their outputs inconsistent with the goals of regulators. Our work introduces a new task for enforceable hate speech detection centred around legal definitions, and a dataset annotated on violations of eleven possible definitions by legal experts. Given the challenge of identifying clear, legally enforceable instances of hate speech, we augment the dataset with expert-generated samples and an automatically mined challenge set. We experiment with grounding the model decision in these definitions using zero-shot and few-shot prompting. We then report results on several large language models (LLMs). With this task definition, automatic hate speech detection can be more closely aligned to enforceable laws, and hence assist in more rigorous enforcement of legal protections against harmful speech in public forums.
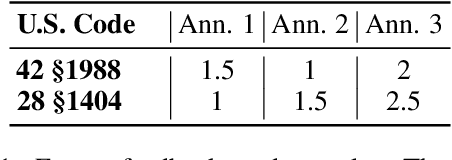
Interpretable Low-Resource Legal Decision Making
Jan 01, 2022

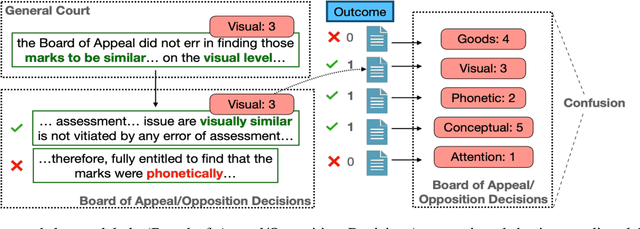
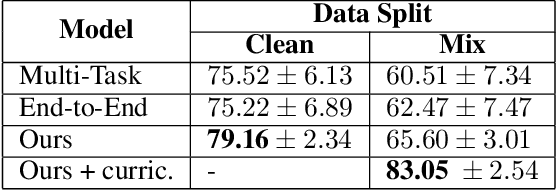
Over the past several years, legal applications of deep learning have been on the rise. However, as with other high-stakes decision making areas, the requirement for interpretability is of crucial importance. Current models utilized by legal practitioners are more of the conventional machine learning type, wherein they are inherently interpretable, yet unable to harness the performance capabilities of data-driven deep learning models. In this work, we utilize deep learning models in the area of trademark law to shed light on the issue of likelihood of confusion between trademarks. Specifically, we introduce a model-agnostic interpretable intermediate layer, a technique which proves to be effective for legal documents. Furthermore, we utilize weakly supervised learning by means of a curriculum learning strategy, effectively demonstrating the improved performance of a deep learning model. This is in contrast to the conventional models which are only able to utilize the limited number of expensive manually-annotated samples by legal experts. Although the methods presented in this work tackles the task of risk of confusion for trademarks, it is straightforward to extend them to other fields of law, or more generally, to other similar high-stakes application scenarios.