 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Active Learning (RoAL): Countering Dynamic Adversaries in Active Learning with Elastic Weight Consolidation
Aug 15, 2024
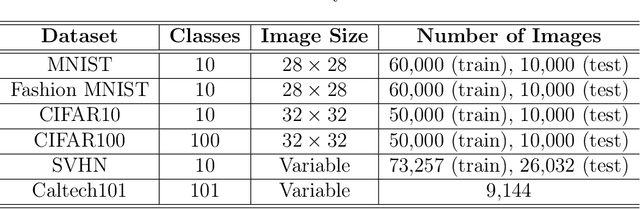

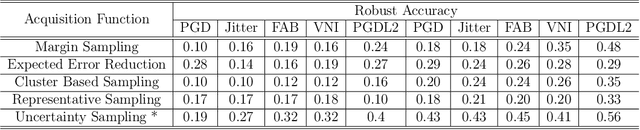
Despite significant advancements in active learning and adversarial attacks, the intersection of these two fields remains underexplored, particularly in developing robust active learning frameworks against dynamic adversarial threats. The challenge of developing robust active learning frameworks under dynamic adversarial attacks is critical, as these attacks can lead to catastrophic forgetting within the active learning cycle. This paper introduces Robust Active Learning (RoAL), a novel approach designed to address this issue by integrating Elastic Weight Consolidation (EWC) into the active learning process. Our contributions are threefold: First, we propose a new dynamic adversarial attack that poses significant threats to active learning frameworks. Second, we introduce a novel method that combines EWC with active learning to mitigate catastrophic forgetting caused by dynamic adversarial attacks. Finally, we conduct extensive experimental evaluations to demonstrate the efficacy of our approach. The results show that RoAL not only effectively counters dynamic adversarial threats but also significantly reduces the impact of catastrophic forgetting, thereby enhancing the robustness and performance of active learning systems in adversarial environments.
A Structural-Clustering Based Active Learning for Graph Neural Networks
Dec 07, 2023



In active learning for graph-structured data, Graph Neural Networks (GNNs) have shown effectiveness. However, a common challenge in these applications is the underutilization of crucial structural information. To address this problem, we propose the Structural-Clustering PageRank method for improved Active learning (SPA) specifically designed for graph-structured data. SPA integrates community detection using the SCAN algorithm with the PageRank scoring method for efficient and informative sample selection. SPA prioritizes nodes that are not only informative but also central in structure. Through extensive experiments, SPA demonstrates higher accuracy and macro-F1 score over existing methods across different annotation budgets and achieves significant reductions in query time. In addition, the proposed method only adds two hyperparameters, $\epsilon$ and $\mu$ in the algorithm to finely tune the balance between structural learning and node selection. This simplicity is a key advantage in active learning scenarios, where extensive hyperparameter tuning is often impractical.