 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Gesture-Based Visual Learning Model for Acoustophoretic Interactions using a Swarm of AcoustoBots
Apr 21, 2026AcoustoBots are mobile acoustophoretic robots capable of delivering mid-air haptics, directional audio, and acoustic levitation, but existing implementations rely on scripted commands and lack an intuitive interface for real-time human control. This work presents a gesture-based visual learning framework for contactless human-swarm interaction with a multimodal AcoustoBot platform. The system combines ESP32-CAM gesture capture, PhaseSpace motion tracking, centralized processing, and an OpenCLIP-based visual learning model (VLM) with linear probing to classify three hand gestures and map them to haptics, audio, and levitation modalities. Validation accuracy improved from about 67% with a small dataset to nearly 98% with the largest dataset. In integrated experiments with two AcoustoBots, the system achieved an overall gesture-to-modality switching accuracy of 87.8% across 90 trials, with an average end-to-end latency of 3.95 seconds. These results demonstrate the feasibility of using a vision-language-model-based gesture interface for multimodal human-swarm interaction. While the current system is limited by centralized processing, a static gesture set, and controlled-environment evaluation, it establishes a foundation for more expressive, scalable, and accessible swarm robotic interfaces.
AcoustoBots: A swarm of robots for acoustophoretic multimodal interactions
May 12, 2025Acoustophoresis has enabled novel interaction capabilities, such as levitation, volumetric displays, mid-air haptic feedback, and directional sound generation, to open new forms of multimodal interactions. However, its traditional implementation as a singular static unit limits its dynamic range and application versatility. This paper introduces AcoustoBots - a novel convergence of acoustophoresis with a movable and reconfigurable phased array of transducers for enhanced application versatility. We mount a phased array of transducers on a swarm of robots to harness the benefits of multiple mobile acoustophoretic units. This offers a more flexible and interactive platform that enables a swarm of acoustophoretic multimodal interactions. Our novel AcoustoBots design includes a hinge actuation system that controls the orientation of the mounted phased array of transducers to achieve high flexibility in a swarm of acoustophoretic multimodal interactions. In addition, we designed a BeadDispenserBot that can deliver particles to trapping locations, which automates the acoustic levitation interaction. These attributes allow AcoustoBots to independently work for a common cause and interchange between modalities, allowing for novel augmentations (e.g., a swarm of haptics, audio, and levitation) and bilateral interactions with users in an expanded interaction area. We detail our design considerations, challenges, and methodological approach to extend acoustophoretic central control in distributed settings. This work demonstrates a scalable acoustic control framework with two mobile robots, laying the groundwork for future deployment in larger robotic swarms. Finally, we characterize the performance of our AcoustoBots and explore the potential interactive scenarios they can enable.
Calendar Graph Neural Networks for Modeling Time Structures in Spatiotemporal User Behaviors
Jun 11, 2020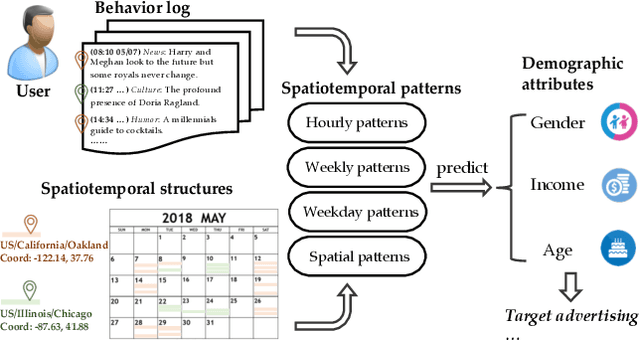
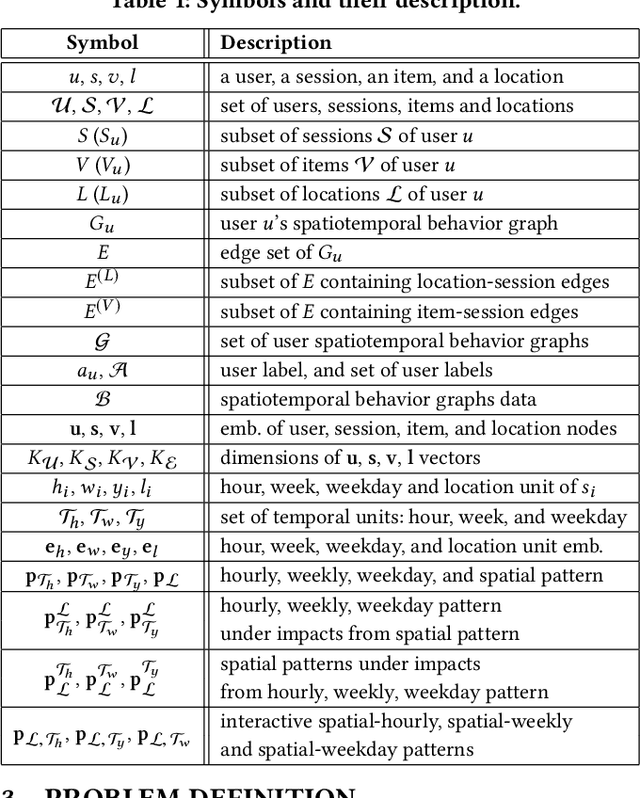
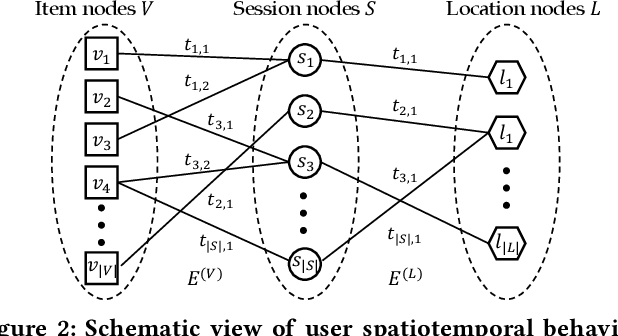
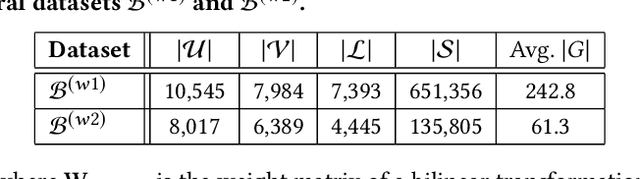
User behavior modeling is important for industrial applications such as demographic attribute prediction, content recommendation, and target advertising. Existing methods represent behavior log as a sequence of adopted items and find sequential patterns; however, concrete location and time information in the behavior log, reflecting dynamic and periodic patterns, joint with the spatial dimension, can be useful for modeling users and predicting their characteristics. In this work, we propose a novel model based on graph neural networks for learning user representations from spatiotemporal behavior data. A behavior log comprises a sequence of sessions; and a session has a location, start time, end time, and a sequence of adopted items. Our model's architecture incorporates two networked structures. One is a tripartite network of items, sessions, and locations. The other is a hierarchical calendar network of hour, week, and weekday nodes. It first aggregates embeddings of location and items into session embeddings via the tripartite network, and then generates user embeddings from the session embeddings via the calendar structure. The user embeddings preserve spatial patterns and temporal patterns of a variety of periodicity (e.g., hourly, weekly, and weekday patterns). It adopts the attention mechanism to model complex interactions among the multiple patterns in user behaviors. Experiments on real datasets (i.e., clicks on news articles in a mobile app) show our approach outperforms strong baselines for predicting missing demographic attributes.
MPP: Model Performance Predictor
Feb 22, 2019

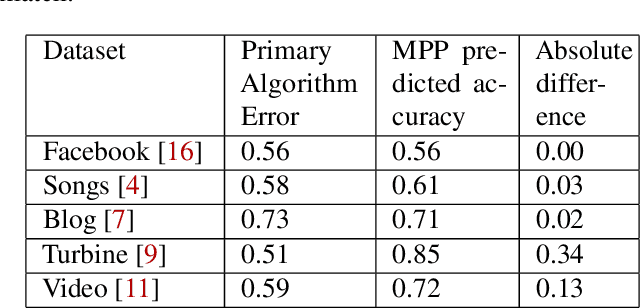
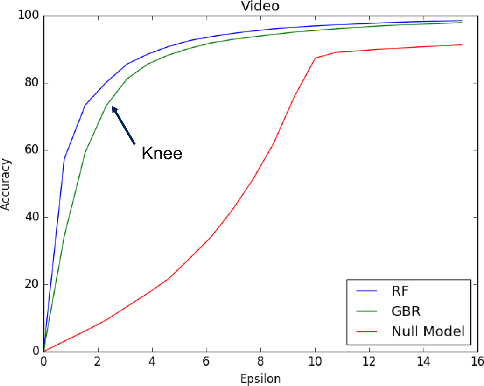
Operations is a key challenge in the domain of machine learning pipeline deployments involving monitoring and management of real-time prediction quality. Typically, metrics like accuracy, RMSE etc., are used to track the performance of models in deployment. However, these metrics cannot be calculated in production due to the absence of labels. We propose using an ML algorithm, Model Performance Predictor (MPP), to track the performance of the models in deployment. We argue that an ensemble of such metrics can be used to create a score representing the prediction quality in production. This in turn facilitates formulation and customization of ML alerts, that can be escalated by an operations team to the data science team. Such a score automates monitoring and enables ML deployments at scale.
ML Health: Fitness Tracking for Production Models
Feb 07, 2019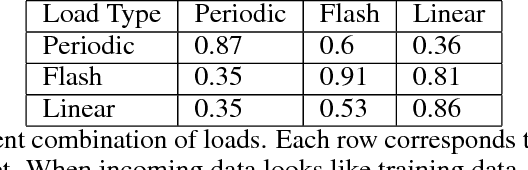
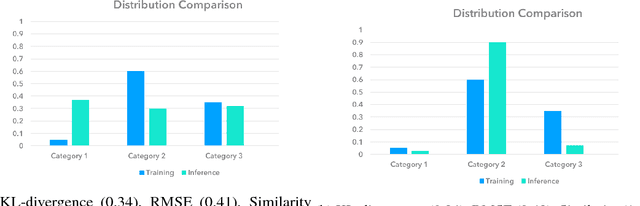

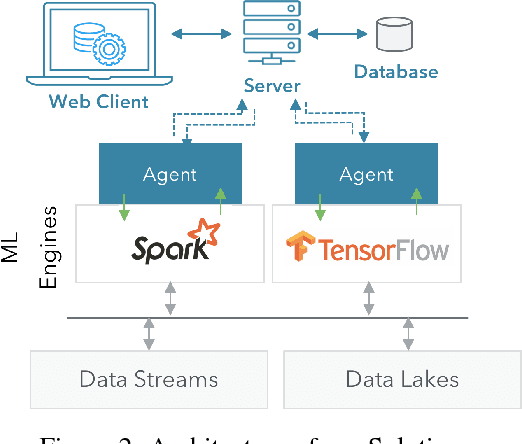
Deployment of machine learning (ML) algorithms in production for extended periods of time has uncovered new challenges such as monitoring and management of real-time prediction quality of a model in the absence of labels. However, such tracking is imperative to prevent catastrophic business outcomes resulting from incorrect predictions. The scale of these deployments makes manual monitoring prohibitive, making automated techniques to track and raise alerts imperative. We present a framework, ML Health, for tracking potential drops in the predictive performance of ML models in the absence of labels. The framework employs diagnostic methods to generate alerts for further investigation. We develop one such method to monitor potential problems when production data patterns do not match training data distributions. We demonstrate that our method performs better than standard "distance metrics", such as RMSE, KL-Divergence, and Wasserstein at detecting issues with mismatched data sets. Finally, we present a working system that incorporates the ML Health approach to monitor and manage ML deployments within a realistic full production ML lifecycle.