 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPP: Model Performance Predictor
Feb 22, 2019

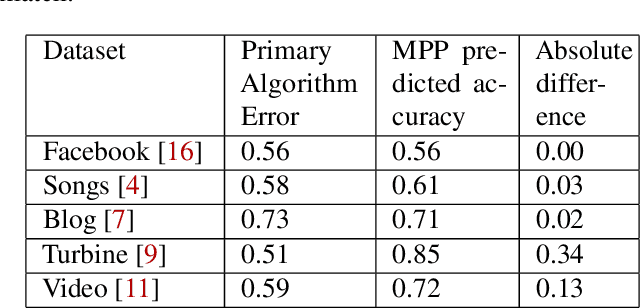
Operations is a key challenge in the domain of machine learning pipeline deployments involving monitoring and management of real-time prediction quality. Typically, metrics like accuracy, RMSE etc., are used to track the performance of models in deployment. However, these metrics cannot be calculated in production due to the absence of labels. We propose using an ML algorithm, Model Performance Predictor (MPP), to track the performance of the models in deployment. We argue that an ensemble of such metrics can be used to create a score representing the prediction quality in production. This in turn facilitates formulation and customization of ML alerts, that can be escalated by an operations team to the data science team. Such a score automates monitoring and enables ML deployments at scale.
ML Health: Fitness Tracking for Production Models
Feb 07, 2019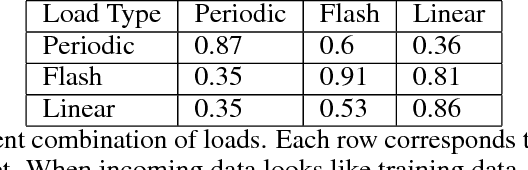
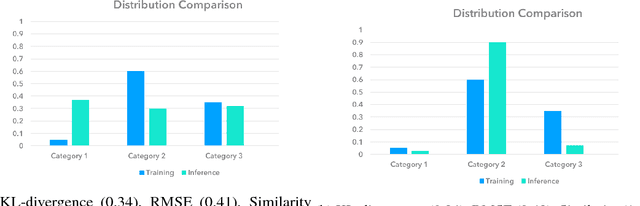

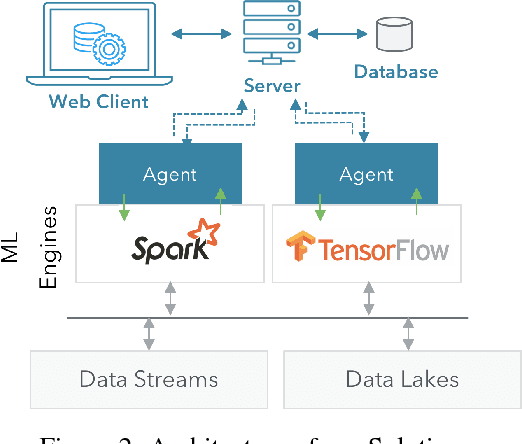
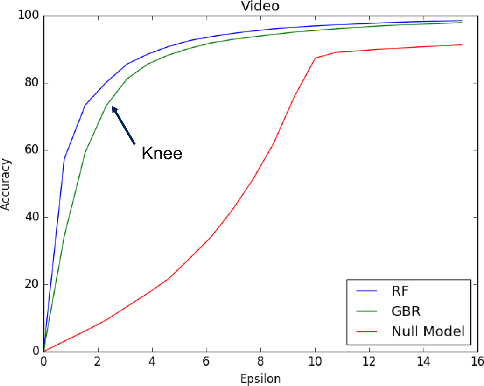
Deployment of machine learning (ML) algorithms in production for extended periods of time has uncovered new challenges such as monitoring and management of real-time prediction quality of a model in the absence of labels. However, such tracking is imperative to prevent catastrophic business outcomes resulting from incorrect predictions. The scale of these deployments makes manual monitoring prohibitive, making automated techniques to track and raise alerts imperative. We present a framework, ML Health, for tracking potential drops in the predictive performance of ML models in the absence of labels. The framework employs diagnostic methods to generate alerts for further investigation. We develop one such method to monitor potential problems when production data patterns do not match training data distributions. We demonstrate that our method performs better than standard "distance metrics", such as RMSE, KL-Divergence, and Wasserstein at detecting issues with mismatched data sets. Finally, we present a working system that incorporates the ML Health approach to monitor and manage ML deployments within a realistic full production ML lifecycle.