 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOLAR-Express: Efficient and Precise Formal Reachability Analysis of Neural-Network Controlled Systems
Apr 06, 2023



Neural networks (NNs) playing the role of controllers have demonstrated impressive empirical performances on challenging control problems. However, the potential adoption of NN controllers in real-life applications also gives rise to a growing concern over the safety of these neural-network controlled systems (NNCSs), especially when used in safety-critical applications. In this work, we present POLAR-Express, an efficient and precise formal reachability analysis tool for verifying the safety of NNCSs. POLAR-Express uses Taylor model arithmetic to propagate Taylor models (TMs) across a neural network layer-by-layer to compute an overapproximation of the neural-network function. It can be applied to analyze any feed-forward neural network with continuous activation functions. We also present a novel approach to propagate TMs more efficiently and precisely across ReLU activation functions. In addition, POLAR-Express provides parallel computation support for the layer-by-layer propagation of TMs, thus significantly improving the efficiency and scalability over its earlier prototype POLAR. Across the comparison with six other state-of-the-art tools on a diverse set of benchmarks, POLAR-Express achieves the best verification efficiency and tightness in the reachable set analysis.
POLAR: A Polynomial Arithmetic Framework for Verifying Neural-Network Controlled Systems
Jul 07, 2021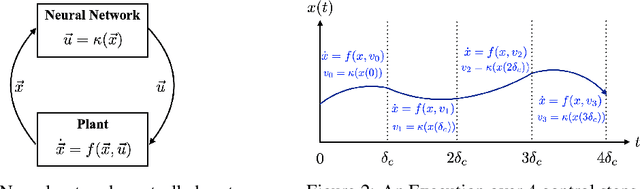
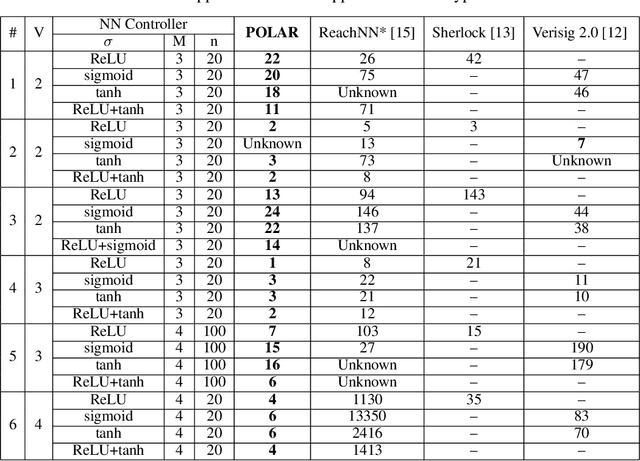
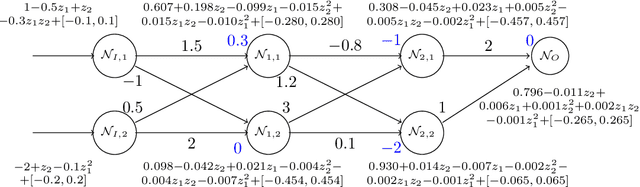
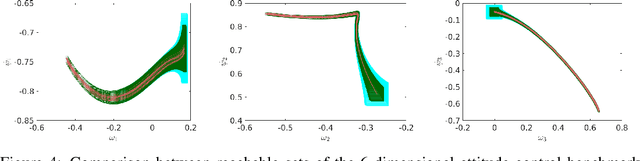
We propose POLAR, a \textbf{pol}ynomial \textbf{ar}ithmetic framework that leverages polynomial overapproximations with interval remainders for bounded-time reachability analysis of neural network-controlled systems (NNCSs). Compared with existing arithmetic approaches that use standard Taylor models, our framework uses a novel approach to iteratively overapproximate the neuron output ranges layer-by-layer with a combination of Bernstein polynomial interpolation for continuous activation functions and Taylor model arithmetic for the other operations. This approach can overcome the main drawback in the standard Taylor model arithmetic, i.e. its inability to handle functions that cannot be well approximated by Taylor polynomials, and significantly improve the accuracy and efficiency of reachable states computation for NNCSs. To further tighten the overapproximation, our method keeps the Taylor model remainders symbolic under the linear mappings when estimating the output range of a neural network. We show that POLAR can be seamlessly integrated with existing Taylor model flowpipe construction techniques, and demonstrate that POLAR significantly outperforms the current state-of-the-art techniques on a suite of benchmarks.
Robust Deep Reinforcement Learning via Multi-View Information Bottleneck
Feb 26, 2021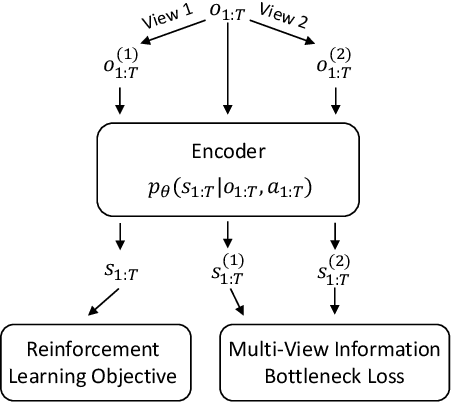
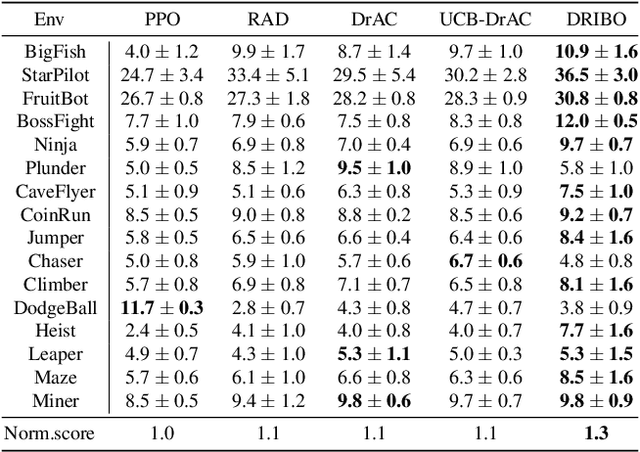

Deep reinforcement learning (DRL) agents are often sensitive to visual changes that were unseen in their training environments. To address this problem, we introduce a robust representation learning approach for RL. We introduce an auxiliary objective based on the multi-view information bottleneck (MIB) principle which encourages learning representations that are both predictive of the future and less sensitive to task-irrelevant distractions. This enables us to train high-performance policies that are robust to visual distractions and can generalize to unseen environments. We demonstrate that our approach can achieve SOTA performance on challenging visual control tasks, even when the background is replaced with natural videos. In addition, we show that our approach outperforms well-established baselines on generalization to unseen environments using the large-scale Procgen benchmark.
Adversarial Training and Provable Robustness: A Tale of Two Objectives
Aug 13, 2020
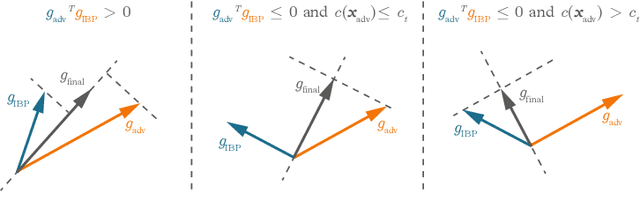
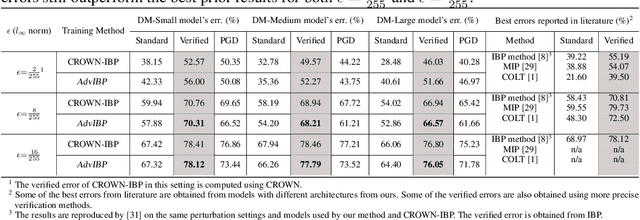
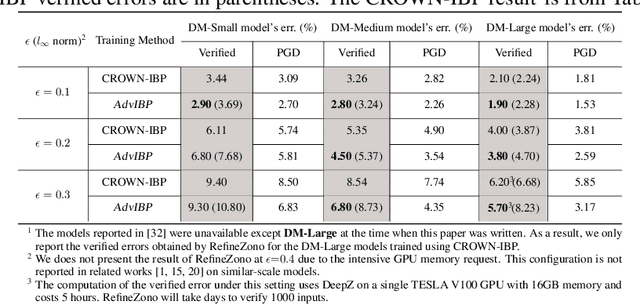
We propose a principled framework that combines adversarial training and provable robustness verification for training certifiably robust neural networks. We formulate the training problem as a joint optimization problem with both empirical and provable robustness objectives and develop a novel gradient-descent technique that can eliminate bias in stochastic multi-gradients. We perform both theoretical analysis on the convergence of the proposed technique and experimental comparison with state-of-the-arts. Results on MNIST and CIFAR-10 show that our method can match or outperform prior approaches for provable l infinity robustness.
ReachNN: Reachability Analysis of Neural-Network Controlled Systems
Jun 25, 2019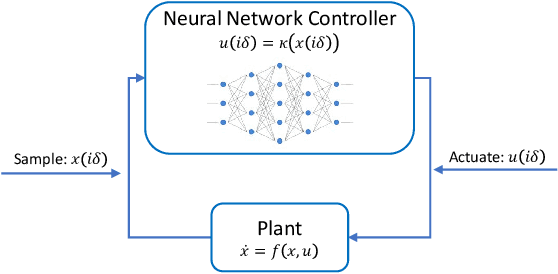
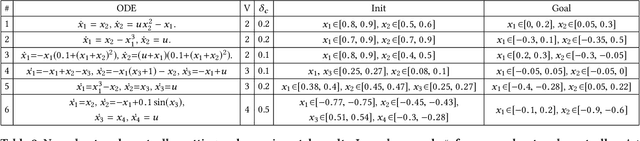
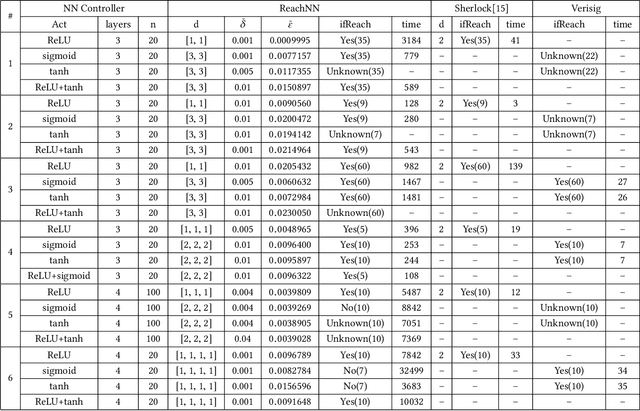
Applying neural networks as controllers in dynamical systems has shown great promises. However, it is critical yet challenging to verify the safety of such control systems with neural-network controllers in the loop. Previous methods for verifying neural network controlled systems are limited to a few specific activation functions. In this work, we propose a new reachability analysis approach based on Bernstein polynomials that can verify neural-network controlled systems with a more general form of activation functions, i.e., as long as they ensure that the neural networks are Lipschitz continuous. Specifically, we consider abstracting feedforward neural networks with Bernstein polynomials for a small subset of inputs. To quantify the error introduced by abstraction, we provide both theoretical error bound estimation based on the theory of Bernstein polynomials and more practical sampling based error bound estimation, following a tight Lipschitz constant estimation approach based on forward reachability analysis. Compared with previous methods, our approach addresses a much broader set of neural networks, including heterogeneous neural networks that contain multiple types of activation functions. Experiment results on a variety of benchmarks show the effectiveness of our approach.
Safety-Guided Deep Reinforcement Learning via Online Gaussian Process Estimation
Mar 06, 2019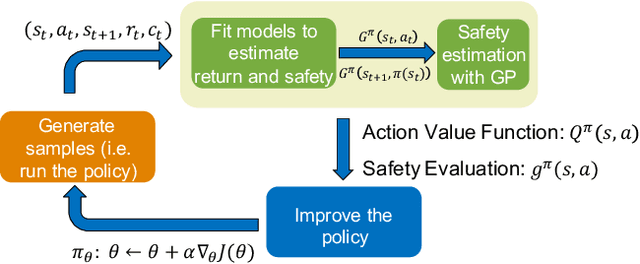
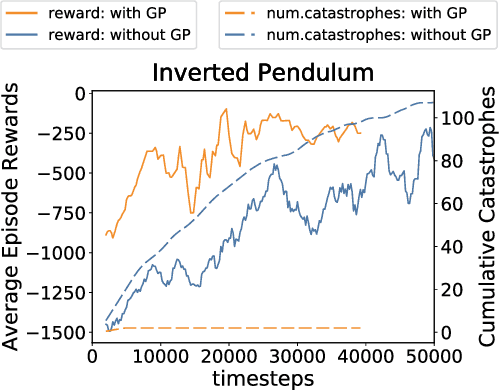
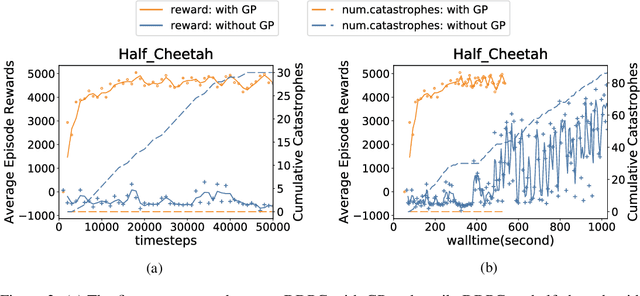
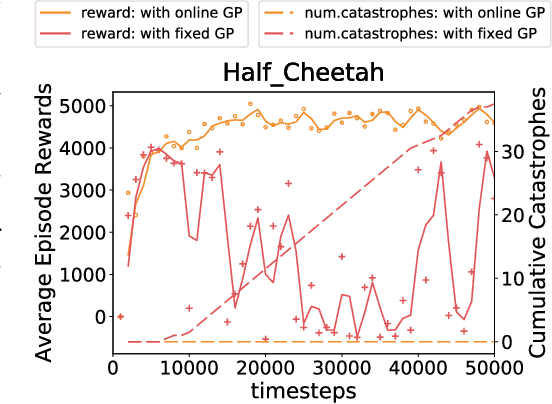
An important facet of reinforcement learning (RL) has to do with how the agent goes about exploring the environment. Traditional exploration strategies typically focus on efficiency and ignore safety. However, for practical applications, ensuring safety of the agent during exploration is crucial since performing an unsafe action or reaching an unsafe state could result in irreversible damage to the agent. The main challenge of safe exploration is that characterizing the unsafe states and actions is difficult for large continuous state or action spaces and unknown environments. In this paper, we propose a novel approach to incorporate estimations of safety to guide exploration and policy search in deep reinforcement learning. By using a cost function to capture trajectory-based safety, our key idea is to formulate the state-action value function of this safety cost as a candidate Lyapunov function and extend control-theoretic results to approximate its derivative using online Gaussian Process (GP) estimation. We show how to use these statistical models to guide the agent in unknown environments to obtain high-performance control policies with provable stability certificates.